VMware High Availability (HA) je nástroj, který eliminuje potřebu vyhrazeného pohotovostním hardwaru a softwaru ve virtualizovaném prostředí. VMware HA se často používá ke zlepšení spolehlivosti, snížení prostojů ve virtuálních prostředích a zlepšení obnovy po havárii / kontinuity podnikání.
tato kapitola výňatek z zkoušky VCP4 Cram: VMware Certified Professional, 2nd Edition Elias Khnaser zkoumá osvědčené postupy VMware HA.
VMware High Availability se zabývá především selháním hostitele ESX/ESXi a tím, co se stane s virtuálními počítači (VM), které jsou spuštěny na tomto hostiteli. HA může také sledovat a restartovat VM kontrolou, zda jsou nástroje VMware stále spuštěny. Když hostitel ESX / ESXi z jakéhokoli důvodu selže, všechny běžící VM také selžou. VMware HA zajišťuje, že virtuální počítače z neúspěšného hostitele mohou být restartovány na jiných hostitelích ESX / ESXi.
mnoho lidí mylně zaměňuje VMware HA s odolností proti chybám. VMware HA není tolerantní k chybám v tom, že pokud hostitel selže, VM na něm také selžou. HA se zabývá pouze restartováním těchto virtuálních počítačů na jiných hostitelích ESX/ESXi s dostatkem zdrojů. Odolnost proti chybám na druhé straně poskytuje nepřerušitelný přístup ke zdrojům v případě selhání hostitele.
 klikněte na obrázek obálky knihy výše
klikněte na obrázek obálky knihy výše a stáhněte si celou kapitolu Eliase Khnasera
o zálohování a vysoké dostupnosti.
VMware HA udržuje komunikační kanál se všemi ostatními ESX/ESXi, které jsou členy stejného clusteru pomocí srdeční rytmus, který se vysílá každou 1 sekundu v vSphere 4.0 nebo každých 10 sekund, v vSphere 4.1 ve výchozím nastavení. Když serveru ESX chybí tlukot srdce, ostatní hostitelé čekají 15 sekund, než druhý hostitel znovu odpoví. Po 15 sekundách cluster zahájí restart VM na selhávajícím hostiteli ESX / ESXi na zbývajících hostitelích ESX / ESXi v clusteru. VMware HA také neustále sleduje ESX/ESXi, které jsou členy clusteru a zajišťuje, že zdroje jsou vždy k dispozici k uspokojení požadavků v případě selhání hostitele.
monitorování selhání virtuálního stroje
monitorování selhání virtuálního stroje je technologie, která je ve výchozím nastavení zakázána. Jeho funkcí je monitorovat virtuální stroje, které dotazuje každých 20 sekund pomocí srdečního rytmu. Dělá to pomocí nástrojů VMware, které jsou nainstalovány uvnitř VM. Když VM chybí tep, VMware HA považuje tento VM za neúspěšný a pokusí se jej resetovat. Myslete na monitorování selhání virtuálního stroje jako na vysokou dostupnost pro VM.
monitorování selhání virtuálního stroje může zjistit, zda byl virtuální stroj ručně vypnutý, pozastaven nebo migrován, a proto se jej nepokouší restartovat.
VMware HA konfigurace předpoklady
HA vyžaduje následující konfiguraci předpoklady před tím, než může správně fungovat:
- vCenter: Protože VMware HA je enterprise-class funkce, to vyžaduje vCenter před tím, než může být povoleno.
- rozlišení DNS: všichni hostitelé ESX / ESXi, kteří jsou členy klastru HA, musí být schopni vyřešit jeden druhého pomocí DNS.
- přístup ke sdílenému úložišti: všichni hostitelé v klastru HA musí mít přístup a viditelnost ke stejnému sdílenému úložišti; jinak by neměli přístup k VM.
- přístup do stejné sítě: Všichni hostitelé ESX / ESXi musí mít stejné sítě nakonfigurované na všech hostitelích, takže při restartování VM na jakémkoli hostiteli má opět přístup ke správné síti.
redundance servisní konzole
doporučená praxe určuje, že servisní konzole (SC) má redundanci. VMware HA si stěžuje a vydá varování, pokud zjistí, že servisní konzola je nakonfigurována na vSwitch pouze s jedním vmnic. Jak ukazuje obrázek 1, můžete nakonfigurovat redundanci servisní konzoly jedním ze dvou způsobů:
- vytvořte dvě skupiny portů servisní konzoly, každá na jiném přepínači vSwitch.
- přiřaďte dvě karty fyzického síťového rozhraní (nic) ve formě týmu NIC do servisní konzole vSwitch.
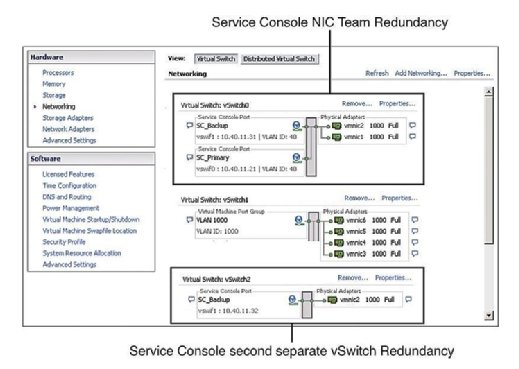
V obou případech, musíte nakonfigurovat celou IP stack s IP adresu, masku podsítě a bránu. Servisní konzole vSwitches se používají pro srdeční tep a synchronizaci stavu a používají následující porty:
- Příchozí TCP port 8042
- Příchozí UDP port 8045
- Odchozí port TCP roku 2050
- Odchozí UDP port 2250
- Příchozí TCP port 8042-8045
- Příchozí UDP port 8042-8045
- Odchozí TCP port 2050-2250
- Odchozí UDP port 2050-2250
Selhání konfigurace SC redundance výsledky v varovná zpráva při povolení HA. Chcete-li se vyhnout zobrazení této chybové zprávy a dodržovat osvědčené postupy, nakonfigurujte SC tak, aby byl nadbytečný.
plánování kapacity převzetí služeb při selhání hostitele
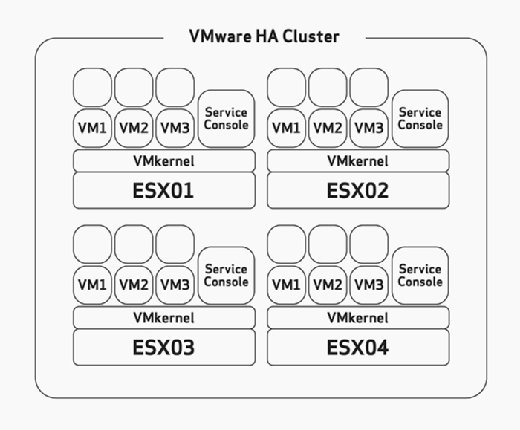
při konfiguraci HA musíte ručně nakonfigurovat maximální toleranci selhání hostitele. To je úkol, který byste měli zamyšleně zvážit během hardwarové velikosti a plánovací fáze vašeho nasazení. To by předpokládalo, že jste postavili své hostitele ESX / ESXi s dostatkem zdrojů pro provoz více VM, než bylo plánováno, aby bylo možné ubytovat HA. Například, na Obrázku 2 si všimněte, že HA clusteru má čtyři ESX, a že všechny tyto čtyři hostitelé mají dostatečnou kapacitu, aby spustit alespoň tři další VMs. Protože všichni jsou již běží tři VMs, to znamená, že tento cluster může dovolit ztrátu dvou ESX/ESXi, protože zbývající dva ESX/ESXi můžete napájení na šest nepodařilo VMs s žádný problém, pokud dojde k selhání.
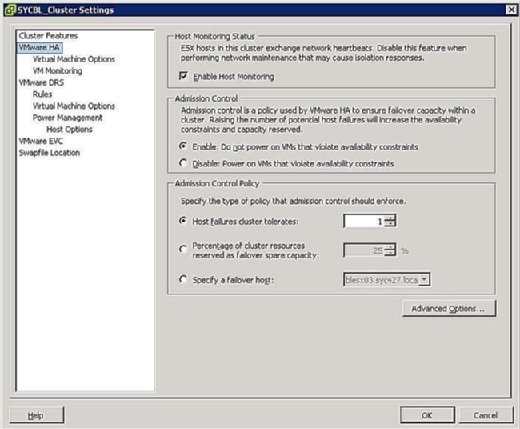
v Průběhu konfigurační fáze HA clusteru, zobrazí se obrazovka podobná té na Obrázku 3, které vás vyzve k definování dvou clusterwide konfigurace takto:
- stav monitorování hostitele:
- povolit monitorování hostitele: toto nastavení umožňuje řídit, zda má klastr HA monitorovat hostitele pro srdeční tep. Toto je způsob, jak cluster zjistit, zda je hostitel stále aktivní. V některých případech, když provádíte úkoly údržby na hostiteli ESX / ESXi, může být žádoucí tuto možnost deaktivovat, aby nedošlo k izolaci hostitele.
- kontrola přijetí:
- povolit: nezapínejte VMs, které porušují omezení dostupnosti: Výběr této možnosti znamená, že pokud nejsou k dispozici žádné zdroje pro uspokojení VM, nemělo by být zapnuto.
- Disable: zapnutí VMs, které porušují omezení dostupnosti: Výběrem této možnosti znamená, že bys měl moc na VM i když budete muset nevyvážený zdrojů.
- zásady řízení přijetí:
- klastr selhání hostitele toleruje: toto nastavení umožňuje nastavit, kolik selhání hostitele chcete tolerovat. Povolená nastavení jsou 1 až 4.
- procento zdrojů clusteru vyhrazených jako volná kapacita při selhání: Výběr této možnosti znamená, že rezervujete procento z celkových zdrojů clusteru v rezervě pro převzetí služeb při selhání. V klastru se čtyřmi hostiteli rezervace 25% znamená, že zrušíte úplného hostitele pro převzetí služeb při selhání. Pokud chcete vyčlenit méně, můžete místo toho zvolit 10% zdrojů klastru.
- Určete hostitele převzetí služeb při selhání: volba této možnosti znamená, že v klastru vybíráte konkrétního hostitele jako hostitele převzetí služeb při selhání. To může být případ, pokud máte náhradního hostitele nebo máte konkrétního hostitele, který má k dispozici podstatně více výpočetních a paměťových zdrojů.
Host izolace
síť jev známý jako split-brain nastane, když ESX/ESXi host se zastavil přijímání srdce od zbytku clusteru. Tep je dotazován na každou sekundu ve vSphere 4.0 nebo 10 sekund ve vSphere 4.1. Pokud odpověď není přijata, cluster si myslí, že hostitel ESX / ESXi selhal. Když k tomu dojde, hostitel ESX / ESXi ztratil síťové připojení na svém rozhraní pro správu. Hostitel může být stále v provozu a virtuální počítače nemusí být ovlivněny ani vzhledem k tomu, že mohou používat jiné síťové rozhraní, které nebylo ovlivněno. VSphere však musí podniknout kroky, když k tomu dojde, protože věří, že hostitel selhal. Na to přijde, byla vytvořena odpověď izolace hostitele. Host isolation response je způsob HA, jak se vypořádat s hostitelem ESX / ESXi, který ztratil síťové připojení.
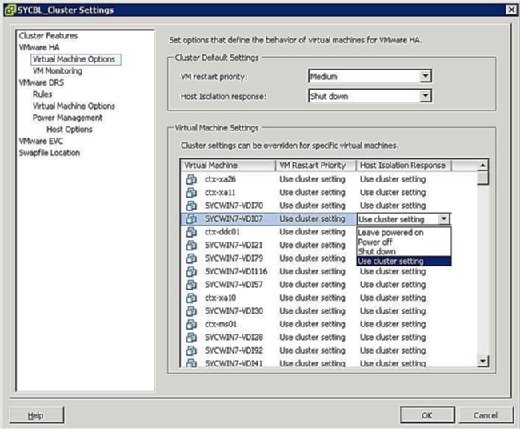
můžete řídit, co se stane s VMs v případě izolace hostitele. Chcete-li se dostat na obrazovku odpovědi na izolaci VM, klepněte pravým tlačítkem myši na dotyčný cluster a klikněte na Upravit nastavení. Poté můžete kliknout na možnosti virtuálního počítače pod bannerem VMware HA v levém podokně. Možnosti clusterwide můžete ovládat nastavením odpovědi izolace hostitele odpovídajícím způsobem. To platí pro všechny VM na postiženém hostiteli. To bylo řečeno, vždy můžete přepsat nastavení clusteru definováním jiné odpovědi na úrovni VM.
, Jak je znázorněno na Obrázku 4, Izolace Reakci možnosti jsou následující:
- Nechte zapnutý: Jak označení napovídá, toto nastavení znamená, že v případě, že host izolace, VM zůstává zapnutý.
- vypnutí: toto nastavení definuje, že v případě izolace je VM vypnutý. Tohle je těžké vypnutí.
- vypnout: toto nastavení definuje, že v případě izolace se VM elegantně vypne pomocí nástrojů VMware. Pokud tento úkol není úspěšně dokončen do pěti minut, okamžitě se provede vypnutí. Pokud VMware Tools není nainstalován, místo toho se provede vypnutí.
- použijte nastavení clusteru: toto nastavení předá úlohu nastavení clusterwide definovanému v okně zobrazeném dříve na obrázku 4.
V případě izolace to nutně neznamená, že hostitel je nefunkční. Vzhledem k tomu, že VM mohou být nakonfigurovány s různými fyzickými nic a připojeny k různým sítím, mohou i nadále fungovat správně; proto je třeba to zvážit při nastavování priority izolace. Když je hostitel izolován, znamená to jednoduše, že jeho servisní konzola nemůže komunikovat se zbytkem hostitelů ESX / ESXi v clusteru.
Priorita obnovení virtuálního počítače
Pokud váš klastr HA nebude schopen pojmout všechny VM v případě selhání, máte možnost upřednostnit VM. Priority určují, které VM jsou restartovány jako první a které VM nejsou v případě nouze tak důležité. Tyto možnosti jsou konfigurovány na stejné obrazovce jako izolační odpověď uvedená v předchozí části. Můžete nakonfigurovat nastavení clusterwide, která budou použita pro všechny virtuální počítače na postiženém hostiteli, nebo můžete přepsat nastavení clusteru konfigurací přepsání na úrovni VM.
můžete nastavit, VM je restart prioritu jedním z následujících způsobů:
- Vysoká: VMs s vysokou prioritou jsou znovu první.
- Medium: toto je výchozí nastavení.
- Low: virtuální počítače s nízkou prioritou jsou restartovány jako poslední.
- Použití Clusteru Nastavení: VMs jsou restartován na základě nastavení definovaných v clusteru úrovni definované v okně zobrazeném na obrázku níže.
- zakázáno: VM se nezapne.
priorita by měla být nastavena na základě důležitosti VMs. Jinými slovy, možná budete chtít restartovat řadiče domény a nerestartovat tiskové servery. Virtuální stroje s vyšší prioritou jsou nejprve restartovány. VM, které mohou tolerovat zbývající vypnuté v případě nouze, by měly být nakonfigurovány tak, aby zůstaly vypnuté, aby šetřily zdroje.
MSCs clustering
hlavním účelem clusteru je zajistit, aby kritické systémy zůstaly online za každou cenu a za všech okolností. Podobné k fyzické stroje, které mohou být clustery, virtuální stroje mohou být také seskupeny s ESX pomocí tří různých scénářů:
- Cluster-in-a-box: V tomto scénáři, všechny VMs, které jsou součástí clusteru jsou umístěny na stejné hostitele ESX/ESXi. Jak jste možná uhodli, okamžitě se vytvoří jediný bod selhání: hostitel ESX/ESXi. Pokud jde o sdílené úložiště, můžete v tomto scénáři použít virtuální disky jako sdílené úložiště nebo můžete použít mapování zařízení Raw (RDM) v režimu virtuální kompatibility.
- Cluster-přes-boxy: V tomto scénáři uzly clusteru (VMs, které jsou členy klastru) jsou umístěny na více ESX/ESXi, přičemž každý z uzlů, které tvoří clusteru můžete přistupovat stejné úložiště tak, že pokud jeden VM selže, ostatní mohou nadále fungovat a přistupovat ke stejným datům. Tento scénář vytváří ideální prostředí klastru tím, že eliminuje jediný bod selhání. Sdílené úložiště je předpokladem a musí být umístěno na Fibre Channel SAN. RDM musíte také použít ve fyzickém nebo virtuálním režimu kompatibility, protože virtuální disky nejsou podporovanou konfigurací pro sdílené úložiště. Přičemž každý z uzlů, které tvoří cluster, má přístup ke stejnému úložišti, takže pokud jeden VM selže, druhý může nadále fungovat a přistupovat ke stejným datům.
- physical-to-virtual cluster: V tomto scénáři je jeden člen klastru virtuální stroj, zatímco druhý člen je fyzický stroj. Sdílené úložiště je v tomto scénáři předpokladem a musí být nakonfigurováno jako RDM v režimu fyzické kompatibility.
kdykoli navrhujete clusterové řešení, musíte řešit problém sdíleného úložiště, které by umožnilo více hostitelům nebo VM přístup ke stejným datům. vSphere nabízí několik metod, pomocí kterých můžete poskytnout sdílené úložiště následujícím způsobem:
- virtuální disky: Virtuální disk můžete použít jako sdílený úložný prostor pouze v případě, že děláte Shlukování v krabici-jinými slovy, pouze pokud jsou oba VM umístěny na stejném hostiteli ESX / ESXi.
- RDM v režimu fyzické kompatibility: tento režim umožňuje připojit fyzický LUN přímo do VM nebo fyzického stroje. Tento režim vám brání v používání funkcí, jako jsou snímky, a je ideálně používán, když jeden člen clusteru je fyzický stroj, zatímco druhý je VM.
- RDM v režimu virtuální kompatibility: tento režim umožňuje připojit fyzický LUN přímo do VM nebo fyzického stroje. Tento režim vám poskytuje všechny výhody virtuálních disků běžících na VMFS, včetně snímků a pokročilého zamykání souborů. Disk je přístupný přes hypervizor a je ideální při konfiguraci scénáře clusteru napříč boxy, kde je třeba dát oběma VM přístup ke sdílenému úložišti.
v době psaní tohoto článku je jedinou službou clusteru podporovanou VMware Microsoft Clustering Services (MSCS). Můžete se podívat na VMware white paper “ nastavení pro Clustering při selhání a Microsoft Cluster Service.“
VMware Fault Tolerance
VMware Fault Tolerance (FT) je další forma VM clustering vyvinutý VMware pro systémy, které vyžadují extrémní provozuschopnost. Jednou z nejpřesvědčivějších funkcí FT je jeho snadné nastavení. FT je jednoduše zaškrtávací políčko, které lze povolit. Ve srovnání s tradičním shlukováním, které vyžaduje specifické konfigurace a v některých případech kabeláž, FT je jednoduchý, ale výkonný.
jak to funguje?
při ochraně VMs pomocí FT se vytvoří sekundární VM v lockstep chráněného VM, prvního VM. FT pracuje tak, že současně zapisuje do prvního VM a druhého VM současně. Každý úkol je napsán dvakrát. Pokud kliknete na nabídku Start na prvním VM, klikne se také na nabídku Start na druhém VM. Síla FT je jeho schopnost udržet oba VM v synchronizaci.
Pokud chráněné VM měla jít dolů z nějakého důvodu, sekundární VM ihned má své místo, zajištění jeho totožnosti a jeho IP adresa, pokračování uživatele služeb bez přerušení. Nově podporovaný chráněný VM pak vytvoří sekundární pro sebe na jiném hostiteli a cyklus se restartuje.
pro objasnění se podívejme na příklad. Pokud jste chtěli chránit Exchange server, můžete povolit FT. Pokud z nějakého důvodu selže hostitel ESX/ESXi, který nese chráněný VM, sekundární VM nastoupí a převezme své povinnosti bez přerušení provozu.
níže uvedená tabulka popisuje různé technologie vysoké dostupnosti a shlukování, ke kterým máte přístup pomocí vSphere, a zdůrazňuje jejich omezení.

Chyba Tolerance požadavky
Fault Tolerance se nijak neliší od jakéhokoli jiného podniku rys v tom, že to vyžaduje určité předpoklady, které musí být splněny předtím, než tato technologie může fungovat správně a efektivně. Tyto požadavky jsou uvedeny v následujícím seznamu a jsou členěny do různých kategorií, které vyžadují zvláštní minimální požadavky:
- Host požadavky:
- FT-kompatibilní CPU. Další informace naleznete v tomto článku VMware KB.
- v systému bios musí být povolena virtualizace hardwaru.
- rychlost procesoru hostitele musí být v rozmezí 400 MHz od sebe.
- VM požadavky:
- VM musí být umístěny na podporovaném sdíleném úložišti (FC, iSCSI a NFS).
- VMs musí spustit podporovaný operační systém.
- VM musí být uloženy v VMDK nebo virtuálním RDM.
- VMs nemůže mít tence poskytnuté VMDK a musí používat virtuální disk Eagerzeroedthick.
- VMs nemůže mít nakonfigurováno více než jedno vCPU.
- požadavky clusteru:
- všichni hostitelé ESX / ESXi musí mít stejnou verzi a stejnou úroveň opravy.
- všichni hostitelé ESX / ESXi musí mít přístup k datovým obchodům a sítím VM.
- VMware HA musí být v clusteru povolen.
- každý hostitel musí mít nakonfigurován protokolování vMotion a FT.
- musí být také povolena kontrola certifikátu hostitele.
je velmi vhodné, že kromě kontroly procesor, kompatibilita s FT, zkontrolujte, zda váš server je značka a model kompatibility s FT proti VMware Hardware Compatibility List (HCL).
zatímco FT je skvělé řešení shlukování, je důležité si uvědomit, že má také určitá omezení. Například, FT VM nelze snapshotted, a nemohou být uloženy vMotioned. Ve skutečnosti budou tyto VM automaticky označeny jako DRS-zakázané a nebudou se podílet na dynamickém vyvažování zatížení zdrojů.
jak povolit FT
povolení FT není obtížné, ale zahrnuje konfiguraci několika různých nastavení. Pro fungování FT je třeba správně nakonfigurovat následující nastavení:
- povolit kontrolu certifikátu hostitele: Chcete-li toto nastavení povolit, přihlaste se k serveru vCenter a v nabídce Soubor klikněte na Správa a klikněte na Nastavení serveru vCenter. V levém podokně klikněte na Nastavení SSL a zaškrtněte políčko vCenter vyžaduje ověřené certifikáty SSL hostitele.
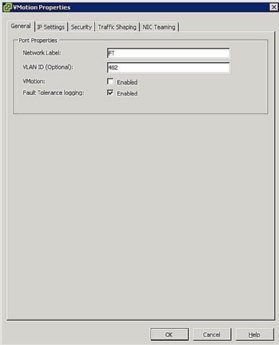
obrázek 5. Nastavení skupiny FT portů - Configure host Networking: Konfigurace sítě pro FT je snadná a sleduje stejné kroky a postupy jako vMotion, kromě toho, že místo zaškrtnutí políčka vMotion zaškrtněte políčko protokolování odolnosti proti chybám, jak je znázorněno na obrázku 5.
- zapnutí a vypnutí FT: jakmile splníte předchozí požadavky, můžete nyní zapnout a vypnout FT pro VM. Tento proces je také jednoduchý: Najděte VM, který chcete chránit, klepněte pravým tlačítkem myši na něj a vyberte možnost tolerance chyb>zapněte odolnost proti chybám.
Zatímco FT je první generace clustering technology, funguje to překvapivě dobře a zjednodušuje složitá tradiční metody budování, konfiguraci a udržování klastrů. FT je působivá technologie z hlediska dostupnosti a z hlediska bezproblémového převzetí služeb při selhání.