en forudsigelse fra et maskinindlæringsperspektiv er et enkelt punkt, der skjuler usikkerheden ved denne forudsigelse.
Forudsigelsesintervaller giver en måde at kvantificere og kommunikere usikkerheden i en forudsigelse. De adskiller sig fra konfidensintervaller, der i stedet søger at kvantificere usikkerheden i en populationsparameter såsom en middel-eller standardafvigelse. Forudsigelsesintervaller beskriver usikkerheden for et enkelt specifikt resultat.
i denne tutorial vil du opdage forudsigelsesintervallet, og hvordan du beregner det for en simpel lineær regressionsmodel.
Når du har gennemført denne tutorial, vil du vide:
- at et forudsigelsesinterval kvantificerer usikkerheden ved en enkelt punkts forudsigelse.
- at forudsigelsesintervaller kan estimeres analytisk for enkle modeller, men er mere udfordrende for ikke-lineære maskinindlæringsmodeller.
- Sådan beregnes forudsigelsesintervallet for en simpel lineær regressionsmodel.
kickstart dit projekt med min nye bog statistik for Machine Learning, herunder trin-for-trin tutorials og Python kildekode filer for alle eksempler.
lad os komme i gang.
- opdateret juni / 2019: korrigeret signifikansniveau som en brøkdel af standardafvigelser.
- opdateret Apr / 2020: fast skrivefejl i plot af forudsigelsesinterval.

Forudsigelsesintervaller for maskinlæring
foto af Jim Bendon, nogle rettigheder forbeholdes.
Tutorial Oversigt
denne tutorial er opdelt i 5 dele; de er:
- hvad er der galt med et Punktestimat?
- hvad er et Forudsigelsesinterval?
- Sådan beregnes et Forudsigelsesinterval
- Forudsigelsesinterval for lineær Regression
- arbejdet eksempel
brug for hjælp til statistik til maskinindlæring?
Tag mit gratis 7-dages e-mail-crashkursus nu (med prøvekode).
Klik for at tilmelde dig og også få en gratis PDF Ebook version af kurset.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.
|
hvor yhat er det estimerede resultat eller forudsigelse foretaget af den trænede model for de givne inputdata.
per definition er det et skøn eller en tilnærmelse og indeholder en vis usikkerhed.
usikkerheden kommer fra fejlene i selve modellen og støj i inputdataene. Modellen er en tilnærmelse af forholdet mellem inputvariablerne og outputvariablerne.
i betragtning af den proces, der bruges til at vælge og indstille modellen, vil det være den bedste tilnærmelse, der er givet tilgængelig information, men det vil stadig lave fejl. Data fra domænet vil naturligvis skjule det underliggende og ukendte forhold mellem input-og outputvariablerne. Dette vil gøre det til en udfordring at passe til modellen, og vil også gøre det til en udfordring for en fit-model at komme med forudsigelser.
i betragtning af disse to hovedkilder til fejl er deres punktforudsigelse fra en forudsigelig model utilstrækkelig til at beskrive forudsigelsens sande usikkerhed.
Hvad er et Forudsigelsesinterval?
et forudsigelsesinterval er en kvantificering af usikkerheden på en forudsigelse.
det giver en sandsynlig øvre og nedre grænse for estimatet af en resultatvariabel.
et forudsigelsesinterval for en enkelt fremtidig observation er et interval, der med en bestemt grad af tillid vil indeholde en fremtidig tilfældigt valgt observation fra en distribution.
— side 27, statistiske intervaller: en Guide til praktikere og forskere, 2017.
Forudsigelsesintervaller bruges oftest, når der foretages forudsigelser eller prognoser med en regressionsmodel, hvor en mængde forudsiges.
et eksempel på præsentationen af et forudsigelsesinterval er som følger:
givet en forudsigelse af ‘y’ givet ‘H’, er der en 95% sandsynlighed for, at intervallet ‘a’ til ‘b’ dækker det sande resultat.
forudsigelsesintervallet omgiver forudsigelsen foretaget af modellen og dækker forhåbentlig rækkevidden af det sande resultat.
diagrammet nedenfor hjælper med at visuelt forstå forholdet mellem forudsigelsen, forudsigelsesintervallet og det faktiske resultat.
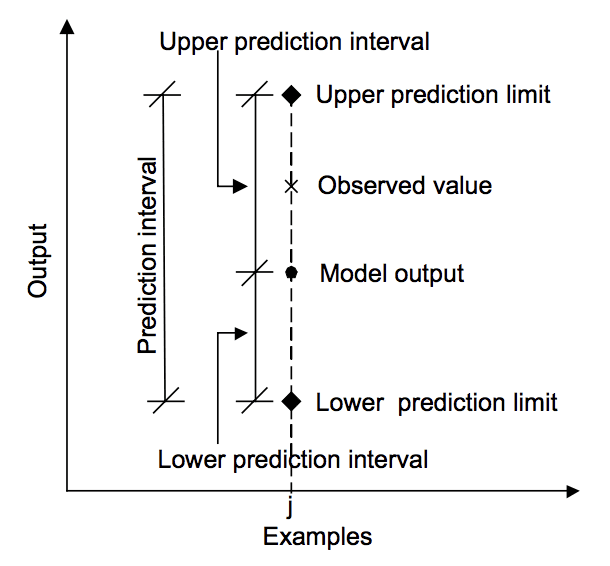
forholdet mellem forudsigelse, faktisk værdi og forudsigelsesinterval.
taget fra “Machine learning tilgange til estimering af forudsigelse interval for modellen output”, 2006.
et forudsigelsesinterval er forskelligt fra et konfidensinterval.
et konfidensinterval kvantificerer usikkerheden på en estimeret populationsvariabel, såsom middel-eller standardafvigelsen. Mens et forudsigelsesinterval kvantificerer usikkerheden på en enkelt observation estimeret fra befolkningen.
i forudsigelig modellering kan et konfidensinterval bruges til at kvantificere usikkerheden ved den estimerede færdighed i en model, mens et forudsigelsesinterval kan bruges til at kvantificere usikkerheden ved en enkelt prognose.
et forudsigelsesinterval er ofte større end konfidensintervallet, da det skal tage højde for konfidensintervallet og variansen i outputvariablen, der forudsiges.
Forudsigelsesintervaller vil altid være bredere end konfidensintervaller , fordi de tegner sig for usikkerheden forbundet med e, den irreducible fejl.
— side 103, en introduktion til statistisk læring: med applikationer i R, 2013.
Sådan beregnes et Forudsigelsesinterval
et forudsigelsesinterval beregnes som en kombination af den estimerede varians af modellen og variansen af resultatvariablen.
Forudsigelsesintervaller er lette at beskrive, men vanskelige at beregne i praksis.
i enkle tilfælde som lineær regression kan vi estimere forudsigelsesintervallet direkte.
i tilfælde af ikke-lineære regressionsalgoritmer, såsom kunstige neurale netværk, er det meget mere udfordrende og kræver valg og implementering af specialiserede teknikker. Generelle teknikker såsom bootstrap resampling metode kan bruges, men er beregningsmæssigt dyre at beregne.papiret” en omfattende gennemgang af neurale netværksbaserede Forudsigelsesintervaller og nye fremskridt ” giver en rimelig nylig undersøgelse af forudsigelsesintervaller for ikke-lineære modeller i forbindelse med neurale netværk. Følgende liste opsummerer nogle metoder, der kan bruges til forudsigelsesusikkerhed for ikke-lineære maskinindlæringsmodeller:
- Delta-metoden fra feltet ikke-lineær regression.
- den bayesiske metode, fra Bayesian modellering og statistik.
- metoden til estimering af Middelvarians ved hjælp af estimeret statistik.
- Bootstrap-metoden ved hjælp af data resampling og udvikling af et ensemble af modeller.
Vi kan gøre beregningen af et forudsigelsesinterval konkret med et bearbejdet eksempel i næste afsnit.
Forudsigelsesinterval for lineær Regression
en lineær regression er en model, der beskriver den lineære kombination af input til beregning af outputvariablerne.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
Vi kender ikke de sande værdier af koefficienterne b0 og b1. Alle disse elementer skal estimeres, hvilket introducerer usikkerhed i brugen af modellen for at forudsige.
Vi kan tage nogle antagelser, såsom fordelingen af H og y og forudsigelsesfejlene foretaget af modellen, kaldet rester, er gaussiske.
forudsigelsesintervallet omkring yhat kan beregnes som følger:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
Vi kender ikke i praksis. Vi kan beregne et upartisk skøn over af den forudsagte standardafvigelse som følger (taget fra maskinindlæringsmetoder til estimering af forudsigelsesinterval for modeloutput):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
bearbejdet eksempel
lad os gøre tilfældet med lineære regressionsforudsigelsesintervaller konkrete med et bearbejdet eksempel.lad os først definere et simpelt datasæt med to variabler, hvor outputvariablen (y) afhænger af inputvariablen (h) med en vis Gaussisk støj.
eksemplet nedenfor definerer det datasæt, vi vil bruge til dette eksempel.
|
1
2
3
4
5
6
7
8
9
10
11
12
14
15
16
# generer relaterede variabler
fra numpy import middel
fra numpy import std
from numpy.random import randn
from numpy.random import seed
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# summarize
print(‘x: mean=%.3f stdv=%.3f’ % (mean(x), std(x)))
print(‘y: mean=%.3f stdv=%.3f’ % (mean(y), std(y)))
# plot
pyplot.scatter(x, y)
pyplot.show()
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
et plot af datasættet oprettes derefter.
Vi kan se det klare lineære forhold mellem variablerne med spredningen af punkterne, der fremhæver støj eller tilfældig fejl i forholdet.
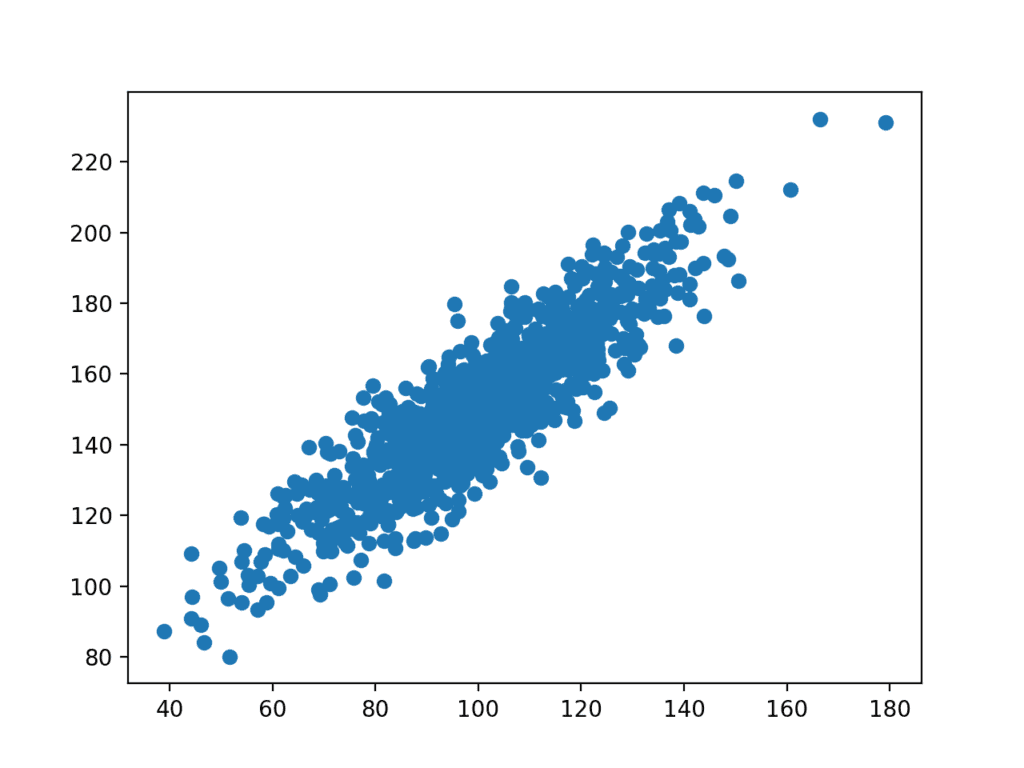
Scatter Plot af relaterede variabler
dernæst kan vi udvikle en simpel lineær regression, der giver inputvariablen, vil forudsige y-variablen. Vi kan bruge linregress () SciPy-funktionen til at passe til modellen og returnere B0-og b1-koefficienterne for modellen.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# simpel ikke-lineær regressionsmodel
fra numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(‘b0=%.3f, b1=%.3f’ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r’)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
B0=1.011, B1=49.117
|
koefficienterne bruges derefter med input fra datasættet til at forudsige. De resulterende input og forudsagte y-værdier afbildes som en linje oven på scatter-plottet for datasættet.
Vi kan tydeligt se, at modellen har lært det underliggende forhold i datasættet.
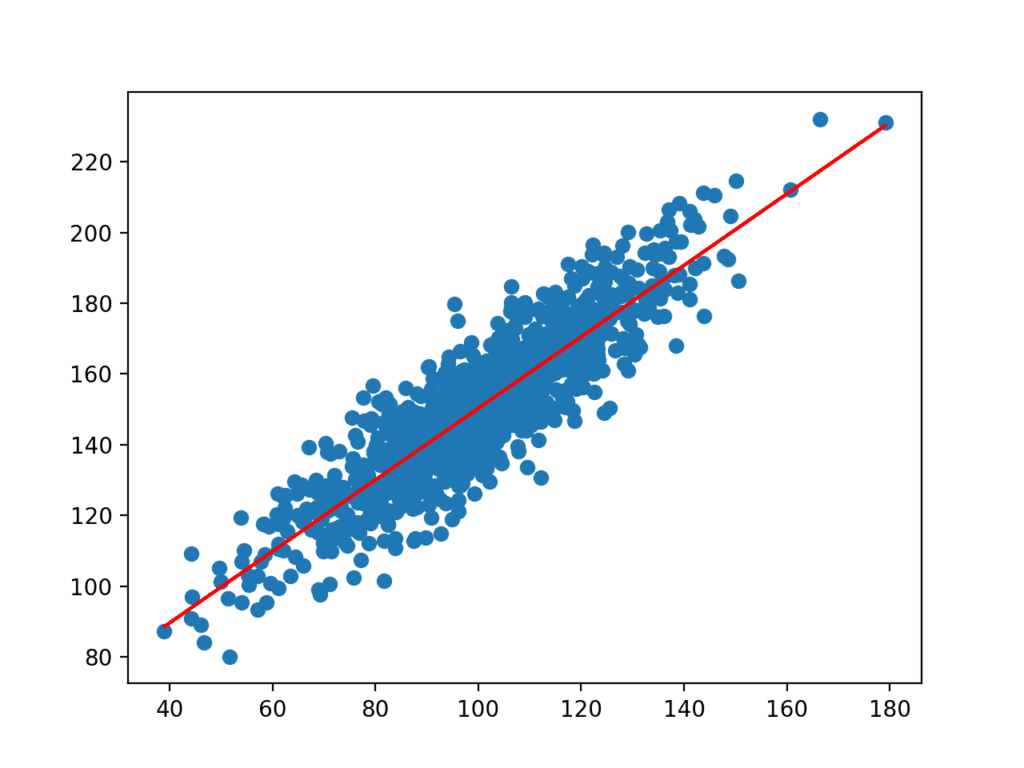
Scatter Plot af datasæt med linje til simpel lineær regressionsmodel
Vi er nu klar til at lave en forudsigelse med vores enkle lineære regressionsmodel og tilføje et forudsigelsesinterval.
Vi passer til modellen som før. Denne gang tager vi en prøve fra datasættet for at demonstrere forudsigelsesintervallet. Vi bruger input til at lave en forudsigelse, beregne forudsigelsesintervallet for forudsigelsen og sammenligne forudsigelsen og intervallet med den kendte forventede værdi.
lad os først definere input, forudsigelse og forventede værdier.
|
1
2
|
y_out = y
y_out = y yhat_out = yhat
|
dernæst kan vi estimere standardkurvaturen i forudsigelsesretningen.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.statistik import linregress
fra matplotlib import pyplot
# Seed random number generator
frø(1)
# forbered dataene
h = 20 * randn(1000) + 100
y = h + (10 * randn(1000) + 50)
# passer til den ikke-lineære regressionsmodel
B1, B0, r_value, p_value, std_err = linregress(h, y)
# Mark forudsigelser
yhat = B0 + B1 *
# Definer nyt input, forventet værdi og forudsigelse
h_in = h
y_out = y
yhat_out = yhat
# estimat StDev af yhat
sum_errs = arraysum ((y – yhat)* * 2)
StDev = KVRT(1 /(len(y) -2) * sum_errs)
# Beregn forudsigelsesinterval
interval = 1,96 * StDev
print(‘Forudsigelsesinterval: %.3F ‘ % interval)
lavere, øvre = yhat_out – interval, yhat_out + interval
print(‘95%% sandsynlighed for, at den sande værdi er mellem %.3f og %.3F ‘ % (lavere, øvre))
print (‘sand værdi:%.3f ‘ % y_out)
# plot datasæt og forudsigelse med interval
pyplot.scatter (s, s)
pyplot.Farve= ‘Rød’)
pyplot.errorbar (yhat_out, yerr=interval, Farve=’Sort’, fmt=’o’)
pyplot.Vis ()
|
kørsel af eksemplet estimerer yhat-standardafvigelsen og beregner derefter forudsigelsesintervallet.
når den er beregnet, præsenteres forudsigelsesintervallet for brugeren for den givne inputvariabel. Fordi vi konstruerede dette eksempel, kender vi det sande resultat, som vi også viser. Vi kan se, at i dette tilfælde dækker 95% forudsigelsesintervallet den sande forventede værdi.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
Der oprettes også et plot, der viser det rå datasæt som et scatter-plot, forudsigelserne for datasættet som en rød linje og forudsigelses-og forudsigelsesintervallet som henholdsvis en sort prik og linje.
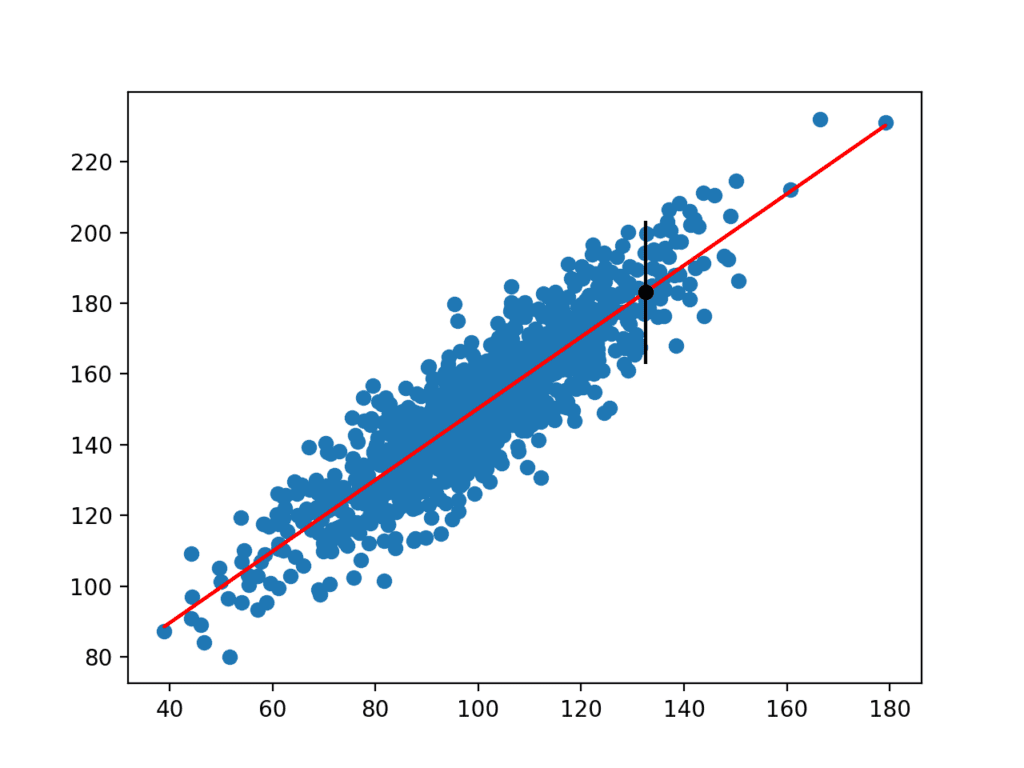
Scatter Plot af datasæt med lineær Model og Forudsigelsesinterval
udvidelser
dette afsnit viser nogle ideer til udvidelse af den tutorial, som du måske ønsker at udforske.
- opsummere forskellen mellem tolerance, tillid og forudsigelse intervaller.
- udvikle en lineær regressionsmodel til et standard maskinlæringsdatasæt og beregne forudsigelsesintervaller for et lille testsæt.
- beskriv detaljeret, hvordan en ikke-lineær forudsigelsesintervalmetode fungerer.
Hvis du udforsker nogen af disse udvidelser, vil jeg meget gerne vide det.
yderligere læsning
dette afsnit giver flere ressourcer om emnet, hvis du ønsker at gå dybere.
indlæg
- Sådan rapporteres Klassificeringsydelse med konfidensintervaller
- Sådan beregnes Bootstrap-konfidensintervaller for Maskinindlæringsresultater i Python
- forstå Tidsserieprognose usikkerhed ved hjælp af konfidensintervaller med Python
- anslå antallet af eksperiment gentagelser for stokastiske maskinindlæringsalgoritmer
bøger
- forståelse af de nye statistikker: effektstørrelser, konfidensintervaller og meta-analyse, 2017.
- statistiske intervaller: en Guide til praktikere og forskere, 2017.
- En introduktion til statistisk læring: med applikationer i R, 2013.
- Introduktion til den nye statistik: estimering, åben videnskab og videre, 2016.
- prognoser: principper og praksis, 2013.
Papers
- en sammenligning af nogle fejlestimater for neurale netværksmodeller, 1995.
- Machine learning tilgange til estimering af forudsigelse interval for modellen output, 2006.
- en omfattende gennemgang af neurale netværksbaserede Forudsigelsesintervaller og nye fremskridt, 2010.
API
- scipy.statistik.linregress () API
- matplotlib.pyplot.scatter () API
- matplotlib.pyplot.errorbar () API
artikler
- Forudsigelsesinterval på kryds valideret
oversigt
i denne vejledning opdagede du forudsigelsesintervallet, og hvordan du beregner det for en simpel lineær regressionsmodel.
specifikt lærte du:
- at et forudsigelsesinterval kvantificerer usikkerheden ved en enkelt punkts forudsigelse.
- at forudsigelsesintervaller kan estimeres analytisk for enkle modeller, men er mere udfordrende for ikke-lineære maskinindlæringsmodeller.
- Sådan beregnes forudsigelsesintervallet for en simpel lineær regressionsmodel.
har du spørgsmål?
stil dine spørgsmål i kommentarerne nedenfor, og jeg vil gøre mit bedste for at svare.
få styr på statistik til maskinindlæring!

udvikle en arbejdsforståelse af statistik
…ved at skrive kodelinjer i python
Opdag hvordan i min nye e-bog:
statistiske metoder til maskinindlæring
det giver selvstudie tutorials om emner som:
hypotesetest, korrelation, ikke-parametrisk statistik, Resampling og meget mere…
Opdag, hvordan du omdanner Data til viden
Spring akademikerne over. Bare Resultater.
se hvad der er indeni