hvad er forstærkning læring?
forstærkning læring er defineret som en maskine læring metode, der beskæftiger sig med, hvordan programmel agenter bør tage handlinger i et miljø. Forstærkning læring er en del af den dybe læringsmetode, der hjælper dig med at maksimere en del af den kumulative belønning.
denne neurale netværk læringsmetode hjælper dig med at lære at nå et komplekst mål eller maksimere en bestemt dimension over mange trin.
i forstærkning læring tutorial, vil du lære:
- hvad er forstærkning læring?
- vigtige udtryk, der anvendes i dyb forstærkning læringsmetode
- hvordan forstærkning læring værker?
- Forstærkningsindlæringsalgoritmer
- egenskaber ved Forstærkningsindlæring
- typer af Forstærkningsindlæring
- læringsmodeller for forstærkning
- Forstærkningsindlæring vs. overvåget læring
- anvendelser af Forstærkningsindlæring
- hvorfor bruge Forstærkningsindlæring?
- Hvornår skal man ikke bruge Forstærkningsindlæring?
- udfordringer ved Forstærkningslæring
vigtige udtryk anvendt i dyb Forstærkningslæringsmetode
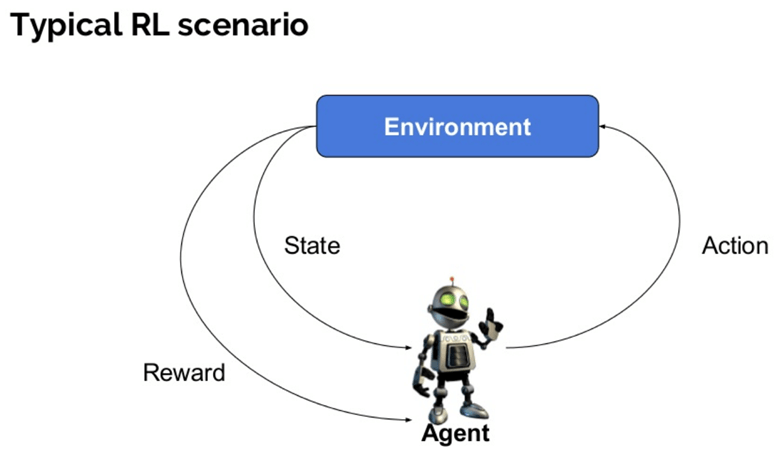
Her er nogle vigtige udtryk, der bruges i forstærkning AI:
- agent: det er en antaget enhed, der udfører handlinger i et miljø for at få en vis belønning.
- miljø (e): et scenario, som en agent skal stå over for.
- belønning (R): En øjeblikkelig tilbagevenden gives til en agent, når han eller hun udfører specifikke handling eller opgave.
- stat (er): Stat henviser til den aktuelle situation, der returneres af miljøet.
- politik (?): Det er en strategi, som agenten anvender til at beslutte den næste handling baseret på den aktuelle tilstand.
- værdi (V): Det forventes langsigtet afkast med rabat sammenlignet med den kortsigtede belønning.
- værdifunktion: den angiver værdien af en tilstand, der er det samlede beløb for belønning. Det er en agent, der bør forventes at starte fra denne stat.
- Model af miljøet: dette efterligner miljøets adfærd. Det hjælper dig med at gøre slutninger, der skal foretages, og også bestemme, hvordan miljøet vil opføre sig.
- modelbaserede metoder: det er en metode til løsning af forstærkningsindlæringsproblemer, der bruger modelbaserede metoder.
- k værdi eller handling værdi( K): K værdi er meget lig værdi. Den eneste forskel mellem de to er, at det tager en ekstra parameter som en aktuel handling.
hvordan forstærkning læring værker?
lad os se et simpelt eksempel, der hjælper dig med at illustrere forstærkningsindlæringsmekanismen.
overvej scenariet med at undervise nye tricks til din kat
- da cat ikke forstår engelsk eller noget andet menneskeligt sprog, kan vi ikke fortælle hende direkte, hvad hun skal gøre. I stedet følger vi en anden strategi.
- vi efterligner en situation, og katten forsøger at reagere på mange forskellige måder. Hvis kattens svar er den ønskede måde, vil vi give hende fisk.
- nu når katten udsættes for den samme situation, udfører katten en lignende handling med endnu mere entusiastisk i forventning om at få mere belønning(mad).
- det er som at lære, at katten får fra” hvad man skal gøre ” fra positive oplevelser.
- samtidig lærer katten også, hvad man ikke gør, når man står over for negative oplevelser.
forklaring om eksemplet:
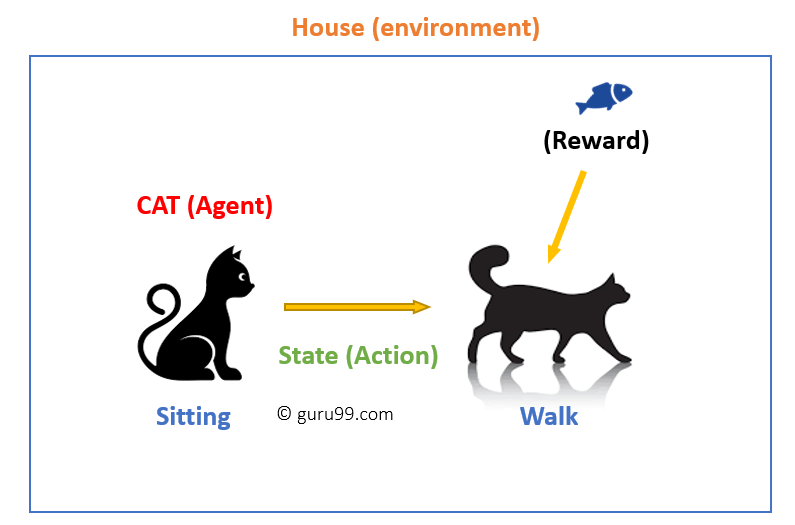
i dette tilfælde
- din kat er en agent, der udsættes for miljøet. I dette tilfælde er det dit hus. Et eksempel på en tilstand kunne være din kat sidder, og du bruger et bestemt ord i for kat til at gå.
- vores agent reagerer ved at udføre en handlingsovergang fra en “tilstand” til en anden “tilstand.”
- for eksempel går din kat fra at sidde til at gå.
- reaktionen af et middel er en handling, og politikken er en metode til at vælge en handling givet en tilstand i forventning om bedre resultater.
- efter overgangen kan de få en belønning eller straf til gengæld.
Forstærkningsindlæringsalgoritmer
der er tre tilgange til implementering af en Forstærkningsindlæringsalgoritme.
værdibaseret:
i en værdibaseret Forstærkningsindlæringsmetode skal du prøve at maksimere en værdifunktion V(s). I denne metode forventer agenten et langsigtet afkast af de nuværende stater under politik ?.
politikbaseret:
i en politikbaseret RL-metode forsøger du at komme med en sådan politik, at handlingen udført i hver stat hjælper dig med at opnå maksimal belønning i fremtiden.
to typer politikbaserede metoder er:
- deterministisk: for enhver stat produceres den samme handling af politikken ?.
- stokastisk: hver handling har en vis sandsynlighed, som bestemmes af følgende ligning.Stokastisk politik :
n{a\s) = P\A, = a\S, =S]
modelbaseret:
i denne Forstærkningsindlæringsmetode skal du oprette en virtuel model for hvert miljø. Agenten lærer at udføre i det specifikke miljø.
egenskaber ved Forstærkningslæring
Her er vigtige egenskaber ved forstærkningslæring
- Der er ingen vejleder, kun et reelt tal eller belønningssignal
- sekventiel beslutningstagning
- tid spiller en afgørende rolle i Forstærkningsproblemer
- Feedback er altid forsinket, ikke øjeblikkelig
- agentens handlinger bestemmer de efterfølgende data, den modtager
typer af Forstærkningslæring
to slags forstærkningsindlæringsmetoder er:
positive:
det er defineret som en begivenhed, der opstår på grund af specifik adfærd. Det øger styrken og hyppigheden af adfærd og påvirker positivt på agentens handling.
denne type forstærkning hjælper dig med at maksimere ydeevnen og opretholde ændringer i en længere periode. Imidlertid kan for meget forstærkning føre til overoptimering af staten, hvilket kan påvirke resultaterne.
negativ:
negativ forstærkning defineres som styrkelse af adfærd, der opstår på grund af en negativ tilstand, som burde have stoppet eller undgået. Det hjælper dig med at definere den mindste stand af ydeevne. Imidlertid, ulempen ved denne metode er, at den giver nok til at imødekomme den minimale adfærd.
læringsmodeller for forstærkning
der er to vigtige læringsmodeller i forstærkningslæring:
- Markov beslutningsproces
- k læring
Markov beslutningsproces
følgende parametre bruges til at få en løsning:
- sæt af handlinger – A
- sæt af stater-s
- belønning – r
- politik – n
- værdi – V
den matematiske tilgang til kortlægning af en løsning i forstærkningslæring er recon som en Markov-beslutningsproces eller (MDP).
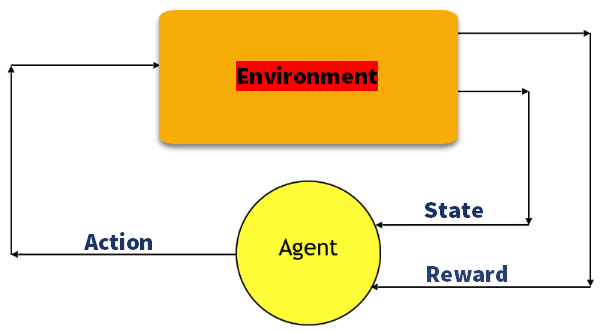
K-læring
K-læring er en værdibaseret metode til at levere information for at informere, hvilken handling en agent skal tage.
lad os forstå denne metode ved følgende eksempel:
- Der er fem værelser i en bygning, der er forbundet med døre.
- hvert værelse er nummereret 0 til 4
- bygningens yderside kan være et stort udvendigt område (5)
- døre nummer 1 og 4 fører ind i bygningen fra værelse 5
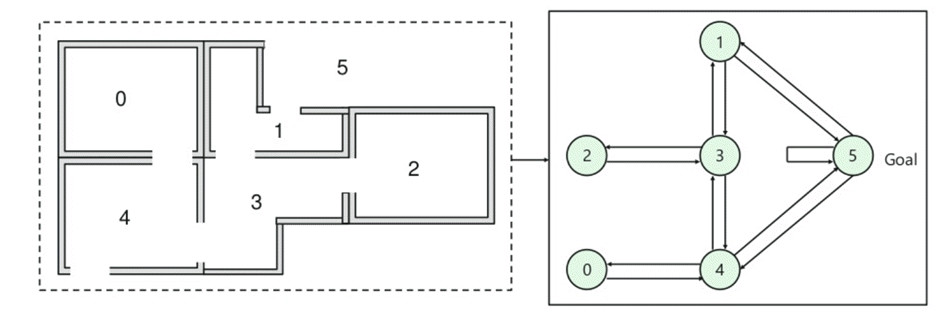
Dernæst skal du knytte en belønningsværdi til hver dør:
- døre, der fører direkte til målet, har en belønning på 100
- døre, der ikke er direkte forbundet til målrummet, giver nul belønning
- da døre er tovejs, og to pile tildeles for hvert værelse
- hver pil i ovenstående billede indeholder en øjeblikkelig belønningsværdi
forklaring:
På dette billede kan du se, at rummet repræsenterer en tilstand
agents bevægelse fra et rum til et andet repræsenterer en handling
i nedenstående billede beskrives en tilstand som en node, mens pilene viser handlingen.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Overvåget læring
| parametre | forstærkning læring | overvåget læring |
| Beslutningsstil | forstærkning læring hjælper dig med at tage dine beslutninger sekventielt. | i denne metode træffes en beslutning om input givet i begyndelsen. |
| arbejder på | arbejder på at interagere med miljøet. | arbejder på eksempler eller givne eksempeldata. |
| afhængighed af beslutning | i RL metode læring beslutning er afhængig. Derfor bør du give etiketter til alle de afhængige beslutninger. | overvåget læring de beslutninger, der er uafhængige af hinanden, så etiketter er givet for hver beslutning. |
| bedst egnet | understøtter og fungerer bedre i AI, hvor menneskelig interaktion er udbredt. | det er for det meste drives med et interaktivt system eller applikationer. |
| eksempel | skakspil | objektgenkendelse |
anvendelser af Forstærkningslæring
Her er anvendelser af Forstærkningslæring:
- robotik til industriel automatisering.
- forretningsstrategiplanlægning
- maskinindlæring og databehandling
- det hjælper dig med at oprette træningssystemer, der leverer tilpasset instruktion og materialer i henhold til kravene fra studerende.
- flystyring og robotbevægelseskontrol
hvorfor bruge Forstærkningslæring?
Her er de vigtigste grunde til at bruge Forstærkningslæring:
- det hjælper dig med at finde ud af, hvilken situation der har brug for en handling
- hjælper dig med at finde ud af, hvilken handling der giver den højeste belønning over den længere periode.
- Forstærkningslæring giver også læringsagenten en belønningsfunktion.
- det giver det også mulighed for at finde ud af den bedste metode til at opnå store belønninger.
Hvornår skal man ikke bruge Forstærkningslæring?
Du kan ikke anvende forstærkning læringsmodel er hele situationen. Her er nogle betingelser, når du ikke bør bruge forstærkning læringsmodel.
- når du har nok data til at løse problemet med en overvåget læringsmetode
- skal du huske, at forstærkning læring er computing-tung og tidskrævende. især når handlingsrummet er stort.
udfordringer ved Forstærkningslæring
Her er de største udfordringer, du står over for, mens du tjener forstærkning:
- funktion/belønningsdesign, som skal være meget involveret
- parametre kan påvirke læringshastigheden.
- realistiske miljøer kan have delvis observerbarhed.
- for meget forstærkning kan føre til en overbelastning af tilstande, der kan mindske resultaterne.
- realistiske miljøer kan være ikke-stationære.
Resume:
- Forstærkningslæring er en Maskinlæringsmetode
- hjælper dig med at finde ud af, hvilken handling der giver den højeste belønning over den længere periode.
- tre metoder til forstærkning læring er 1) værdibaseret 2) politikbaseret og modelbaseret læring.
- Agent, stat, belønning, miljø, Værdifunktionsmodel for miljøet, modelbaserede metoder, er nogle vigtige udtryk, der bruger i RL-læringsmetode
- eksemplet med forstærkningslæring er din kat er en agent, der udsættes for miljøet.
- det største kendetegn ved denne metode er, at der ikke er nogen vejleder, kun et reelt tal eller belønningssignal
- to typer forstærkningslæring er 1) Positiv 2) negativ
- to udbredte læringsmodeller er 1) Markov beslutningsproces 2) læring
- Forstærkningslæringsmetode fungerer på interaktion med miljøet, mens den overvågede læringsmetode fungerer på givne prøvedata eller eksempel.
- anvendelse eller forstærkning læringsmetoder er: Robotik til industriel automatisering og forretningsstrategiplanlægning
- du bør ikke bruge denne metode, når du har nok data til at løse problemet
- den største udfordring ved denne metode er, at parametre kan påvirke læringshastigheden