Poslední aktualizace 17. února 2021
predikce z pohledu strojového učení je jediný bod, který skrývá nejistota, že predikce.
intervaly predikce poskytují způsob, jak kvantifikovat a sdělit nejistotu v predikci. Liší se od intervalů spolehlivosti, které se místo toho snaží kvantifikovat nejistotu v parametru populace, jako je střední nebo směrodatná odchylka. Intervaly predikce popisují nejistotu pro jeden konkrétní výsledek.
v tomto tutoriálu zjistíte interval predikce a jak jej vypočítat pro jednoduchý lineární regresní model.
po dokončení tohoto tutoriálu budete vědět:
- že interval predikce kvantifikuje nejistotu předpovědi jednoho bodu.
- že intervaly predikce mohou být odhadnuty analyticky pro jednoduché modely, ale jsou náročnější pro nelineární modely strojového učení.
- jak vypočítat interval predikce pro jednoduchý lineární regresní model.
nastartujte svůj projekt pomocí mé nové statistiky knih pro strojové učení, včetně podrobných tutoriálů a souborů zdrojového kódu Pythonu pro všechny příklady.
začněme.
- Aktualizováno červen / 2019: opravená úroveň významnosti jako zlomek směrodatných odchylek.
- aktualizováno duben / 2020: Opraven překlep v grafu intervalu predikce.

Predikční Intervaly pro Strojové Učení
Photo by Jim Bendon, některá práva jsou vyhrazena.
Návod Přehled
Tento výukový program je rozdělen do 5 částí; jsou to:
- Co Je Špatného na Bodový Odhad?
- co je interval predikce?
- Jak Vypočítat Předpověď Interval
- Odhad Interval pro Lineární Regrese
- Pracoval Například
Potřebujete pomoci s Statistiky pro Strojové Učení?
Vezměte si zdarma 7denní e-mailový rychlokurz (se vzorovým kódem).
kliknutím se zaregistrujete a také získáte zdarma PDF Ebook verzi kurzu.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.předvídat(X)
|
Kde, to je odhadovaný výsledek nebo předpověď ze strany vyškolených modelu pro daná vstupní data X.
Toto je bod predikce.
podle definice je to odhad nebo aproximace a obsahuje určitou nejistotu.
nejistota pochází z chyb v samotném modelu a šumu ve vstupních datech. Model je aproximací vztahu mezi vstupními proměnnými a výstupními proměnnými.
vzhledem k tomu, proces použitý pro výběr a vyladit model, bude to nejlepší přiblížení se vzhledem k dispozici informace, ale to bude ještě dělat chyby. Data z domény přirozeně zakrývají základní a neznámý vztah mezi vstupními a výstupními proměnnými. To bude výzvou, aby se vešly model, a bude také výzvou pro fit modelu, aby se předpovědi.
vzhledem k těmto dvěma hlavním zdrojům chyb není jejich bodová predikce z prediktivního modelu dostatečná pro popis skutečné nejistoty predikce.
co je interval predikce?
interval predikce je kvantifikace nejistoty na predikci.
poskytuje pravděpodobnostní horní a dolní meze odhadu proměnné výsledku.
predikční interval pro jednu budoucí pozorování je interval, který bude s určitou mírou jistoty, obsahují budoucí náhodně vybrané pozorování z rozdělení.
— – Strana 27, statistické intervaly: průvodce pro odborníky a výzkumné pracovníky, 2017.
intervaly predikce se nejčastěji používají při vytváření předpovědí nebo předpovědí s regresním modelem, kde se předpovídá veličina.
příklad prezentace predikce intervalu je následující:
Vzhledem k tomu, predikce ‚y‘ vzhledem k ‚x‘, tam je 95% pravděpodobnost, že rozsah “ a “ na “ b “ se vztahuje na skutečný výsledek.
interval predikce obklopuje predikci provedenou modelem a doufejme, že pokrývá rozsah skutečného výsledku.
níže uvedený diagram pomáhá vizuálně pochopit vztah mezi predikcí, intervalem predikce a skutečným výsledkem.
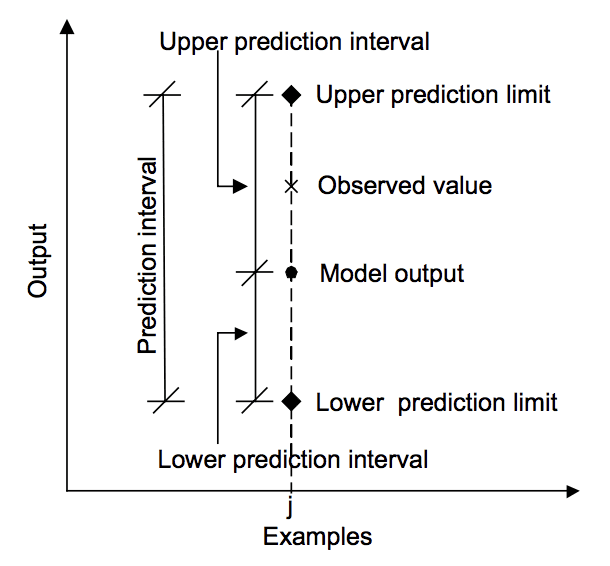
Vztah mezi předpovědi, skutečné hodnoty a predikce intervalu.
převzato z „Machine learning approaches for estimation of prediction interval for the model output“, 2006.
interval predikce se liší od intervalu spolehlivosti.
interval spolehlivosti kvantifikuje nejistotu odhadované populační proměnné, jako je průměr nebo směrodatná odchylka. Zatímco interval predikce kvantifikuje nejistotu na jediném pozorování odhadovaném z populace.
v prediktivním modelování lze interval spolehlivosti použít ke kvantifikaci nejistoty odhadované dovednosti modelu, zatímco interval predikce lze použít ke kvantifikaci nejistoty jedné prognózy.
interval predikce je často větší než interval spolehlivosti, protože musí brát v úvahu interval spolehlivosti a rozptyl předpovídané výstupní proměnné.
intervaly predikce budou vždy širší než intervaly spolehlivosti, protože představují nejistotu spojenou s e, neredukovatelnou chybou.
— – Strana 103, Úvod do statistického učení: s aplikacemi v R, 2013.
Jak vypočítat interval predikce
interval predikce se vypočítá jako nějaká kombinace odhadované rozptylu modelu a rozptylu proměnné výsledku.
intervaly predikce lze snadno popsat, ale v praxi je obtížné je vypočítat.
v jednoduchých případech, jako je lineární regrese, můžeme odhadnout interval predikce přímo.
V případě nelineární regrese algoritmů, jako jsou umělé neuronové sítě, je mnohem náročnější a vyžaduje, výběr a realizace specializovaných technik. Lze použít obecné techniky, jako je metoda převzorkování bootstrap, ale výpočet je výpočetně nákladný.
kniha „Komplexní Přezkum Neuronové Sítě založené na Predikci časových Intervalech a Nové Zálohy“ poskytuje poměrně nedávné studie predikční intervaly pro nelineární modely v kontextu neuronových sítí. Následující seznam shrnuje některé metody, které lze použít pro Predikční nejistotu pro nelineární modely strojového učení:
- Delta metoda z oblasti nelineární regrese.
- Bayesovská metoda, z Bayesovského modelování a statistiky.
- metoda odhadu průměrné rozptylu pomocí odhadovaných statistik.
- metoda Bootstrap, využívající převzorkování dat a vývoj souboru modelů.
výpočet intervalu predikce můžeme provést konkrétním příkladem v další části.
Predikční Interval pro Lineární Regrese
lineární regrese je model, který popisuje lineární kombinace vstupů pro výpočet výstupní proměnné.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
neznáme skutečné hodnoty koeficientů b0 A b1. My také nevíme, jaký je skutečný populační parametry jako je průměr a směrodatná odchylka pro x nebo y. Všechny tyto prvky musí být odhadnuta, který zavádí nejistotu v použití modelu tak, aby předpovědi.
můžeme udělat nějaké předpoklady, jako je rozdělení x a y a predikce chyb modelu, tzv. rezidua, jsou Gaussovské.
interval predikce kolem yhat lze vypočítat následovně:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
v praxi to nevíme. Objektivní odhad předpokládané směrodatné odchylky můžeme vypočítat následujícím způsobem (převzato z přístupů strojového učení pro odhad predikčního intervalu pro výstup modelu):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
zpracovaný příklad
udělejme konkrétní případ intervalů predikce lineární regrese pomocí zpracovaného příkladu.
za Prvé, pojďme se definovat jednoduchý dva-variabilní datový soubor, kde výstupní proměnná (y) závisí na vstupní proměnné (x), s některými Gaussova šumu.
níže uvedený příklad definuje datovou sadu, kterou použijeme pro tento příklad.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# generovat související proměnné
od numpy import
od numpy import std
from numpy.random import randn
from numpy.random import seed
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# summarize
print(‚x: mean=%.3f stdv=%.3f‘ % (mean(x), std(x)))
print(‚y: mean=%.3f stdv=%.3f‘ % (mean(y), std(y)))
# plot
pyplot.scatter(x, y)
pyplot.show()
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
děj údajů je pak vytvořen.
můžeme vidět jasný lineární vztah mezi proměnnými s šířením bodů zvýrazňujících šum nebo náhodnou chybu ve vztahu.
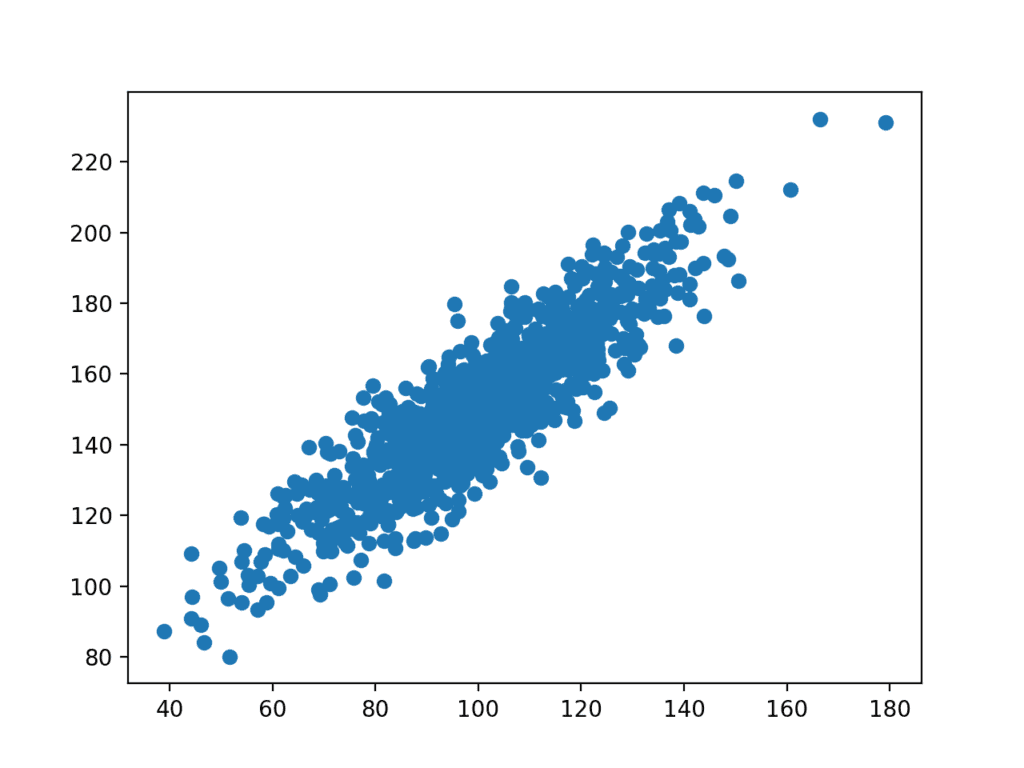
Bodový graf Souvisejících Proměnných,
Next, můžeme vytvořit jednoduché lineární regrese, že s ohledem na vstupní proměnné x, bude předpovídat y proměnné. Můžeme použít funkci linregress () SciPy pro přizpůsobení modelu a vrácení koeficientů b0 A b1 pro model.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# jednoduché nelineární regresní model
od numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(‚b0=%.3f, b1=%.3f‘ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r‘)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
b0=1.011, b1=49.117
|
koeficienty jsou pak použity s vstupy z datového souboru, aby se předpověď. Výsledné vstupy a předpokládané hodnoty y jsou vyneseny jako čára na horní straně rozptylového grafu pro datovou sadu.
můžeme jasně vidět, že model se naučil základní vztah v datovém souboru.
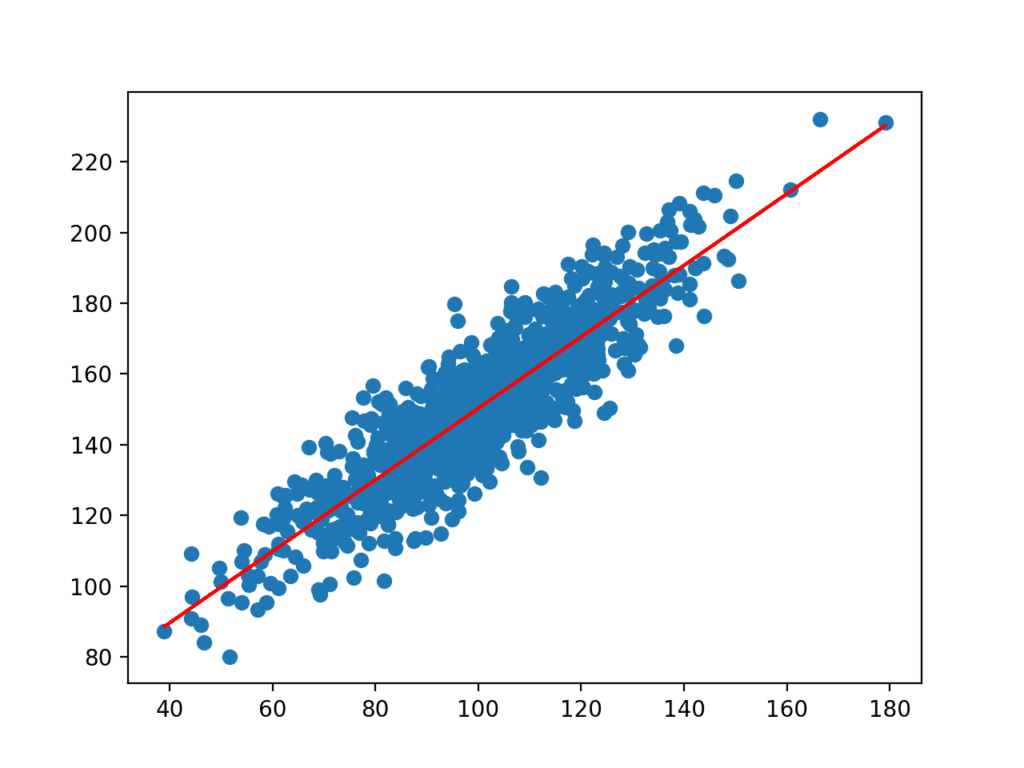
Bodový graf z datové sady s-Line pro Jednoduchý Lineární Regresní Model,
nyní Jsme připraveni, aby se předpověď s naší jednoduché lineární regresní model a přidat predikční interval.
model se vejde jako dříve. Tentokrát vezmeme jeden vzorek z datové sady, abychom demonstrovali interval predikce. Použijeme vstup k vytvoření predikce, výpočtu intervalu predikce pro predikci a porovnání predikce a intervalu se známou očekávanou hodnotou.
nejprve definujeme vstupní, Predikční a očekávané hodnoty.
|
1
2
3
|
x_in = x
y_out = y
yhat_out = to
|
Next, můžeme odhadnout standardní zakřivení v predikci směru.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.statistiky import linregress
od matplotlib pyplot import
# semínko generátoru náhodných čísel
semeno(1)
# připravte se na data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit nelineární regresní model
b1, b0, r_value, p_value, std_err = linregress(x, y)
značka# předpovědi
to = b0 + b1 * x
# define nový vstup, očekávané hodnoty a predikce
x_in = x
y_out = y
yhat_out = to
# odhad funkce smodch. výběr z to
sum_errs = arraysum((y – to)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
# výpočet predikce intervalu
interval = 1.96 * smodch. výběr
print(‚Predikční Interval: %.3f‘ % interval)
dolní, horní = yhat_out – interval, yhat_out + interval
print(‚95%% pravděpodobnost, že skutečná hodnota je mezi %.3f a %.3F ‚ % (dolní, horní))
print (‚True value:%.3f ‚ % y_out)
# plot dataset a predikce s intervalem
pyplot.scatter (x, y)
pyplot.plot (x, yhat, color=’red‘)
pyplot.errorbar(x_in, yhat_out, yerr=interval, color=’black‘, fmt=’o‘)
pyplot.show()
|
spuštění například odhaduje, že směrodatná odchylka a pak vypočítá predikční interval.
po výpočtu se uživateli zobrazí interval predikce pro danou vstupní proměnnou. Protože jsme tento příklad vymysleli, známe skutečný výsledek, který také zobrazujeme. Vidíme, že v tomto případě 95% interval predikce pokrývá skutečnou očekávanou hodnotu.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
Na pozemku je také vytvořen ukazuje syrové dataset jako bodový graf, předpovědi pro dataset jako červená linie, a predikce a predikční interval jako černé tečky a linie, resp.
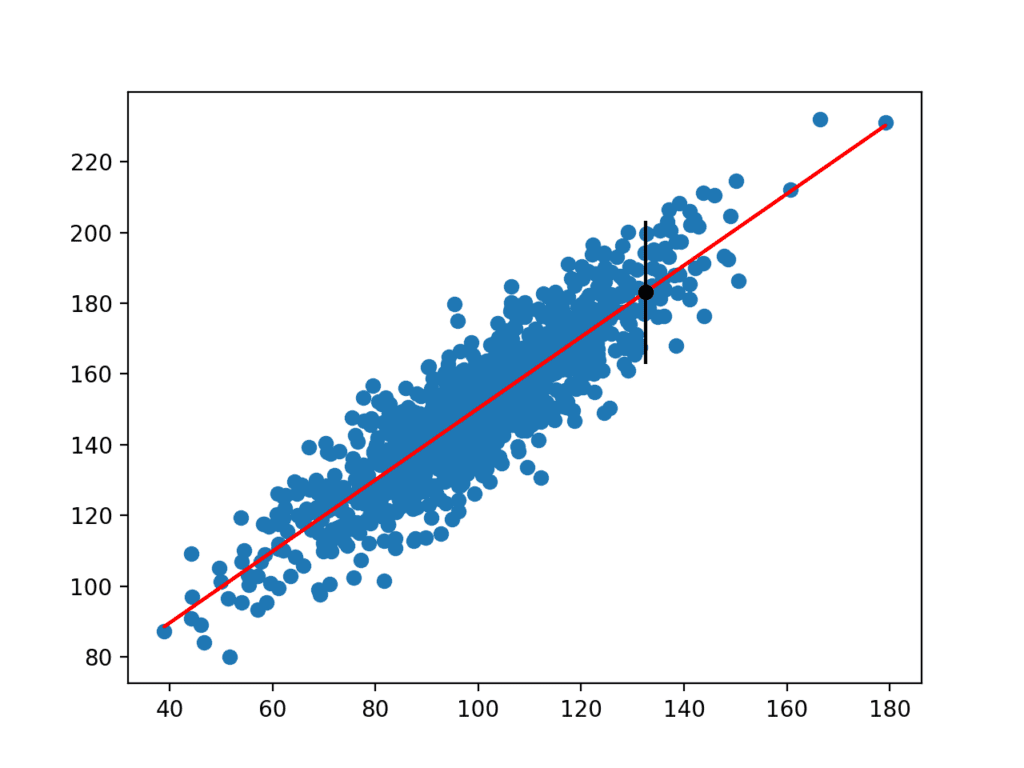
Bodový graf z Dataset S Lineárním Modelu a Predikce Intervalu
Rozšíření
Tento oddíl uvádí některé nápady pro rozšíření kurzu, které možná budete chtít prozkoumat.
- shrňte rozdíl mezi intervaly tolerance, spolehlivosti a predikce.
- Vytvořte lineární regresní model pro standardní datovou sadu strojového učení a vypočítejte intervaly predikce pro malou testovací sadu.
- podrobně popište, jak funguje jedna metoda nelineárního intervalu predikce.
pokud prozkoumáte některé z těchto rozšíření, rád bych to věděl.
další čtení
tato část poskytuje více zdrojů k tématu, pokud chcete jít hlouběji.
Příspěvky
- Jak Hlásit Klasifikátor Výkon s Intervaly Spolehlivosti
- Jak Vypočítat Intervaly Spolehlivosti Bootstrapem Pro Strojové Učení Výsledky v Pythonu
- Pochopit Časové Řady Předpověď Nejistoty Pomocí Intervalů Spolehlivosti s Python
- Odhad Počtu Experiment Opakuje pro Stochastické Algoritmy Strojového Učení
Knihy
- Pochopení Nové Statistiky: Vliv Velikosti, Intervaly Spolehlivosti, a Meta-Analýzy, do roku 2017.
- statistické intervaly: průvodce pro odborníky a výzkumné pracovníky, 2017.
- Úvod do statistického učení: s aplikacemi v R, 2013.
- Úvod do nové statistiky: Estimation, Open Science, and Beyond, 2016.
- Forecasting: principles and practice, 2013.
Dokumenty
- srovnání některých odhadů chyb pro neuronové sítě, modely, 1995.
- Machine learning approaches for estimation of prediction interval for the model output, 2006.
- komplexní přehled předpovědních intervalů založených na neuronových sítích a nových pokroků, 2010.
API
- scipy.statistik.linregress () API
- matplotlib.pyplot.scatter () API
- matplotlib.pyplot.errorbar() API
Články
- Odhad intervalu na Wikipedii
- Bootstrap predikční interval na Kříž Ověřena
Shrnutí
V tomto tutoriálu, se objevil predikční interval a jak to spočítat pro jednoduchý model lineární regrese.
konkrétně jste se dozvěděli:
- že interval predikce kvantifikuje nejistotu předpovědi jednoho bodu.
- že intervaly predikce mohou být odhadnuty analyticky pro jednoduché modely, ale jsou náročnější pro nelineární modely strojového učení.
- jak vypočítat interval predikce pro jednoduchý lineární regresní model.
máte nějaké dotazy?
zeptejte se v komentářích níže a já se budu snažit odpovědět.
Získejte přehled o statistikách pro strojové učení!

rozvíjejí funkční porozumění statistice
…o psaní řádků kódu v pythonu
Zjistit, jak můj nový Ebook:
Statistické Metody Strojového Učení
To poskytuje self-studovat návody na témata, jako jsou:
Hypotéza Testy, Korelace, Neparametrické Statistiky, Převzorkování, a mnohem více…
Objevte, jak transformovat Data do znalostí
přeskočte akademiky. Jen Výsledky.
podívejte se, co je uvnitř