Ahoj a vítejte Ilustrovaný Průvodce Dlouhý Krátkodobé Paměti (LSTM) a Bránou Opakujících se Jednotek (GRU). Jsem Michael A jsem inženýr strojového učení v prostoru hlasového asistenta AI.
v tomto příspěvku začneme intuicí za LSTM a GRU. pak vysvětlím vnitřní mechanismy, které umožňují LSTM a GRU fungovat tak dobře. Pokud chcete pochopit, co se děje pod kapotou pro tyto dvě sítě, pak je tento příspěvek pro vás.
můžete také sledovat video verzi tohoto příspěvku na youtube, pokud chcete.
opakující se neuronové sítě trpí krátkodobou pamětí. Pokud je sekvence dostatečně dlouhá, budou mít potíže s přenosem informací od dřívějších časových kroků k pozdějším. Takže pokud se snažíte zpracovat odstavec textu dělat předpovědi, RNN může vynechat důležité informace od začátku.
během zpětného šíření trpí opakující se neuronové sítě problémem mizejícího gradientu. Gradienty jsou hodnoty používané k aktualizaci váhy neuronových sítí. Problém mizejícího gradientu je, když se gradient zmenšuje, jak se zpět šíří časem. Pokud se hodnota gradientu stane extrémně malou, nepřispívá příliš mnoho učení.

Takže v rekurentních neuronových sítí, vrstvy, které si malý gradient aktualizace se zastaví učení. To jsou obvykle starší vrstvy. Takže protože se tyto vrstvy nenaučí, RNN mohou zapomenout na to, co viděly v delších sekvencích, a tak mají krátkodobou paměť. Pokud se chcete dozvědět více o Mechanice rekurentních neuronových sítí obecně, můžete si přečíst můj předchozí příspěvek zde.
lstm a GRU jako řešení
lstm a GRU byly vytvořeny jako řešení krátkodobé paměti. Mají vnitřní mechanismy nazývané brány, které mohou regulovat tok informací.

Tyto brány mohou naučit, které údaje v řadě je důležité mít, nebo zahodit. Tím, že, může předat relevantní informace dolů dlouhý řetězec sekvencí, aby se předpovědi. Téměř všechny nejmodernější výsledky založené na opakujících se neuronových sítích jsou dosaženy s těmito dvěma sítěmi. Lstm a GRU lze nalézt v rozpoznávání řeči, syntéze řeči a generování textu. Můžete je dokonce použít k vytváření titulků pro videa.
Ok, takže na konci tohoto příspěvku byste měli mít solidní pochopení toho, proč jsou lstm a GRU dobré při zpracování dlouhých sekvencí. Budu k tomu přistupovat intuitivním vysvětlením a ilustracemi a vyhnout se co nejvíce matematice.
intuice
Ok, začněme myšlenkovým experimentem. Řekněme, že se díváte na recenze online, abyste zjistili, zda si chcete koupit Life cereal (neptejte se mě proč). Nejprve si přečtete recenzi a poté zjistíte, zda si někdo myslel, že je to dobré nebo špatné.

Když si přečtete recenze, váš mozek podvědomě si pamatuje pouze důležitá klíčová slova. Vybíráte slova jako “ úžasná „a“ dokonale vyvážená snídaně“. Nestaráte se o slova jako „toto“, „dal“, „vše“, “ měl “ atd. Pokud se vás přítel druhý den zeptá, co recenze řekla, pravděpodobně byste si to nepamatovali slovo od slova. Možná si pamatujete hlavní body, i když jako „určitě bude kupovat znovu“. Pokud jste hodně jako já, ostatní slova zmizí z paměti.

A to je v podstatě to, co LSTM nebo GRU. Může se naučit uchovávat pouze relevantní informace, aby předpovídal, a zapomenout na nerelevantní data. V tomto případě vás slova, která jste si pamatovali, přiměla posoudit, že je to dobré.
přehled rekurentních neuronových sítí
abychom pochopili, jak toho LSTM nebo GRU dosahuje, podívejme se na rekurentní neuronovou síť. RNN funguje takto; první slova se transformují do strojově čitelných vektorů. Pak RNN zpracovává sekvenci vektorů jeden po druhém.

Při zpracování, to projde předchozí skryté státu, aby další krok sekvence. Skrytý stav funguje jako paměť neuronových sítí. Obsahuje informace o předchozích datech, které síť viděla dříve.

Pojďme se podívat na buňky RNN vidět, jak budete počítat skryté státu. Nejprve se vstupní a předchozí skrytý stav spojí a vytvoří vektor. Tento vektor má nyní informace o aktuálním vstupu a předchozích vstupech. Vektor prochází aktivací tanh a výstupem je nový skrytý stav nebo paměť sítě.

Tanh aktivace
tanh aktivace se používá k regulaci hodnoty teče přes síť. Funkce tanh stlačuje hodnoty vždy mezi -1 a 1.

Když vektory jsou protékající neuronové sítě, prochází mnoha proměnami v důsledku různých matematických operací. Představte si tedy hodnotu, která se stále násobí řekněme 3. Můžete vidět, jak některé hodnoty mohou explodovat a stát se astronomickými, což způsobuje, že jiné hodnoty se zdají nevýznamné.

tanh funkce zajišťuje, že hodnoty mezi -1 a 1, čímž se regulační výstup z neuronové sítě. Můžete vidět, jak stejné hodnoty shora zůstávají mezi hranicemi povolenými funkcí tanh.

Takže to je RNN. Má velmi málo operací interně, ale funguje docela dobře za správných okolností (jako krátké sekvence). RNN používá mnohem méně výpočetních prostředků než vyvinuté varianty, LSTM a GRU.
LSTM
Lstm má podobný řídicí tok jako rekurentní neuronová síť. Zpracovává data předávající informace, jak se šíří vpřed. Rozdíly jsou operace uvnitř buněk LSTM.

Tyto operace jsou používány k tomu, aby LSTM udržet nebo zapomenout, informace. Nyní se podíváme na tyto operace může být trochu ohromující, takže budeme jít přes tento krok za krokem.
základní koncept
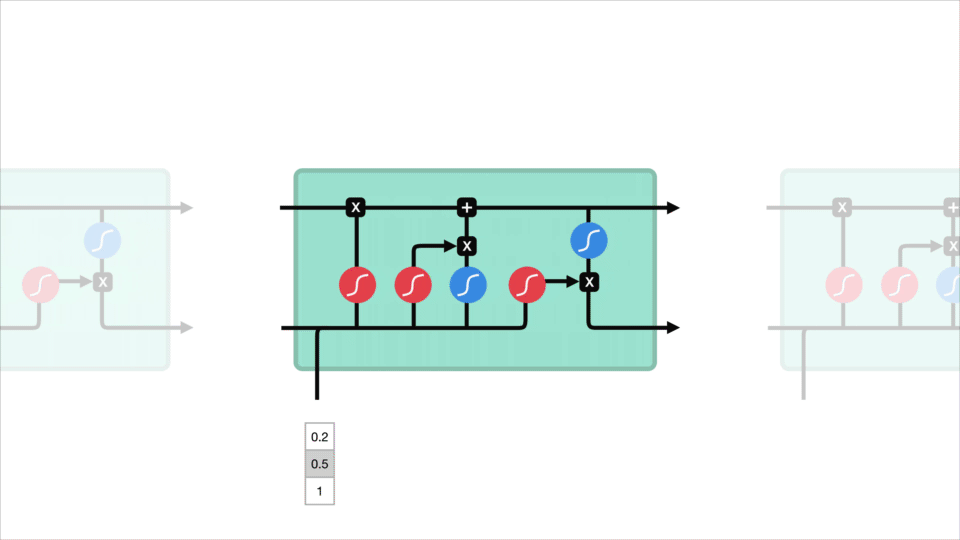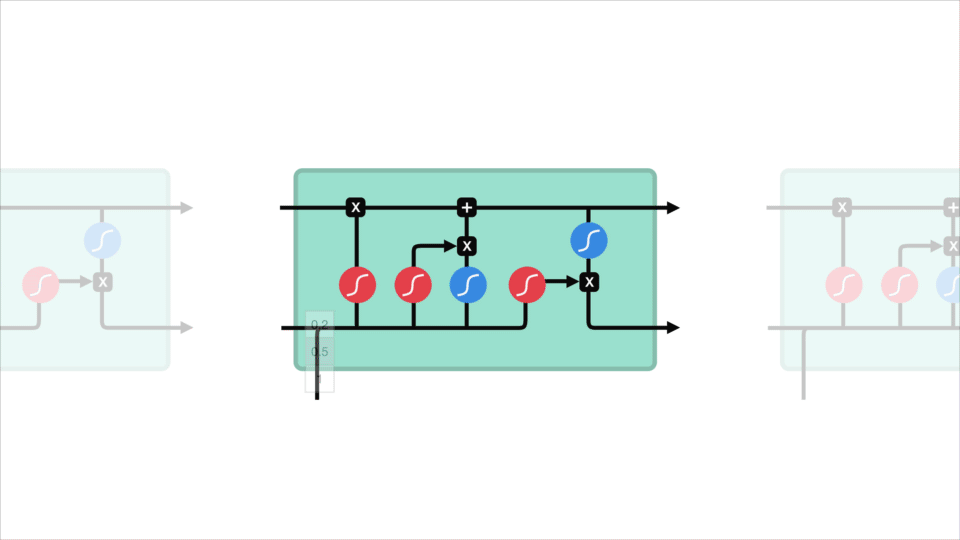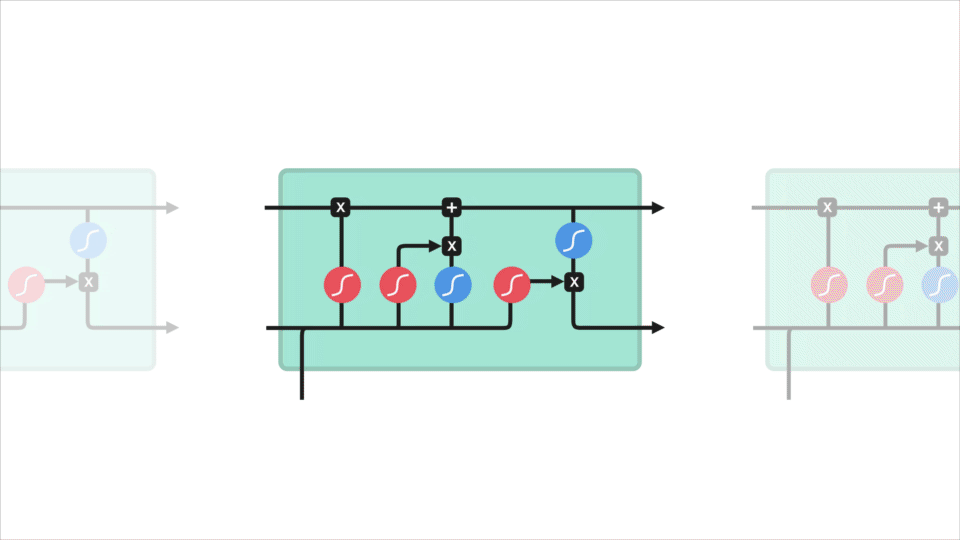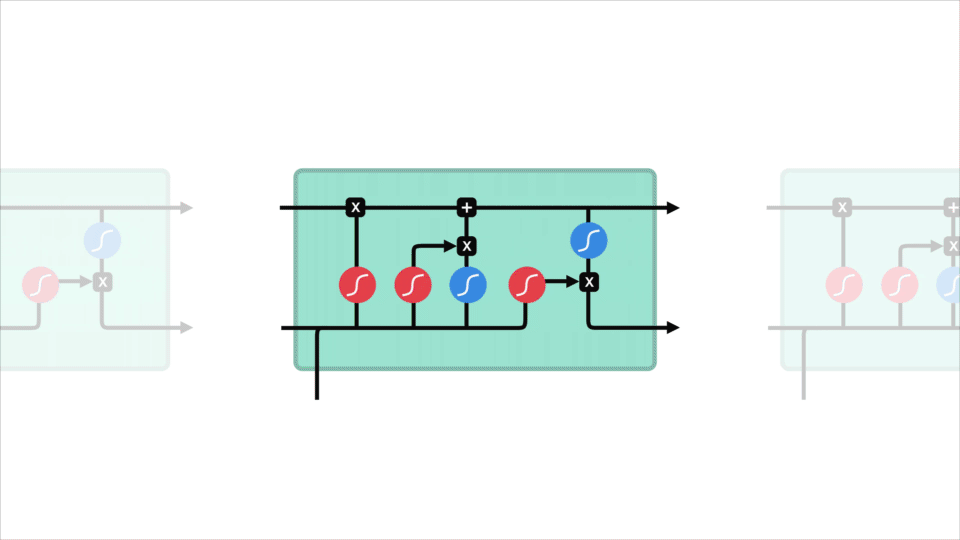
základní koncept LSTM je stav buňky a jsou to různé brány. Stav buňky působí jako dopravní dálnice, která přenáší relativní informace až po sekvenční řetězec. Můžete si to představit jako „paměť“ sítě. Stav buňky může teoreticky přenášet relevantní informace během zpracování sekvence. Takže i informace z dřívějších časových kroků mohou vést k pozdějším časovým krokům, což snižuje účinky krátkodobé paměti. Jak stav buňky pokračuje na své cestě, informace se přidávají nebo odstraňují do stavu buňky pomocí bran. Brány jsou různé neuronové sítě, které rozhodují, které informace jsou povoleny o stavu buňky. Brány se mohou dozvědět, jaké informace jsou důležité pro udržení nebo zapomenutí během tréninku.
Sigmoid
Gates obsahuje sigmoidní aktivace. Sigmoidní aktivace je podobná aktivaci tanh. Místo toho, aby squishing hodnoty mezi -1 a 1, to squishes hodnoty mezi 0 a 1. To je užitečné pro aktualizaci nebo zapomenutí dat, protože jakékoli číslo vynásobené 0 je 0, což způsobí, že hodnoty zmizí nebo budou „zapomenuty“.“Jakékoli číslo vynásobené 1 je stejná hodnota, proto je tato hodnota stejná nebo je“ zachována.“Síť se může dozvědět, která data nejsou důležitá, a proto mohou být zapomenuta nebo která data je důležité uchovávat.

Pojďme kopat trochu hlouběji do toho, co různé brány dělají, budeme? Máme tedy tři různé brány, které regulují tok informací v lstm buňce. Zapomenutá brána, vstupní brána a výstupní brána.
Forget gate
nejprve máme forget gate. Tato brána rozhoduje o tom, jaké informace by měly být vyhozeny nebo uchovávány. Informace z předchozího skrytého stavu a informace z aktuálního vstupu jsou předávány sigmoidní funkcí. Hodnoty vycházejí mezi 0 a 1. Čím blíže k 0 znamená zapomenout a čím blíže k 1 znamená udržet.

Vstupní Brána
aktualizovat mobilní státu, máme vstupní bránu. Nejprve předáme předchozí skrytý stav a aktuální vstup do sigmoidní funkce. To rozhoduje, které hodnoty budou aktualizovány transformací hodnot mezi 0 a 1. 0 znamená, že není důležité, a 1 znamená důležité. Také předáte skrytý stav a aktuální vstup do funkce tanh, abyste stlačili hodnoty mezi -1 a 1, abyste pomohli regulovat síť. Potom vynásobíte výstup tanh sigmoidním výstupem. Sigmoidní výstup rozhodne, které informace je důležité zachovat z výstupu tanh.

Mobilní Státu
Nyní bychom měli mít dostatek informací k výpočtu buňku státu. Nejprve se stav buňky bodově vynásobí vektorem zapomnění. To má možnost poklesu hodnot ve stavu buňky, pokud se vynásobí hodnotami blízkými 0. Pak jsme si výstup ze vstupní brány a bodově navíc, který aktualizuje mobilní státu, aby nové hodnoty, že neuronové sítě najde relevantní. To nám dává náš nový stav buněk.

Výstupní Brána
Poslední máme výstupní brány. Výstupní brána rozhoduje, jaký by měl být další skrytý stav. Nezapomeňte, že skrytý stav obsahuje informace o předchozích vstupech. Skrytý stav se také používá pro předpovědi. Nejprve předáme předchozí skrytý stav a aktuální vstup do sigmoidní funkce. Poté nově upravený stav buňky předáme funkci tanh. Výstup tanh vynásobíme sigmoidním výstupem, abychom rozhodli, jaké informace má skrytý stav nést. Výstupem je skrytý stav. Nový stav buňky a Nový skrytý je pak přenesen do dalšího časového kroku.

K recenzi, Zapomenout na brány rozhoduje, co je relevantní, aby se z předchozí kroky. Vstupní brána rozhoduje, jaké informace je důležité přidat z aktuálního kroku. Výstupní brána určuje, jaký by měl být další skrytý stav.
Demo kódu
pro ty z vás, kteří lépe rozumějí tím, že vidí kód, zde je příklad použití pseudo kódu Pythonu.

1. Nejprve se předchozí skrytý stav a aktuální vstup zřetězí. Budeme tomu říkat combine.
2. Kombinovat get je přiváděn do zapomenout vrstvy. Tato vrstva odstraňuje nerelevantní data.
4. Kandidátská vrstva je vytvořena pomocí kombinace. Kandidát má možné hodnoty pro přidání do stavu buňky.
3. Kombinovat také dostat se přivádí do vstupní vrstvy. Tato vrstva rozhoduje, jaká data z kandidáta by měla být přidána do nového stavu buňky.
5. Po výpočtu zapomenuté vrstvy, kandidátské vrstvy a vstupní vrstvy se stav buňky vypočítá pomocí těchto vektorů a předchozího stavu buňky.
6. Výstup se pak vypočítá.
7. Bodové vynásobení výstupu a nového stavu buňky nám dává nový skrytý stav.
to je ono! Řídicí tok sítě LSTM je několik tenzorových operací a smyčka a pro. Skryté stavy můžete použít pro předpovědi. Kombinací všech těchto mechanismů si LSTM může vybrat, které informace jsou důležité pro zapamatování nebo zapomenutí během zpracování sekvence.
GRU
takže teď víme, jak funguje LSTM, podívejme se krátce na GRU. GRU je novější generace rekurentních neuronových sítí a je velmi podobná LSTM. GRU se zbavila stavu buněk a použila skrytý stav k přenosu informací. Má také pouze dvě brány, resetovací bránu a aktualizační bránu.

Aktualizace Vrata
aktualizace brány akty podobné zapomenout a vstupní brány z LSTM. Rozhoduje, jaké informace zahodit a jaké nové informace Přidat.
Reset Gate
reset gate je další brána, která se používá k rozhodnutí, kolik minulých informací zapomenout.
a to je GRU. GRU má méně tenzorových operací; proto, oni jsou trochu rychlejší, aby vlak pak LSTM. Tam není jasný vítěz, který z nich je lepší. Vědci a inženýři se obvykle snaží zjistit, který z nich funguje lépe pro jejich případ použití.
to je to
tento součet se, RNN jsou dobré pro zpracování sekvence dat pro předpovědi, ale trpí krátkodobou paměť. Lstm a GRU byly vytvořeny jako metoda ke zmírnění krátkodobé paměti pomocí mechanismů zvaných gates. Brány jsou jen neuronové sítě, které regulují tok informací protékajících sekvenčním řetězcem. Lstm a GRU se používají v nejmodernějších aplikacích hlubokého učení, jako je rozpoznávání řeči, syntéza řeči,porozumění přirozenému jazyku atd.
Pokud vás zajímá hlouběji, zde jsou odkazy na některé fantastické zdroje, které vám mohou poskytnout jiný pohled na chápání LSTM a GRU. Tento příspěvek byl silně inspirován.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/