Lineární Diskriminační Analýzy nebo Normální Diskriminační Analýzy nebo Diskriminační Funkční Analýzy je snížení počtu rozměrů technika, která se běžně používá pro dohlížené klasifikace problémy. Používá se pro modelování rozdílů ve skupinách, tj. oddělení dvou nebo více tříd. Používá se k promítání prvků v prostoru vyšší dimenze do prostoru nižší dimenze.
například máme dvě třídy a musíme je efektivně oddělit. Třídy mohou mít více funkcí. Použití pouze jedné funkce k jejich klasifikaci může mít za následek určité překrývání, jak je znázorněno na obrázku níže. Takže budeme pokračovat ve zvyšování počtu funkcí pro správnou klasifikaci.

Příklad:
Předpokládejme, že máme dvě sady datových bodů, které patří do dvou různých tříd, které chceme klasifikovat. Jak je znázorněno v daném 2D grafu, když jsou datové body vyneseny na rovině 2D, neexistuje žádná přímka, která by mohla úplně oddělit dvě třídy datových bodů. Proto se v tomto případě používá Lda (Lineární diskriminační analýza), která redukuje 2D graf na 1D graf, aby se maximalizovala oddělitelnost mezi oběma třídami.
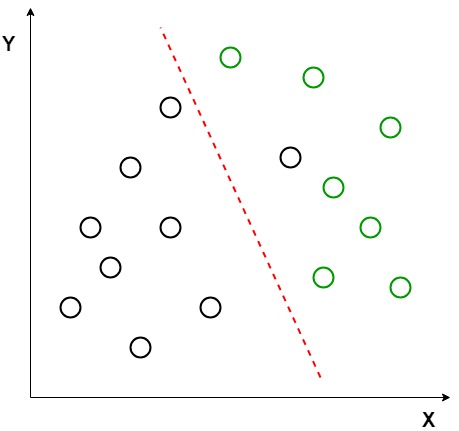
Tady, Lineární Diskriminační Analýza využívá obě osy (X a Y) k vytvoření nové osy a projekty data do nové osy tak, aby maximalizoval oddělení dvou kategorií, a proto, snížení 2D graf na 1D grafu.
Lda používá dvě kritéria pro vytvoření nové osy:
- maximalizujte vzdálenost mezi prostředky obou tříd.
- minimalizujte variace v každé třídě.
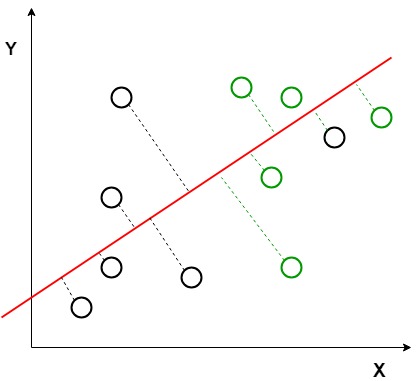
Ve výše uvedeném grafu, lze vidět, že nová osa (červeně) je generován a vykresleny do 2D grafu takové, že maximalizuje vzdálenost mezi prostředky obou tříd a minimalizuje variace uvnitř jednotlivých tříd. Jednoduše řečeno, tato nově vytvořená osa zvyšuje oddělení mezi body dtla obou tříd. Po vygenerování této nové osy pomocí výše uvedených kritérií jsou všechny datové body tříd vyneseny na tuto novou osu a jsou znázorněny na obrázku uvedeném níže.

Ale Lineární Diskriminační Analýzy selže při střední distribuce jsou sdíleny, jak to stane se nemožné pro LDA najít nové osy, které dělá obě třídy lineárně separovatelné. V takových případech používáme nelineární diskriminační analýzu.
rozšíření na LDA:
- kvadratická diskriminační analýza (QDA): Každá třída používá svůj vlastní odhad rozptylu (nebo kovariance, pokud existuje více vstupních proměnných).
- flexibilní diskriminační analýza (FDA): kde se používají nelineární kombinace vstupů, jako jsou spline.
- Legalizovány Diskriminační Analýzy (RDA): Zavádí regulaci do odhadu rozptylu (kovariance), moderování vliv různých proměnných na LDA.
aplikace:
- rozpoznávání obličeje: V oblasti počítačového vidění je rozpoznávání obličeje velmi populární aplikací, ve které je každá tvář reprezentována velmi velkým počtem hodnot pixelů. Lineární diskriminační analýza (LDA) se zde používá ke snížení počtu prvků na lépe zvládnutelné číslo před procesem klasifikace. Každá z nových generovaných dimenzí je lineární kombinací hodnot pixelů, které tvoří šablonu. Lineární kombinace získané pomocí Fisherova lineárního diskriminantu se nazývají Fisherovy tváře.
- lékařské: V této oblasti, Lineární diskriminační analýza (LDA) se používá pro klasifikaci pacienta, stavu onemocnění, jako mírnou, střední nebo těžkou založené na pacienta různými parametry a léčba, kterou prochází. To pomáhá lékařům zintenzivnit nebo snížit tempo jejich léčby.
- identifikace zákazníka: Předpokládejme, že chceme identifikovat typ zákazníků, kteří si s největší pravděpodobností koupí konkrétní produkt v nákupním středisku. Provedením jednoduchého průzkumu otázek a odpovědí můžeme shromáždit všechny funkce zákazníků. Zde nám Lineární diskriminační analýza pomůže identifikovat a vybrat funkce, které mohou popsat vlastnosti skupiny zákazníků, kteří s největší pravděpodobností koupí tento konkrétní produkt v nákupním středisku.
