informace o verzi: kód pro tuto stránku byl testován ve stata 12.
Poissonova regrese se používá k modelování počtu proměnných.
upozornění: účelem této stránky je ukázat, jak používat různé příkazy pro analýzu dat. Nezahrnuje všechny aspekty výzkumného procesu, od kterého se očekává, že vědci budou dělat. Nezahrnuje zejména čištění a kontrolu dat, ověřování předpokladů, diagnostiku modelů nebo případné následné analýzy.
příklady poissonovy regrese
Příklad 1. Počet osob zabitých mezky nebo koňskými kopy v pruské armádě za rok.Ladislaus Bortkiewicz shromáždil údaje z 20 svazků preussischen Statistik. Tyto údaje byly shromážděny na 10 sboru pruské armády v pozdních 1800s v průběhu 20 let.
příklad 2. Počet lidí ve frontě před vámi v obchodě s potravinami. Prediktory mohou zahrnovat počet položek v současné době nabízen za speciální zvýhodněnou cenu a zda speciální akce (např. dovolená, velká sportovní událost) je tři nebo méně dní.
příklad 3. Počet ocenění získaných studenty na jedné střední škole. Prediktory počtu získaných ocenění zahrnují typ programu, do kterého byl student zapsán (např. odborný, obecný nebo akademický) a skóre na závěrečné zkoušce z matematiky.
popis dat
pro ilustraci jsme simulovali datovou sadu například 3 výše. V tomto příkladu, num_awards je výsledek variabilní a udává počet ocenění získaných studenty na vysoké škole v roce, matematika je kontinuální prediktor proměnnou a představuje výsledky žáků na jejich matematické závěrečné zkoušky, a prog je kategoriální prediktor proměnnou s tři úrovně, s uvedením typu programu, ve kterém studenti byli zapsáni.
začněme načtením dat a podíváme se na některé popisné statistiky.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
Každá proměnná má 200 platných pozorování a jejich distribuce se zdá docela rozumné. V tomto konkrétním případě se nepodmíněný průměr a rozptyl naší proměnné výsledku příliš neliší.
pokračujme v popisu proměnných v této datové sadě. Tabulka níže ukazuje průměrné počty nálezů podle typu programu a zdá se, že naznačují, že program je dobrý kandidát pro predikci řadu ocenění, náš výsledek proměnné, protože střední hodnota výsledku se zdá se liší podle prog.
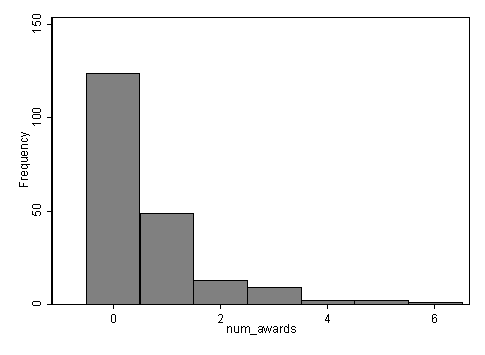
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
Analýza metody, můžete zvážit
Níže je seznam některých metod analýzy, možná jste se setkali. Některé z uvedených metod jsou docela rozumné, zatímco jiné buď vypadly z laskavosti, nebo mají omezení.
- Poissonova regrese-Poissonova regrese se často používá pro modelování počtu dat. Poissonova regrese má řadu rozšíření užitečných pro počítání modelů.
- Negativní binomické regrese – Negativní binomické regrese může být použit pro více než-rozptýlené počet dat, to je, když podmíněný rozptyl přesahuje podmíněné mysli. Lze jej považovat za zobecnění poissonovy regrese, protože má stejnou střední strukturu jako Poissonova regrese a má další parametr pro modelování nadměrné disperze. Jestliže podmíněné rozdělení výsledku proměnná je více rozptýlené, intervaly spolehlivosti pro Záporné binomialregression mohly být užší v porovnání s těmi z Poissonova regrese.
- Zero-inflated regression model-Zero-inflated models se pokouší vysvětlit nadbytečné nuly. Jinými slovy, předpokládá se, že v datech existují dva druhy nul, „skutečné nuly“ a „nadbytečné nuly“. Nulově nafouknuté modely odhadují dvě rovnice současně, jednu pro počítací model a druhou pro nadbytečné nuly.
- OLS regrese-výsledné proměnné počtu jsou někdy log-transformovány a analyzovány pomocí OLS regrese. S tímto přístupem vyvstává mnoho problémů, včetně ztráty dat v důsledku nedefinovaných hodnot generovaných přijetím protokolu nula (což je nedefinované) a zkreslených odhadů.
Poissonova regrese
níže používáme Poissonův příkaz k odhadu Poissonova regresního modelu. I. before prog označuje, že se jedná o proměnnou faktorů (tj., kategorická proměnná), a že by měla být zahrnuta do modelu jako řada indikátorových proměnných.
používáme volbu vce(robustní) k získání robustních standardních chyb pro odhady parametrů podle doporučení Camerona a Trivedi (2009) pro kontrolu mírného porušení základních předpokladů.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
dva stupně volnosti chí-kvadrát test ukazuje, že prog, dohromady, je statisticky významný prediktor num_awards.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
K posouzení vhodnosti modelu, estat gof příkaz může být použit k získání goodness-of-fit chi-squared test. Nejedná se o test modelových koeficientů (které jsme viděli v hlavičkových informacích), ale o test modelové formy: odpovídá formulář Poissonova modelu našim datům?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
došli Jsme k závěru, že model se hodí poměrně dobře, protože goodness-of-fit chi-kvadrát test je statisticky významný. Pokud by byl test statisticky významný, znamenalo by to, že data neodpovídají modelu dobře. V této situaci se můžeme pokusit zjistit, zda existují vynechané prediktorové proměnné, zda náš předpoklad linearity platí a / nebo zda existuje problém nadměrného rozptylu.
někdy můžeme chtít prezentovat výsledky regrese jako poměry incidentů, můžeme použít jejich volbu R. Tyto hodnoty IRR se rovnají našim koeficientům z výstupu nad exponentovaným.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
výstup výše uvedeného vyplývá, že incident kurz pro 2.prog je 2,96 násobek incidentů pro referenční skupinu (1.pořada). Stejně tak míra incidentů pro 3.prog je 1,45 násobek incidenční rychlosti pro referenční skupinu, která drží ostatní proměnné konstantní. Procentuální změna míry incidentů num_awards je nárůst o 7% pro každé zvýšení jednotky v matematice.
Připomeňme si podobu naší modelové rovnice:
log(num_awards) = Intercept + b1(prog=2) + b2(prog=3) + b3math.
To znamená:
num_awards = exp(Intercept + b1(prog=2) + b2(prog=3)+ b3math) = exp(Intercept) * exp(b1(prog=2)) * exp(b2(prog=3)) * exp(b3math)
koeficienty mají aditivní účinek v log(y), měřítko a IRR mít multiplikativní efekt v y měřítku.
další informace o různých metrik, ve kterém mohou být výsledky prezentovány, a výklad těchto, naleznete Regresní Modely pro Kategoriální závisle Proměnných Pomocí Stata, Druhé Vydání J. Scott Dlouho a Jeremy Freese (2006).
pro lepší pochopení modelu můžeme použít příkaz okraje. Níže používáme rozpětí příkazu k výpočtu předpokládané počty na každé úrovni ofprog, drží všechny ostatní proměnné (v tomto případě matematika) v modelu na jejich střední hodnoty.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
ve výše uvedeném výstupu vidíme, že předpokládaný počet událostí pro úroveň 1 prog je asi .21, drží matematiku v průměru. Předpokládaný počet událostí pro úroveň 2 prog je vyšší na .62, a předpokládaný počet událostí pro úroveň 3 prog je asi .31. Všimněte si, že předpokládaný počet úrovně 2 prog je (.6249446/.211411) = 2,96 krát vyšší než předpokládaný počet pro úroveň 1 prog. To odpovídá tomu, co jsme viděli v tabulce výstupů IRR.
níže získáme předpokládané počty pro hodnoty matematiky, které se pohybují od 35 do 75 v krocích po 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
z výše uvedené tabulky vyplývá, že s prog na její pozorované hodnoty a matematika se konala v 35 pro všechna pozorování, průměrná předpokládaná počítat (nebo průměrný počet ocenění).13; když math = 75, průměrný předpokládaný počet je asi 2.17. Porovnáme-li předpokládané počty v matematice = 35 a matematice = 45, můžeme vidět, že poměr je (.2644714/.1311326) = 2.017. To odpovídá IRR 1,0727 pro změnu jednotky 10: 1,0727^10 = 2,017.
uživatelsky napsaný příkaz fitstat (stejně jako příkazy stata estat) lze použít k získání dalších informací, které mohou být užitečné, pokud chcete porovnat modely. Chcete-li tento program stáhnout, můžete zadat search fitstat (viz Jak mohu pomocí příkazu search vyhledat programy a získat další pomoc? pro více informací o používání vyhledávání).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
předpovídaný počet událostí můžete grafovat pomocí níže uvedených příkazů. Graf ukazuje, že nejvíce ocenění je předpovězeno pro ty, kteří jsou v akademickém programu (prog = 2), zejména pokud má student vysoké matematické skóre. Nejnižší počet předpokládaných ocenění je pro studenty v obecném programu (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
Věci, aby zvážila
- Pokud overdispersion se zdá být problém, měli bychom nejprve zkontrolovat, zda náš model je správně specifikován, jako vynechány proměnné a funkčních forem. Například, pokud jsme vynechal prediktor proměnnou progin příkladu výše, náš model by se zdát, že mají problém s over-disperze. Jinými slovy, špatně specifikovaný model by mohl představovat příznak jako problém s nadměrným rozptylem.
- za předpokladu, že je model správně zadán, možná budete chtít zkontrolovat foroverdispersion. Existuje několik způsobů, jak toho dosáhnout, včetně testu poměru pravděpodobnosti nadměrného rozptylu parametru alfa spuštěním stejného regresního modelu pomocí negativního binomického rozdělení (nbreg).
- jednou z častých příčin nadměrného rozptylu jsou nadbytečné nuly, které jsou následně generovány dalším procesem generování dat. V této situaci je třeba zvážit nulový nafouknutý model.
- pokud proces generování dat neumožňuje žádné 0s (například počet dní strávených v nemocnici), může být vhodnější model s nulovým zkrácením.
- údaje o počtu mají často proměnnou expozice, která udává, kolikrát se událost mohla stát. Tato proměnná by měla být začleněna do Poissonova modelu s použitím volby exp ().
- výsledek proměnné v Poissonova regrese nemůže mít negativní čísla, a daná expozice nemůže mít 0s.
- V Stata, Poissonova modelu lze odhadnout pomocí glm příkaz s log link a Poisson rodiny.
- Budete muset použít glm příkaz pro získání rezidua se, zda další předpoklady Poissonova modelu (viz Cameron a Trivedi (1998) a Dupont (2002) pro více informací).
- existuje mnoho různých měřítek pseudo-R-na druhou. Všichni se pokoušejí poskytnout informace podobné informacím poskytovaným R-na druhou v OLS regresi, i když žádnou z nich nelze interpretovat přesně tak, jak je interpretována r-na druhou v OLS regresi. Pro diskusi o různých pseudo-R-čtvercích viz Long and Freese (2006) nebo naše stránka FAQCO jsou pseudo R-čtverce?.
- Poissonova regrese se odhaduje pomocí odhadu maximální věrohodnosti. Obvykle vyžaduje velkou velikost vzorku.
Viz také
- Komentovaný výstup pro poissonovo příkaz
- Stata FAQ: Jak mohu použít countfit při výběru počítat model?
- Stata online příručce
- poissonovo rozdělení
- Stata často kladené otázky
- Jak jsou standardní chyby a intervaly spolehlivosti vypočtené pro výskyt-rychlost ukazatele (Irr) poissonovo a nbreg?
- Cameron, a. C. and Trivedi, P. K. (2009). Mikroekonometrie Pomocí Stata. College Station, TX: Stata Press.
- Cameron, a. C. and Trivedi, P. K. (1998). Regresní analýza Počtových dat. New York: Cambridge Press.
- Cameron, a. C. Advances in Count Data Regression Talk for the Applied Statistics Workshop, March 28, 2009.http://cameron.econ.ucdavis.edu/racd/count.html .
- Dupont, W. D. (2002). Statistické modelování pro biomedicínské výzkumníky: jednoduchý úvod do analýzy složitých dat. New York: Cambridge Press.
- Long, J. S. (1997). Regresní modely pro kategorické a omezené závislé proměnné.Thousand Oaks, že: Sage Publications.
- Long, J. S. and Freese, J. (2006). Regresní modely pro kategoricky závislé proměnné pomocí Stata, druhé vydání. College Station, TX: Stata Press.