Co je Výztuž Učení?
Výztuž Učení je definován jako Stroj, metoda Učení, která se zabývá jak softwarových agentů by měla přijmout opatření v prostředí. Posilování učení je součástí metody hlubokého učení, která vám pomůže maximalizovat část kumulativní odměny.
tato metoda učení neuronové sítě vám pomůže naučit se, jak dosáhnout komplexního cíle nebo maximalizovat konkrétní rozměr v mnoha krocích.
v tutoriálu pro vyztužení se dozvíte:
- co je to výztužné učení?
- důležité pojmy používané v metodě učení hlubokého posílení
- jak funguje učení výztuže?
- Posílení Učení Algoritmy
- Vlastnosti Výztuže Učení
- Typy Výztuže Učení
- Modely Učení Výztuže
- Posílení Učení versus Učení s učitelem
- Aplikace Výztuže Učení
- Proč používat Výztuž Učení?
- kdy nepoužívat výztužné učení?
- Výzvy Výztuže Učení
Důležité pojmy používané v Hluboké Výztuže metodou Učení
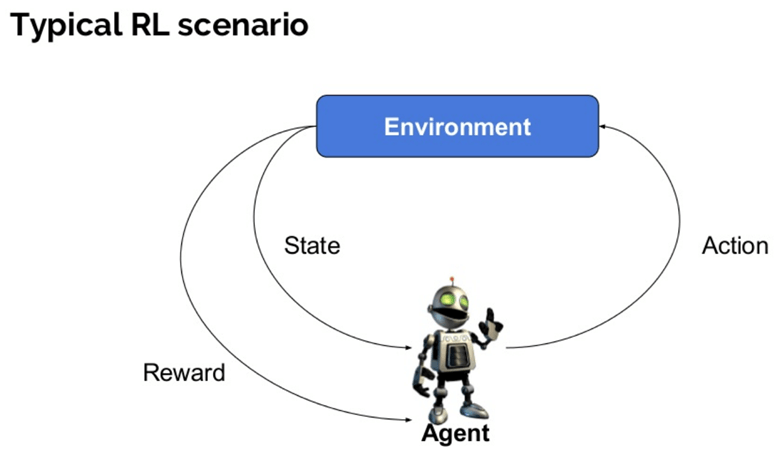
Zde jsou některé důležité pojmy, používané v Posílení AI:
- Agent: To předpokládá, že subjekt, který vykonává činnosti v prostředí, získat nějakou odměnu.
- prostředí (e): scénář, kterému musí agent čelit.
- odměna (R): Okamžitý návrat k agentovi, když on nebo ona provádí konkrétní akci nebo úkol.
- stav (stavy): stav označuje současnou situaci, kterou životní prostředí vrací.
- politika (?): Jedná se o strategii, kterou agent použije k rozhodnutí o další akci na základě aktuálního stavu.
- hodnota (V): očekává se dlouhodobý výnos se slevou ve srovnání s krátkodobou odměnou.
- hodnota funkce: určuje hodnotu stavu, který je celkovou částkou odměny. Je to agent, který by měl být očekáván od tohoto stavu.
- Model prostředí: napodobuje chování prostředí. To vám pomůže učinit závěry, které mají být provedeny, a také určit, jak se bude chovat životní prostředí.
- metody založené na modelu: Jedná se o metodu pro řešení problémů učení výztuže, které používají metody založené na modelu.
- hodnota Q nebo hodnota akce (Q): hodnota Q je docela podobná hodnotě. Jediný rozdíl mezi těmito dvěma je, že jako aktuální akci vyžaduje další parametr.
jak funguje výztužné učení?
podívejme se na jednoduchý příklad, který vám pomůže ilustrovat mechanismus učení výztuže.
zvažte scénář výuky nových triků vaší kočce
- protože kočka nerozumí angličtině nebo jinému lidskému jazyku, nemůžeme jí přímo říct, co má dělat. Místo toho se řídíme jinou strategií.
- napodobujeme situaci a kočka se snaží reagovat mnoha různými způsoby. Pokud je reakce kočky požadovaným způsobem, dáme jí ryby.
- Nyní, když kočka je vystavena stejné situaci, kočka provádí podobné akce s ještě větším nadšením v očekávání získání více odměnu(potravu).
- to je jako učit se, že kočka dostane z“ co dělat “ z pozitivních zkušeností.
- současně se kočka také dozví, co nedělá, když čelí negativním zkušenostem.
vysvětlení k příkladu:
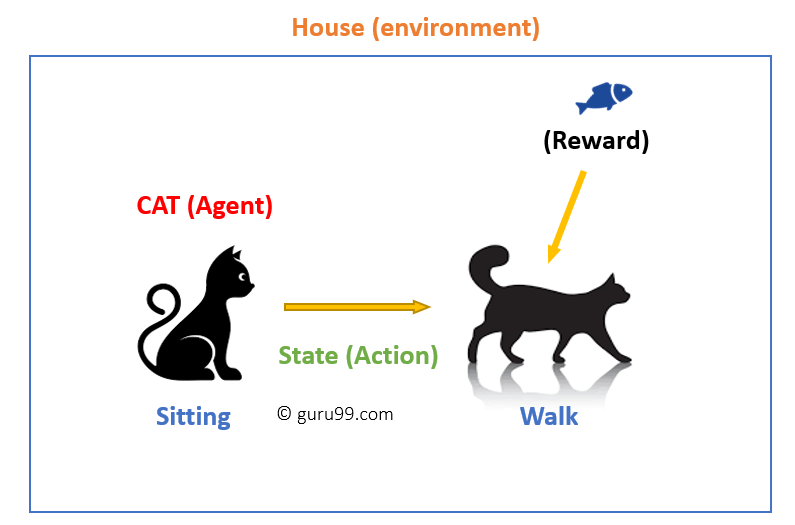
V tomto případě,
- Vaše kočka je agent, který je vystaven na životní prostředí. V tomto případě je to váš dům. Příkladem stavu může být vaše kočka sedí, a použít konkrétní slovo pro kočku chodit.
- náš agent reaguje provedením akčního přechodu z jednoho „stavu“ do jiného “ stavu.“
- například vaše kočka jde ze sezení na chůzi.
- reakce agenta je akce a politika je metoda výběru akce daného státu v očekávání lepších výsledků.
- po přechodu mohou dostat odměnu nebo trest na oplátku.
algoritmy učení výztuže
existují tři přístupy k implementaci algoritmu učení výztuže.
Value-Based:
v metodě posilování založené na hodnotách byste se měli pokusit maximalizovat hodnotu funkce V (y). V této metodě agent očekává dlouhodobý návrat současných států v rámci politiky ?.
politika-based:
v metodě RL založené na zásadách se snažíte přijít s takovou politikou, že akce provedená v každém státě vám pomůže získat maximální odměnu v budoucnu.
dva typy metod založených na zásadách jsou:
- deterministické: pro jakýkoli stát je stejná akce vytvořena politikou ?.
- Stochastic: každá akce má určitou pravděpodobnost, která je určena následující rovnicí.Stochastic Policy:
n{a\s) = P\A, = a\S, =S]
Model-Based:
v této metodě učení výztuže musíte vytvořit virtuální model pro každé prostředí. Agent se učí hrát v tomto konkrétním prostředí.
Vlastnosti Výztuže Učení
Zde jsou důležité vlastnosti výztuže učení,
- Neexistuje žádný nadřízený, pouze reálné číslo, nebo odměnu signálu
- Sekvenční rozhodování
- Čas hraje zásadní roli v Posilování problémy
- Zpětná vazba je vždy zpožděn, ne okamžitě,
- akce Agenta určit následující údaje, které obdrží
Druhy Výztuže Učení
Dva druhy výztuže metody učení jsou:
Pozitivní:
je definována jako událost, ke které dochází kvůli specifickému chování. Zvyšuje sílu a frekvenci chování a pozitivně ovlivňuje činnost činitele.
Tento typ výztuže vám pomůže maximalizovat výkon a udržet změny po delší dobu. Příliš mnoho výztuže však může vést k nadměrné optimalizaci stavu, což může ovlivnit výsledky.
Negativní:
Negativní Výztuž je definován jako posílení chování dochází, protože negativní stav, který by měl zastavit nebo se vyhnout. To vám pomůže definovat minimální stojan výkonu. Nevýhodou této metody je však to, že poskytuje dostatek pro splnění minimálního chování.
Modely Učení Výztuže
k Dispozici jsou dva důležité modely učení v posílení učení:
- Markovovy Rozhodovací Proces
- Q učení
Markovovy Rozhodovací Proces
následující parametry se používají k získání řešení:
- akce
- Sada státy -S
- Odměna – R
- Politiky – n
- Hodnota – V
matematický přístup pro mapování řešení v posílení Učení je průzkum jako markovský Rozhodovací Proces nebo (MDP).
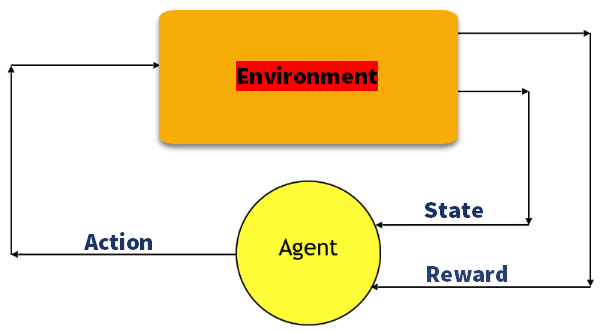
Q-Učení
Q-učení je hodnota-metoda založená na poskytování informací, aby se informovat, jaká akce agent by se měli vzít.
rozumíme této metodě na následujícím příkladu:
- v budově je pět místností, které jsou spojeny dveřmi.
- Každý pokoj je číslovaná 0 až 4
- mimo budovy může být jedna velká vnější plocha (5)
- Dveře číslo 1 a 4 vedení do budovy z místnosti 5
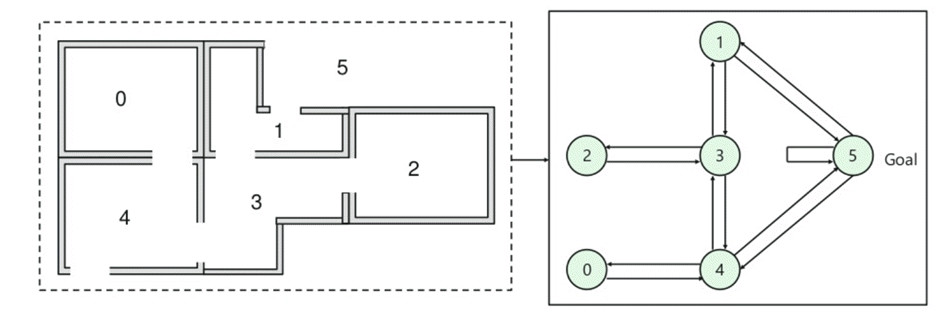
Next, potřebujete spojit odměnu hodnota na každé dveře:
- Dveře, které vedou přímo k cíli mít odměnu 100
- Dveře, které není přímo připojeno k cílové místnosti dává nulovou odměnu
- Jako jsou dveře, obousměrný, a dvě šipky jsou přiřazeny pro každý pokoj
- Každá šipka na obrázku výše obsahuje okamžitý odměnu hodnota
Vysvětlení:
Na tomto obrázku, můžete si prohlédnout ten pokoj představuje stav,
Agent je pohyb z jedné místnosti do druhé představuje akci
V níže uvedené obraz, stav je popsán jako uzel, zatímco šipky ukazují akci.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Učení s učitelem
| Parametry | Posílení Učení | Učení s učitelem |
| Rozhodnutí styl | posílení učení vám pomůže, aby vaše rozhodnutí postupně. | v této metodě se rozhoduje o vstupu zadaném na začátku. |
| pracuje na | pracuje na interakci s prostředím. | pracuje na příkladech nebo daných vzorových datech. |
| závislost na rozhodnutí | v RL metodě učení rozhodnutí je závislé. Proto byste měli dát štítky všem závislým rozhodnutím. | dohlížel učení rozhodnutí, která jsou na sobě nezávislá, takže štítky jsou uvedeny pro každé rozhodnutí. |
| nejvhodnější | podporuje a pracuje lépe v AI, kde převládá lidská interakce. | je většinou provozován s interaktivním softwarovým systémem nebo aplikacemi. |
| Příklad | Šachy hru | rozpoznávání Objektů |
Aplikace Výztuže Učení
Zde jsou aplikace Výztuže Učení:
- Robotika průmyslové automatizace.
- plánování obchodní strategie
- strojové učení a zpracování dat
- pomáhá vám vytvářet vzdělávací systémy, které poskytují vlastní instrukce a materiály podle požadavků studentů.
- řízení letadel a řízení pohybu robotů
Proč používat výztužné učení?
Zde jsou hlavní důvody pro použití Výztuže Učení:
- To vám pomůže zjistit, které situace vyžaduje akci
- Pomůže zjistit, které akce získá nejvyšší odměnu za delší dobu.
- výztužné učení také poskytuje učícímu agentovi funkci odměny.
- umožňuje také zjistit nejlepší způsob získání velkých odměn.
kdy nepoužívat výztužné učení?
nemůžete použít model učení výztuže je celá situace. Zde jsou některé podmínky, kdy byste neměli používat model učení výztuže.
- máte-li dostatek údajů k vyřešení problému s dohledem učení metody
- musíte Si uvědomit, že Učení zesílení je computing-těžké a časově náročné. zejména pokud je akční prostor velký.
Výzvy Výztuže Učení
Zde jsou hlavní výzvy budete čelit, zatímco dělá Výztuže vydělávat:
- Funkce/odměna design, který by měl být velmi zapojený
- Parametry mohou mít vliv na rychlost učení.
- Realistická prostředí mohou mít částečnou pozorovatelnost.
- příliš mnoho výztuže může vést k přetížení stavů, které mohou snížit výsledky.
- Realistická prostředí mohou být nestacionární.
Shrnutí:
- Posílení Učení je Strojové Učení metody
- Pomůže zjistit, které akce získá nejvyšší odměnu za delší dobu.
- tři metody pro posílení učení jsou 1) hodnota-based 2) politika-based a Model-based učení.
- Agent, Stav, Odměna, Prostředí, Hodnoty funkce Modelu prostředí, Model na bázi metody, jsou některé důležité pojmy, použití v RL způsob učení
- příklad výztuže učení je vaše kočka je agent, který je vystaven na životní prostředí.
- největší rysem této metody je, že neexistuje žádný nadřízený, pouze reálné číslo, nebo odměnu signálu
- Dva typy výztuže učení jsou: 1) Pozitivní, 2) Negativní
- Dva široce používán model učení jsou: 1) Markovovy Rozhodovací Proces 2) Q učení
- Posílení Vzdělávací metoda funguje na interakci s prostředím, vzhledem k tomu, že učení s učitelem metoda funguje na daném vzorku dat nebo příklad.
- aplikační nebo výztužné metody učení jsou: Robotika pro průmyslovou automatizaci a obchodní strategie, plánování
- neměli Byste používat tuto metodu, pokud máte dostatek údajů k vyřešení problému
- největší problém této metody je, že parametry mohou mít vliv na rychlost učení