můžete snadno použít kategorické proměnné jako prediktory v lineární regresi: musíte je rozdělit na dichotomické proměnné známý jako dummy proměnné.
ideální způsob, jak je vytvořit, je náš nástroj pro fiktivní proměnné. Pokud tento nástroj nechcete používat, pak tento tutoriál ukazuje správný způsob, jak to udělat ručně.
- Příklad, který jsem – Jakákoliv Číselná Proměnná.
- Příklad II – Číselné Proměnné s Přilehlými Celá čísla
- Příklad III – Řetězcové Proměnné s Konverzí
- Příklad IV – String Proměnné bez Konverze
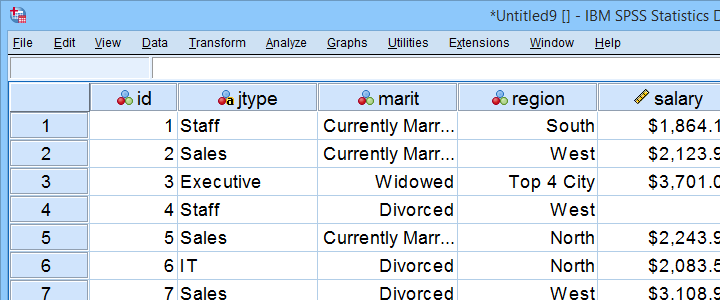
Příklad Datového Souboru
Tento výukový program používá personál.sav celé. Část tohoto datového souboru je uvedena níže.
Příklad, který jsem – Jakákoliv Číselná Proměnná.
Pojďme se nejprve vytvořit dummy proměnné pro marit, krátký pro manželský stav. Naším prvním krokem je spuštění základní tabulky KMITOČTŮFREKVENCE marit.Níže uvedená tabulka ukazuje výslednou tabulku.
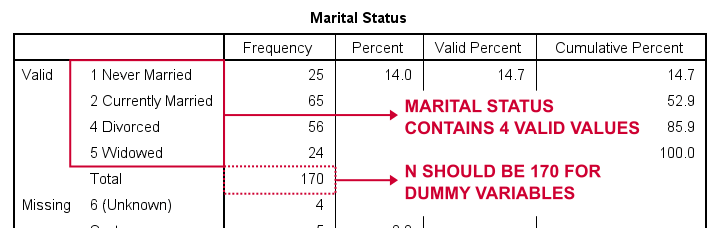
Jak rozdělit rodinný stav na fiktivní proměnné? Nejprve vždy vynecháme jednu kategorii, referenční kategorii. Jako referenční kategorii si můžete vybrat libovolnou kategorii.
takže pro tento příklad zvolíme 5 (Ovdovělý). To znamená, že vytvoříme 3 fiktivní proměnné představující kategorie 1, 2 a 4 (všimněte si, že 3 se v této proměnné nevyskytují).
syntaxe níže ukazuje, jak vytvořit a označit naše 3 fiktivní proměnné. Projedeme to.
vypočítat marit_1 = (marit = 1).
vypočítat marit_2 = (marit = 2).
vypočítat marit_4 = (marit = 4).
* použijte štítky proměnných na fiktivní proměnné.
variabilní štítky
marit_1 ‚Rodinný Stav = Nikdy Ženatý‘
marit_2 ‚Rodinný Stav = v Současné době Ženatý,‘
marit_4 ‚Rodinný Stav = Rozvedený‘.
* Rychlá kontrola první fiktivní proměnné
frekvence marit_1.
výsledky
nejprve si všimněte, že jsme v našem aktivním datovém souboru vytvořili 3 pěkně označené fiktivní proměnné.
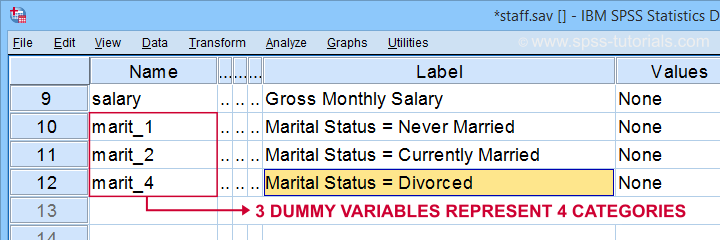
níže uvedená tabulka ukazuje rozdělení frekvence pro naši první fiktivní proměnnou.

Všimněte si, že naše dummy proměnná obsahuje 3 různé hodnoty:
- respondenti, jejichž rodinný stav není „nikdy ženatý“ skóre 0;
- respondenti, jejichž rodinný stav je „nikdy ženatý“ skóre 1;
- respondenti, jejichž rodinný stav je chybějící hodnota (a tedy neznámé) mít systém, chybějící hodnota.
nyní můžeme zkontrolovat výsledky důkladněji spuštěním crosstabs marit od marit_1 do marit_4.Tím se vytvoří 3 pohotovostní tabulky, z nichž první je uvedena níže.
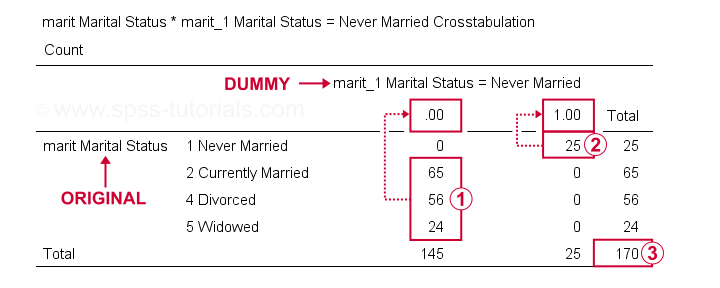
Na našich dummy proměnné, respondenti mají jiné manželské stavy než „se nikdy neoženil,“ všechny skóre 0;
respondenti mají jiné manželské stavy než „se nikdy neoženil,“ všechny skóre 0; respondenti, kteří „se nikdy neoženil,“ všechny skóre 1;
respondenti, kteří „se nikdy neoženil,“ všechny skóre 1; máme velikost vzorku N = 170 (tato tabulka zahrnuje pouze respondenty bez chybějících hodnot na jedné z proměnných).
máme velikost vzorku N = 170 (tato tabulka zahrnuje pouze respondenty bez chybějících hodnot na jedné z proměnných).
volitelně je závěrečná-velmi důkladná-kontrola Porovnat výsledky ANOVA pro původní proměnnou s výsledky regrese pomocí našich fiktivních proměnných. Níže uvedená syntaxe to dělá, pomocí měsíční mzdy jako závislé proměnné.
regrese
/ závislý plat
/ metoda zadejte marit_1 do marit_4.
* minimální ANOVA pomocí původní proměnné.
oneway plat od marit.
Všimněte si, že obě analýzy výsledku v identických ANOVA tabulky. Budeme diskutovat ANOVA versus fiktivní variabilní regrese důkladněji v budoucím tutoriálu.
příklad II-Číselná proměnná se sousedními celými čísly
nyní vytvoříme fiktivní proměnné pro oblast. Opět začneme tím, že zkontrolujeme minimální frekvenční tabulku, kterou vytvoříme regionem runningfrequencies.Vyplývá to z níže uvedené tabulky.
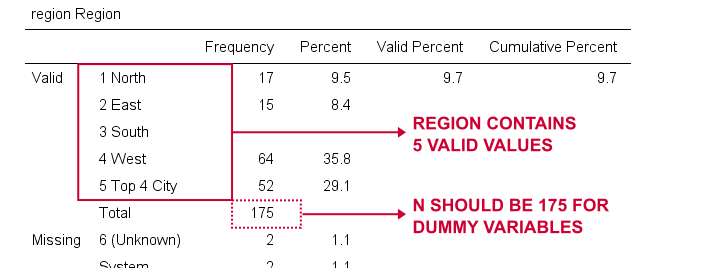
jako referenční kategorii vybereme 1 („Sever“). Vytvoříme proto fiktivní proměnné pro kategorie 2 až 5. Protože se jedná o sousední celá čísla, můžeme věci urychlit pomocí opakování, jak je uvedeno níže.
opakujte #vals = 2 až 5 / #vars = region_2 až region_5.
překódujte oblast (#vals = 1) (lo thru hi = 0) do #vars.
konec opakovaného tisku.
* použijte štítky proměnných na nové proměnné.
proměnné štítky
region_2 ‚Region = East‘
region_3 ‚Region = South‘
region_4 ‚Region = West‘
region_5 ‚Region = Top 4 City‘.
* Rychlá kontrola.
crosstabs region podle region_2 na region_5.
pečlivá kontrola výsledných tabulek potvrzuje, že všechny výsledky jsou správné.
příklad III – řetězcová proměnná s konverzí
bohužel naše první 2 metody nefungují pro řetězcové proměnné, jako je jtype-zkratka pro „typ úlohy“). Nejjednodušším řešením je převést ji na číselnou proměnnou, jak je popsáno v SPSS převést řetězec na číselnou proměnnou. Syntaxe níže používá k dokončení úlohy AUTORECODE.
autorecode jtype
/do njtype.
* zkontrolujte výsledek.
frekvence njtype.
* nastavení chybějících hodnot.
chybí hodnoty njtype (1,2).
* překontrolovat výsledek.
frekvence njtype.
Výsledek

Od njtype -zkratka pro „číselný typ úlohy“- je číselné proměnné, můžeme použít metodu jsem nebo metoda II pro lámání to do dummy proměnných.
příklad IV-řetězcová proměnná bez konverze
převod řetězcových proměnných na číselné je pro ně snadné vytvořit fiktivní proměnné. Bez této konverze je proces těžkopádný, protože SPSS nezpracovává chybějící hodnoty pro řetězcové proměnné správně. Níže uvedená syntaxe však provede práci správně.
frekvence jtype.
* šance‘ (Neznámý) ‚do’NA‘.
překódovat jtype (‚(Neznámý) ‚ = ‚NA‘).
* nastavení chybějících hodnot uživatele.
chybí hodnoty jtype („, ‚NA‘).
* znovu zkontrolujte frekvence.
frekvence jtype.
* Vytvořte fiktivní proměnné pro řetězcovou proměnnou.
if (not missing (jtype)) jtype_1 = (jtype = ‚IT‘).
if (not missing (jtype)) jtype_2 = (jtype = ‚Management‘).
if (not missing (jtype)) jtype_3 = (jtype = ‚Sales‘).
if (not missing (jtype)) jtype_4 = (jtype = ‚Staff‘).
* použijte štítky proměnných na fiktivní proměnné.
popisky proměnných
jtype_1 ‚Job type = IT‘
jtype_2 ‚Job type = Management‘
jtype_3 ‚ Job type = Sales ‚
jtype_4’Job type = Staff‘.
* zkontrolujte výsledky.
crosstabs jtype by jtype_1 až jtype_4.
závěrečné poznámky
vytváření fiktivních proměnných pro číselné proměnné lze provést rychle a snadno. Nastavení správných štítků proměnných však vždy vyžaduje trochu práce. Proměnné řetězce vyžadují některé další kroky, ale jsou také docela proveditelné.
nicméně nejjednodušší možností je náš nástroj SPSS Create Dummy proměnných, protože se o vše dokonale stará.