aktiveringsfunktioner er den mest afgørende del af ethvert neuralt netværk i dyb læring. I dyb læring er meget komplicerede opgaver billedklassificering, sprogtransformation, objektdetektering osv., som er nødvendige for at adressere ved hjælp af neurale netværk og aktiveringsfunktion. Så uden det er disse opgaver ekstremt komplekse at håndtere.
i nøddeskal er et neuralt netværk en meget potent teknik i maskinindlæring, der dybest set efterligner, hvordan en hjerne forstår, hvordan? Hjernen modtager stimuli, som input, fra miljøet, behandler det og producerer derefter output i overensstemmelse hermed.
introduktion
de neurale netværksaktiveringsfunktioner er generelt den mest betydningsfulde komponent i dyb læring, de bruges grundlæggende til at bestemme output fra dybe læringsmodeller, dens nøjagtighed og præstationseffektivitet af træningsmodellen, der kan designe eller opdele et neuralt netværk i stor skala.
aktiveringsfunktioner har efterladt betydelige effekter på neurale netværks evne til at konvergere og konvergenshastighed, vil du ikke hvordan? Lad os fortsætte med en introduktion til aktiveringsfunktionen, typer af aktiveringsfunktioner & deres betydning og begrænsninger gennem denne blog.
hvad er aktiveringsfunktionen?
aktiveringsfunktion definerer output af input eller sæt af input eller i andre termer definerer node af output af node, der er givet i input. De beslutter dybest set at deaktivere neuroner eller aktivere dem for at få det ønskede output. Det udfører også en ikke-lineær transformation på input for at få bedre resultater på et komplekst neuralt netværk.
aktiveringsfunktion hjælper også med at normalisere udgangen af enhver indgang i området mellem 1 til -1. Aktiveringsfunktionen skal være effektiv, og den skal reducere beregningstiden, fordi det neurale netværk undertiden trænes på millioner af datapunkter.
aktiveringsfunktion bestemmer grundlæggende i ethvert neuralt netværk, at givet input eller modtagelse af information er relevant, eller det er irrelevant. Lad os tage et eksempel for bedre at forstå, hvad der er en neuron, og hvordan aktiveringsfunktionen begrænser outputværdien til en vis grænse.
neuronen er dybest set et vægtet gennemsnit af input, så sendes denne sum gennem en aktiveringsfunktion for at få et output.
Y = liter (vægte*input + bias)
Her kan Y være alt for en neuron mellem rækkevidde-uendelig til +uendelig. Så vi er nødt til at binde vores output for at få den ønskede forudsigelse eller generaliserede resultater.
Y = aktiveringsfunktion (luth (vægte*input + bias))
så vi sender den neuron til aktiveringsfunktion til bundne outputværdier.
Hvorfor har vi brug for aktiveringsfunktioner?
uden aktiveringsfunktion ville vægt og bias kun have en lineær transformation, eller neuralt netværk er bare en lineær regressionsmodel, en lineær ligning er kun polynom af en grad, som er enkel at løse, men begrænset med hensyn til evne til at løse komplekse problemer eller højere grad polynomer.
men modsat det udfører tilføjelsen af aktiveringsfunktion til neuralt netværk den ikke-lineære transformation til input og gør den i stand til at løse komplekse problemer såsom sprogoversættelser og billedklassifikationer.
derudover er aktiveringsfunktioner differentierbare, som de let kan implementere bagudbredelser, optimeret strategi, mens de udfører backpropagationer for at måle gradienttabsfunktioner i de neurale netværk.
typer af aktiveringsfunktioner
de mest berømte aktiveringsfunktioner er angivet nedenfor,
-
binært trin
-
lineær
-
Sigmoid
-
Tanh
-
softmaks
1. Binær Trinaktiveringsfunktion
denne aktiveringsfunktion er meget grundlæggende, og det kommer til at tænke på hver gang, hvis vi forsøger at binde output. Det er dybest set en tærskelbaseklassifikator, i dette beslutter vi en tærskelværdi for at bestemme output, som neuron skal aktiveres eller deaktiveres.
f(H) = 1 if > 0 else 0 if < 0
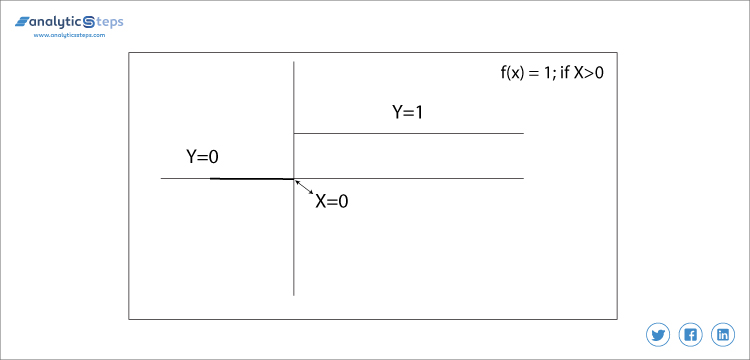
binær trinfunktion
i dette bestemmer vi tærskelværdien til 0. Det er meget enkelt og nyttigt at klassificere binære problemer eller klassifikator.
2. Lineær aktiveringsfunktion
det er en simpel retlinjeaktiveringsfunktion, hvor vores funktion er direkte proportional med den vægtede sum af neuroner eller input. Lineære aktiveringsfunktioner er bedre til at give en bred vifte af aktiveringer, og en linje med en positiv hældning kan øge fyringshastigheden, når indgangshastigheden øges.
i binær skyder enten en neuron eller ej. Hvis du kender gradientafstamning i dyb læring, vil du bemærke, at derivatet i denne funktion er konstant.
Y = m
hvor derivat med hensyn til Å er konstant m. betydningsgradienten er også konstant, og den har intet at gøre med Å. i dette, hvis ændringerne i backpropagation vil være konstante og ikke afhængige af Å, så dette vil ikke være godt for læring.
i dette er vores andet lag output fra en lineær funktion af tidligere lag input. Vent et øjeblik, hvad har vi lært i dette, at hvis vi sammenligner vores alle lagene og fjerner alle lagene undtagen det første og det sidste, så kan vi også kun få et output, som er en lineær funktion af det første lag.
3. ReLU (Rectified Linear unit) aktiveringsfunktion
korrigeret lineær enhed eller ReLU er den mest anvendte aktiveringsfunktion lige nu, som spænder fra 0 til uendelig, alle de negative værdier konverteres til nul, og denne konverteringsfrekvens er så hurtig, at den hverken kan kortlægge eller passe ind i data korrekt, hvilket skaber et problem, men hvor der er et problem, er der en løsning.
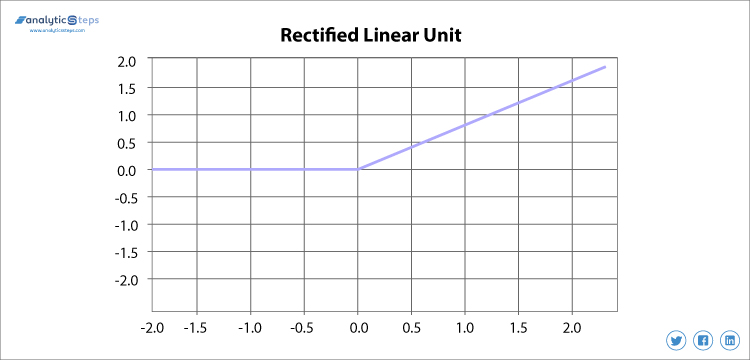
korrigeret lineær enhedsaktiveringsfunktion
Vi bruger utæt ReLU-funktion i stedet for ReLU for at undgå dette uegnet, i utæt ReLU-rækkevidde udvides, hvilket forbedrer ydeevnen.
utæt ReLU aktiveringsfunktion
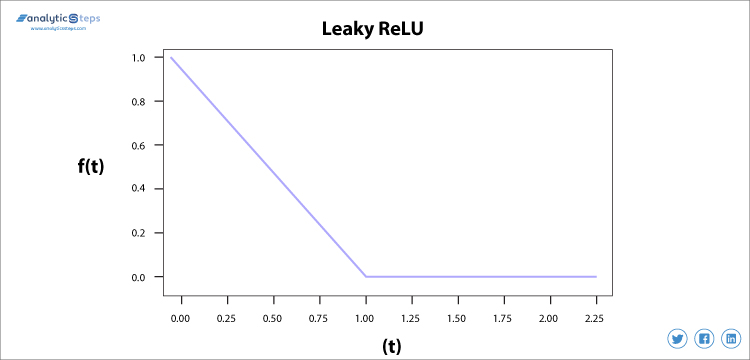
Leaky ReLU-aktiveringsfunktion
Vi havde brug for Leaky ReLU-aktiveringsfunktionen for at løse problemet ‘Dying ReLU’, som diskuteret i ReLU, bemærker vi, at alle de negative inputværdier bliver til nul meget hurtigt, og i tilfælde af Leaky ReLU laver vi ikke alle negative input til nul, men til en værdi tæt på nul, der løser det største problem med ReLU-aktiveringsfunktion.
sigmoid-aktiveringsfunktion
sigmoid-aktiveringsfunktionen bruges mest, da den udfører sin opgave med stor effektivitet, det er dybest set en sandsynlig tilgang til beslutningstagning og varierer mellem 0 og 1, så når vi skal træffe en beslutning eller forudsige et output, bruger vi denne aktiveringsfunktion på grund af området er minimum, derfor ville forudsigelsen være mere nøjagtig.
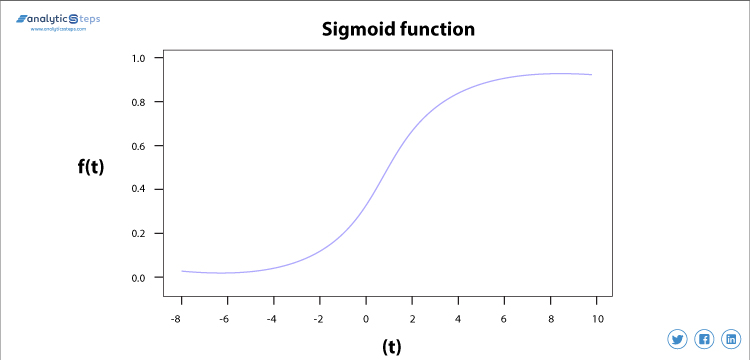
sigmoid aktiveringsfunktion
ligningen for sigmoid-funktionen er
f(H) = 1/(1+e (- H) )
sigmoid-funktionen forårsager et problem, der hovedsageligt betegnes som forsvindende gradientproblem, der opstår, fordi vi konverterer stort input mellem området 0 til 1, og derfor bliver deres derivater meget mindre, hvilket ikke giver tilfredsstillende output. For at løse dette problem bruges en anden aktiveringsfunktion som ReLU, hvor vi ikke har et lille derivatproblem.
hyperbolsk Tangentaktiveringsfunktion(Tanh)
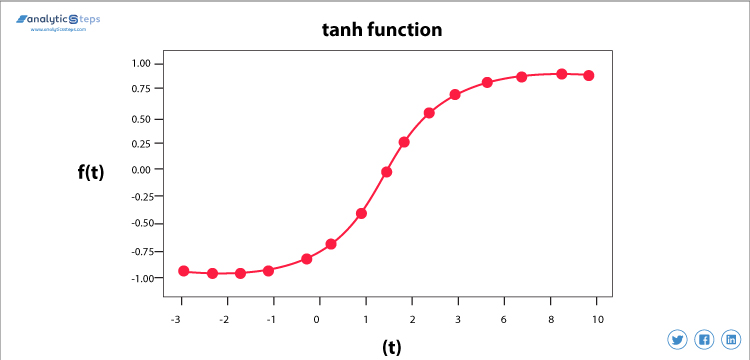
Tanh-aktiveringsfunktion
denne aktiveringsfunktion er lidt bedre end sigmoid-funktionen, ligesom sigmoid-funktionen bruges den også til at forudsige eller skelne mellem to klasser, men den kortlægger kun det negative input til negativ mængde og varierer mellem -1 til 1.
Softmaks aktiveringsfunktion
Softmaks bruges hovedsageligt i det sidste lag i.e output lag til beslutningstagning det samme som sigmoid aktivering værker, softmaks dybest set giver værdi til input variabel i henhold til deres vægt og summen af disse vægte er i sidste ende en.
Softmaks på binær klassificering
for binær klassificering er både sigmoid såvel som softmaks lige så tilgængelige, men i tilfælde af klassificeringsproblem i flere klasser bruger vi generelt softmaks og cross-entropi sammen med det.
konklusion
aktiveringsfunktionerne er de væsentlige funktioner, der udfører en ikke-lineær transformation til input og gør den dygtig til at forstå og udføre mere komplekse opgaver. Vi har diskuteret 7 hovedsageligt anvendte aktiveringsfunktioner med deres begrænsning (hvis nogen), disse aktiveringsfunktioner bruges til det samme formål, men under forskellige forhold.