lineær Diskriminantanalyse eller Normal Diskriminantanalyse eller Diskriminantfunktionsanalyse er en dimensionalitetsreduktionsteknik, der ofte bruges til de overvågede klassificeringsproblemer. Det bruges til modellering af forskelle i grupper, dvs.adskillelse af to eller flere klasser. Det bruges til at projicere funktionerne i rummet med højere dimension til et rum med lavere dimension.
for eksempel har vi to klasser, og vi skal adskille dem effektivt. Klasser kan have flere funktioner. Brug af kun en enkelt funktion til at klassificere dem kan resultere i en vis overlapning som vist i nedenstående figur. Så vi vil fortsætte med at øge antallet af funktioner til korrekt klassificering.

eksempel:
Antag, at vi har to sæt datapunkter, der tilhører to forskellige klasser, som vi vil klassificere. Som vist i den givne 2D-graf, når datapunkterne er afbildet på 2D-planet, er der ingen lige linje, der kan adskille de to klasser af datapunkterne fuldstændigt. Derfor anvendes i dette tilfælde LDA (lineær Diskriminantanalyse), som reducerer 2D-grafen til en 1D-graf for at maksimere adskilleligheden mellem de to klasser.
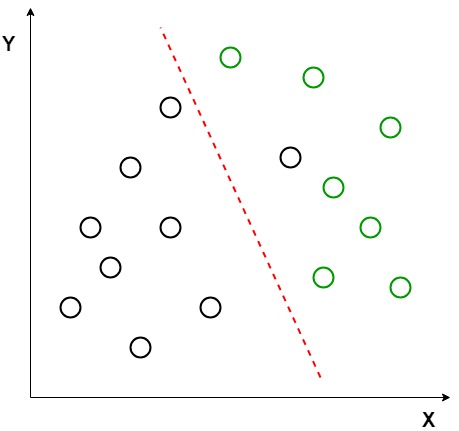
her bruger lineær Diskriminantanalyse både akserne (H og Y) til at oprette en ny akse og projicerer data på en ny akse på en måde for at maksimere adskillelsen af de to kategorier og dermed reducere 2D-grafen til en 1D-graf.
to kriterier bruges af LDA til at oprette en ny akse:
- Maksimer afstanden mellem de to klassers midler.
- Minimer variationen inden for hver klasse.
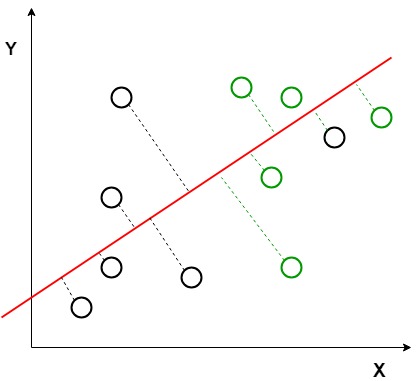
i ovenstående graf kan det ses, at en ny akse (i rødt) genereres og afbildes i 2D-grafen, således at den maksimerer afstanden mellem de to klassers midler og minimerer variationen inden for hver klasse. Enkelt sagt øger denne nyligt genererede akse adskillelsen mellem Dtla-punkterne i de to klasser. Efter generering af denne nye akse ved hjælp af ovennævnte kriterier er alle datapunkter i klasserne afbildet på denne nye akse og vist i nedenstående figur.

men lineær diskriminerende analyse mislykkes, når gennemsnittet af distributionerne deles, da det bliver umuligt for LDA at finde en ny akse, der gør begge klasser lineært adskillelige. I sådanne tilfælde bruger vi ikke-lineær diskriminerende analyse.
udvidelser til LDA:
- kvadratisk Diskriminantanalyse: Hver klasse bruger sit eget estimat af varians (eller kovarians, når der er flere inputvariabler).
- fleksibel Diskriminantanalyse (FDA): hvor ikke-lineære kombinationer af input anvendes, såsom splines.
- Regulariseret Diskriminantanalyse (RDA): introducerer regulering i estimatet af variansen (faktisk kovarians), der modererer indflydelsen af forskellige variabler på LDA.
applikationer:
- ansigtsgenkendelse: Inden for computersyn er ansigtsgenkendelse en meget populær applikation, hvor hvert ansigt er repræsenteret af et meget stort antal billedværdier. Lineær diskriminantanalyse (LDA) bruges her til at reducere antallet af funktioner til et mere håndterbart antal inden klassificeringsprocessen. Hver af de genererede nye dimensioner er en lineær kombination af billedværdier, der danner en skabelon. De lineære kombinationer opnået ved hjælp af Fishers lineære diskriminant kaldes Fisher ansigter.
- medicinsk: På dette område bruges lineær diskriminantanalyse (LDA) til at klassificere patientens sygdomstilstand som mild, moderat eller svær baseret på patientens forskellige parametre og den medicinske behandling, han gennemgår. Dette hjælper lægerne med at intensivere eller reducere tempoet i deres behandling.
- kundeidentifikation: Antag, at vi vil identificere den type kunder, der mest sandsynligt vil købe et bestemt produkt i et indkøbscenter. Ved at gøre en simpel spørgsmål og svar undersøgelse, kan vi samle alle funktionerne i kunderne. Her vil lineær diskriminantanalyse hjælpe os med at identificere og vælge de funktioner, der kan beskrive egenskaberne hos den gruppe af kunder, der mest sandsynligt vil købe det pågældende produkt i indkøbscentret.
