William W Wold
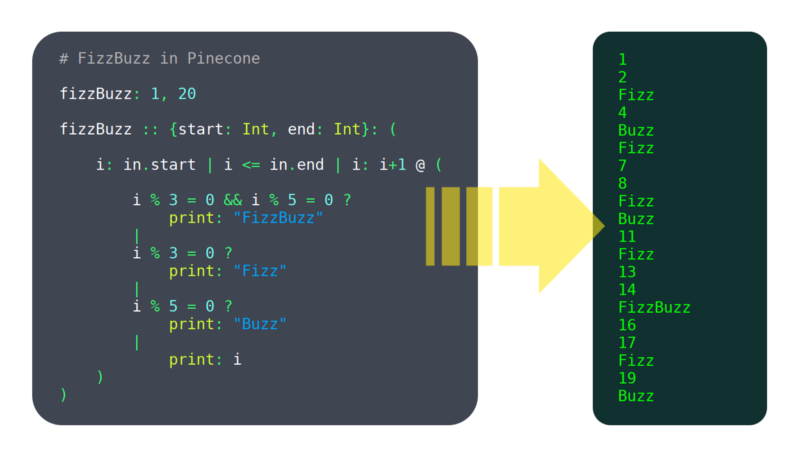
v Průběhu posledních 6 měsíců, pracoval jsem na programovací jazyk s názvem borová Šiška. Já bych neřekl, že je zralý, ale už to má dost funkcí, pracovat, aby byl použitelný, jako:
- proměnné
- funkce
- uživatelem definované struktury
Pokud máte zájem, podívejte se na Šišku vstupní stránku nebo její GitHub repo.
nejsem odborník. Když jsem tento projekt začal, neměl jsem ponětí, co dělám, a já ještě ne. Vzal jsem žádné kurzy na jazykové tvorby, přečtěte si jen o tom něco on-line, a nesledoval moc rady, které jsem dostal.
a přesto jsem vytvořil zcela nový jazyk. A funguje to. Takže musím něco dělat správně.
v tomto příspěvku se ponořím pod kapotu a ukážu vám Pipeline Pinecone (a další programovací jazyky), které používají k přeměně zdrojového kódu na magii.
dotknu se také některých kompromisů, které jsem udělal, a proč jsem učinil rozhodnutí, která jsem udělal.
Toto není v žádném případě úplný návod na psaní programovacího jazyka, ale je to dobrý výchozí bod, pokud jste zvědaví na vývoj jazyka.
Začínáme
„nemám absolutně tušení, kde bych dokonce začal“ je něco, co hodně slyším, když řeknu ostatním vývojářům, že píšu jazyk. V případě, že je to vaše reakce, nyní projdu několika počátečními rozhodnutími, která jsou učiněna, a kroky, které jsou podniknuty při spuštění jakéhokoli nového jazyka.
Compiled vs Interpreted
existují dva hlavní typy jazyků: kompilované a interpretované:
- kompilátor zjistí vše, co program udělá, změní jej na “ strojový kód „(formát, který počítač může běžet opravdu rychle), a uloží jej, aby byl proveden později.
- interpret prochází řádkem zdrojového kódu po řádku a zjišťuje, co dělá.
technicky lze sestavit nebo interpretovat jakýkoli jazyk, ale jeden nebo druhý obvykle dává větší smysl pro konkrétní jazyk. Obecně platí, že tlumočení má tendenci být flexibilnější, zatímco kompilace má tendenci mít vyšší výkon. Ale to je jen poškrábání povrchu velmi složitého tématu.
vysoce hodnotím výkon, a viděl jsem nedostatek programovací jazyky, které jsou oba vysoký výkon a jednoduchost-orientovaný, tak jsem šel s sestaven pro borová Šiška.
bylo To důležité rozhodnutí, aby se brzy, protože spousta jazyk design rozhodnutí jsou ovlivněna (například statické typování je velký přínos pro kompilované jazyky, ale ne tak moc pro vykládat ty).
navzdory skutečnosti, že Pinecone byl navržen s ohledem na kompilaci, má plně funkční interpret, který byl jediný způsob, jak jej spustit na chvíli. Existuje řada důvodů, které vysvětlím později.
výběr jazyka
vím, že je to trochu meta, ale programovací jazyk je sám o sobě program, a proto ho musíte napsat v jazyce. Vybral jsem si c++ kvůli jeho výkonu a velké sadě funkcí. Také mě vlastně baví pracovat v C++.
Pokud píšete interpretovaný jazyk, to dělá hodně smysl to psát v kompilovaném (jako je C, C++ nebo Swift), protože výkon se ztratil v jazyce svého tlumočníka a tlumočníka, který je tlumočení tlumočník bude sloučeniny.
Pokud plánujete kompilaci, je přijatelnější pomalejší jazyk (jako Python nebo JavaScript). Čas kompilace může být špatný, ale podle mého názoru to není zdaleka tak velký problém jako špatná doba běhu.
návrh na vysoké úrovni
programovací jazyk je obecně strukturován jako potrubí. To znamená, že má několik fází. Každá fáze má data formátovaná specifickým, dobře definovaným způsobem. Má také funkce pro transformaci dat z každé fáze do další.
první fáze je řetězec obsahující celý vstupní zdrojový soubor. Konečná fáze je něco, co lze spustit. To vše bude jasné, jak procházíme potrubím Pinecone krok za krokem.
Lexing

prvním krokem ve většině programovacích jazyků je lexing, nebo tokenizing. „Lex“ je zkratka pro lexikální analýzu, velmi efektní slovo pro rozdělení spoustu textu do tokenů. Slovo „tokenizer“ dává mnohem větší smysl, ale „lexer“ je tak zábavné říci, že ho stejně používám.
tokeny
token je malá jednotka jazyka. Token může být název proměnné nebo funkce (AKA identifikátor), operátor nebo číslo.
úkol Lexeru
lexer má vzít řetězec obsahující celé soubory v hodnotě zdrojového kódu a vyplivnout seznam obsahující každý token.
budoucí fáze potrubí nebudou odkazovat zpět na původní zdrojový kód, takže lexer musí produkovat všechny potřebné informace. Důvodem tohoto relativně přísného formátu potrubí je to, že lexer může provádět úkoly, jako je odstranění komentářů nebo zjištění, zda je něco číslo nebo identifikátor. Chcete, aby to logiku zamčené uvnitř lexer, a to jak takže nemusíte přemýšlet o těchto pravidel při psaní zbytek jazyka, a tak si můžete změnit typ syntaxe vše na jednom místě.
Flex
v den, kdy jsem začal jazyk, první věc, kterou jsem napsal, byl jednoduchý lexer. Brzy poté, začal jsem se učit o nástrojích, které by údajně usnadnily lexing, a méně buggy.
převládajícím takovým nástrojem je Flex, program, který generuje lexery. Dáte mu soubor, který má speciální syntaxi pro popis gramatiky jazyka. Z toho generuje program C, který lexuje řetězec a produkuje požadovaný výstup.
mé rozhodnutí
rozhodl jsem se ponechat lexer, který jsem napsal, prozatím. Nakonec jsem neviděl významné výhody používání Flex, alespoň ne natolik, abych ospravedlnil přidání závislosti a komplikoval proces sestavení.
můj lexer je dlouhý jen několik set řádků a málokdy mi dává nějaké potíže. Válcování vlastního lexeru mi také dává větší flexibilitu, například možnost přidat operátora do jazyka bez úpravy více souborů.
Analýzy

druhá fáze plynovodu je parser. Analyzátor změní seznam tokenů na strom uzlů. Strom používaný pro ukládání tohoto typu dat je známý jako abstraktní Syntaxový strom nebo AST. Alespoň v Pinecone nemá AST žádné informace o typech nebo o tom, které identifikátory jsou. Je to prostě strukturované tokeny.
Parser cla
analyzátor přidá strukturu do uspořádaného seznamu tokenů, které lexer produkuje. Chcete-li zastavit nejednoznačnosti, musí analyzátor vzít v úvahu závorky a pořadí operací. Jednoduše parsování operátorů není strašně obtížné, ale jak se přidávají další jazykové konstrukce, může se parsování stát velmi složitým.
Bison
opět bylo rozhodnuto o zapojení knihovny třetí strany. Převládající parsovací knihovnou je bizon. Bizon funguje hodně jako Flex. Napíšete soubor ve vlastním formátu, který ukládá informace o gramatice, pak Bison používá k vytvoření programu C, který provede vaši analýzu. Nechtěl jsem použít Bizona.
proč je vlastní lepší
s lexerem bylo rozhodnutí použít můj vlastní kód docela zřejmé. Lexer je takový triviální program, který nepíše své vlastní cítil skoro stejně hloupé jako nepíše své vlastní ‚left-pad’.
s analyzátorem je to jiná záležitost. Můj Pinecone parser je v současné době 750 řádky dlouhé, a já jsem napsal tři z nich, protože první dva byly odpadky.
původně jsem se rozhodl z několika důvodů, a i když to nešlo úplně hladce, většina z nich platí. Ty hlavní jsou následující:
- Minimalizovat přepínání kontextu pracovního postupu: přepínání kontextu mezi C++ a borová Šiška je dost špatné, bez házení v Bison je gramatika gramatika
- Udržet vytvořit jednoduché: pokaždé, když gramatiky změny Bison musí být spuštěn předtím, než stavět. To lze automatizovat, ale při přepínání mezi systémy sestavení se stává bolestí.
- já jako stavební cool sračky: nechtěl jsem, aby Šiška, protože jsem si myslel, že to bude snadné, tak proč bych delegovat ústřední roli, když jsem to mohl udělat sám? Vlastní analyzátor nemusí být triviální, ale je zcela proveditelný.
na začátku jsem si nebyl úplně jistý, jestli jdu schůdnou cestou, ale dostal jsem důvěru tím, co Walter Bright (vývojář na rané verzi C++ a tvůrce jazyka D) musel na toto téma říci:
“ poněkud kontroverznější, neobtěžoval bych se ztrácet čas generátory lexeru nebo parseru a dalšími tzv.“Jsou to ztráta času. Psaní lexeru a analyzátoru je malé procento práce psaní kompilátoru. Použití generátoru zabere asi tolik času jako psaní ručně a vezme vás do generátoru (což je důležité při přenosu kompilátoru na novou platformu). A generátory mají také nešťastnou pověst vydávání mizerných chybových zpráv.“
Akce Strom
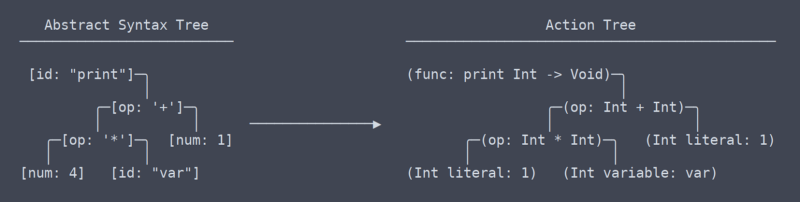
nyní Jsme opustili oblasti společné, všeobecné podmínky, nebo alespoň nevím, jaké jsou podmínky. Z mého chápání je to, čemu říkám „akční strom“, nejvíce podobné IR (střední reprezentace) LLVM.
existuje jemný, ale velmi významný rozdíl mezi stromem akce a stromem abstraktní syntaxe. Trvalo mi docela dlouho, než jsem zjistil, že by mezi nimi měl být dokonce rozdíl (což přispělo k potřebě přepisování analyzátoru).
strom akce vs ast
jednoduše řečeno, strom akce je AST s kontextem. Tento kontext je informace, jako například to, jaký typ funkce vrací, nebo že dvě místa, ve kterých je proměnná použita, ve skutečnosti používají stejnou proměnnou. Protože potřebuje zjistit a zapamatovat si všechny tyto souvislosti, kód, který generuje strom akcí, potřebuje spoustu vyhledávacích tabulek jmenného prostoru a dalších věcí.
spuštění stromu akcí
jakmile máme strom akcí, spuštění kódu je snadné. Každý uzel akce má funkci „execute“, která bere nějaký vstup, dělá vše, co by akce měla (včetně případného volání dílčí akce) a vrací výstup akce. Toto je tlumočník v akci.
Možnosti kompilace
“ ale počkejte!“Slyšel jsem, že říkáš,“ nemá šišku zkompilovat?“Ano, je. Kompilace je ale těžší než tlumočení. Existuje několik možných přístupů.
Vytvořte si vlastní kompilátor
to mi zpočátku znělo jako dobrý nápad. Sám si věci dělám rád a hledal jsem výmluvu, abych se dobře montoval.
bohužel psaní přenosného kompilátoru není tak snadné jako psaní nějakého strojového kódu pro každý jazykový prvek. Vzhledem k počtu architektur a operačních systémů je pro každého jednotlivce nepraktické psát backend kompilátoru napříč platformami.
Dokonce i týmy, za Swift, Rez a Clang nechcete obtěžovat s to všechno na vlastní pěst, a tak místo toho používají…
LLVM
LLVM je sbírka kompilátor nástroje. Je to v podstatě knihovna, která změní váš jazyk na kompilovaný spustitelný binární soubor. Vypadalo to jako perfektní volba, tak jsem skočil přímo dovnitř. Bohužel jsem nekontroloval, jak hluboká je voda, a okamžitě jsem se utopil.
LLVM, i když není těžké sestavit jazyk, je obrovská složitá knihovna. Není to nemožné použít a mají dobré návody, ale uvědomil jsem si, že budu muset získat nějakou praxi, než budu připraven plně implementovat kompilátor Pinecone s ním.
Transpiling
chtěl jsem nějakou zkompilovanou šišku a chtěl jsem ji rychle, takže jsem se obrátil na jednu metodu, o které jsem věděl, že mohu pracovat: transpiling.
napsal jsem Pinecone na C++ transpiler, a přidal možnost automaticky zkompilovat výstupní zdroj s GCC. To v současné době funguje pro téměř všechny programy Pinecone (i když existuje několik okrajových případů, které jej rozbijí). Nejedná se o zvlášť přenosné nebo škálovatelné řešení, ale prozatím funguje.
budoucí
za předpokladu, že budu pokračovat ve vývoji Pinecone, dostane LLVM kompilační podporu dříve nebo později. Mám podezření, že žádný mater, jak moc na tom pracuji, transpiler nikdy nebude zcela stabilní a výhody LLVM jsou četné. Je jen otázkou, Kdy budu mít čas udělat nějaké ukázkové projekty v LLVM a dostat se na kloub.
do té doby je interpret skvělý pro triviální programy a C++ transpiling funguje pro většinu věcí, které vyžadují větší výkon.
závěr
doufám, že jsem pro vás udělal programovací jazyky trochu méně záhadné. Pokud si chcete udělat sami, vřele doporučuji. Existuje spousta implementačních podrobností, které je třeba zjistit, ale obrys by měl stačit, aby vás dostal.
zde je moje rada na vysoké úrovni, jak začít (pamatujte, opravdu nevím, co dělám, tak si to vezměte s rezervou):
- Pokud máte pochybnosti, jděte interpretovat. Interpretované jazyky jsou obecně jednodušší design, stavět a učit se. Nejsem odrazuje vás od psaní sestaven jeden, pokud víte, že je to to, co chcete dělat, ale pokud jste na plot, šel bych vykládat.
- Pokud jde o lexery a analyzátory, dělejte, co chcete. Existují platné argumenty pro a proti psaní Vlastní. Nakonec, pokud přemýšlíte o svém designu a implementujete vše rozumným způsobem,na tom nezáleží.
- poučte se z potrubí, se kterým jsem skončil. Hodně pokusů a omylů šlo do navrhování potrubí, které mám teď. Pokusil jsem se eliminovat Asty, Asty, které se proměňují v akce stromů na místě, a další hrozné nápady. Tento potrubí funguje, takže jej neměňte, pokud nemáte opravdu dobrý nápad.
- Pokud nemáte čas nebo motivaci implementovat komplexní obecný jazyk, zkuste implementovat esoterický jazyk, jako je Brainfuck. Tito tlumočníci mohou být tak krátké jako několik set řádků.
mám velmi málo lítostí, pokud jde o vývoj šišky. Na cestě jsem udělal řadu špatných rozhodnutí, ale většinu kódu ovlivněného takovými chybami jsem přepsal.
právě teď je Pinecone v dostatečně dobrém stavu, že funguje dobře a lze jej snadno vylepšit. Psaní šišky bylo pro mě nesmírně vzdělávacím a příjemným zážitkem, a to teprve začíná.