Hej og velkommen til en illustreret Guide til lang korttidshukommelse (LSTM) og Gated recidiverende enheder (Gru). Jeg er Michael, og jeg er Maskinlæringsingeniør i AI voice assistant-rummet.
i dette indlæg starter vi med intuitionen bag LSTM ‘s og GRU’ s. så forklarer jeg de interne mekanismer, der gør det muligt for LSTM ‘s og GRU’ s at fungere så godt. Hvis du vil forstå, hvad der sker under hætten til disse to netværk, så er dette indlæg noget for dig.
Du kan også se videoversionen af dette indlæg på youtube, hvis du foretrækker det.
tilbagevendende neurale netværk lider af kortvarig hukommelse. Hvis en sekvens er lang nok, har de svært ved at bære information fra tidligere tidstrin til senere. Så hvis du forsøger at behandle et afsnit af tekst for at gøre forudsigelser, kan RNN ‘ s udelade vigtige oplysninger fra starten.
under bagudbredelse lider tilbagevendende neurale netværk af det forsvindende gradientproblem. Gradienter er værdier, der bruges til at opdatere en neurale netværk vægte. Det forsvindende gradientproblem er, når gradienten krymper, når den tilbage formerer sig gennem tiden. Hvis en gradientværdi bliver ekstremt lille, bidrager den ikke for meget læring.

så i tilbagevendende neurale netværk stopper lag, der får en lille gradientopdatering, at lære. Det er normalt de tidligere lag. Så fordi disse lag ikke lærer, kan RNN ‘ er glemme, hvad det ses i længere sekvenser, og dermed have en kortvarig hukommelse. Hvis du vil vide mere om mekanikken i tilbagevendende neurale netværk generelt, kan du læse mit tidligere indlæg her.
LSTM ‘er og GRU’ er som en løsning
LSTM ‘er og GRU’ er blev oprettet som løsningen på kortvarig hukommelse. De har interne mekanismer kaldet porte, der kan regulere informationsstrømmen.

disse porte kan lære, hvilke data i en sekvens er vigtigt at holde eller smide væk. Ved at gøre det kan den videregive relevant information ned ad den lange kæde af sekvenser for at komme med forudsigelser. Næsten alle avancerede resultater baseret på tilbagevendende neurale netværk opnås med disse to netværk. LSTM ‘er og GRU’ er kan findes i talegenkendelse, talesyntese og tekstgenerering. Du kan endda bruge dem til at generere billedtekster til videoer.
Ok, så i slutningen af dette indlæg skal du have en solid forståelse af, hvorfor LSTM ‘er og GRU’ er er gode til at behandle lange sekvenser. Jeg vil nærme mig dette med intuitive forklaringer og illustrationer og undgå så meget matematik som muligt.
Intuition
Ok, lad os starte med et tankeeksperiment. Lad os sige, at du kigger på anmeldelser online for at afgøre, om du vil købe Life cereal (Spørg mig ikke hvorfor). Du vil først læse anmeldelsen og derefter afgøre, om nogen syntes, det var godt, eller om det var dårligt.

Når du læser anmeldelsen, husker din hjerne ubevidst kun vigtige søgeord. Du henter ord som” fantastisk “og”perfekt afbalanceret morgenmad”. Du er ligeglad med ord som” dette”,” gav”,” alle”,” skulle ” osv. Hvis en ven spørger dig den næste dag, hvad anmeldelsen sagde, ville du sandsynligvis ikke huske det ord for ord. Du kan huske de vigtigste punkter, men som “vil helt sikkert købe igen”. Hvis du er meget som mig, vil de andre ord forsvinde fra hukommelsen.

og det er i det væsentlige, hvad en LSTM eller Gru gør. Det kan lære at holde kun relevante oplysninger til at gøre forudsigelser, og glemme ikke relevante data. I dette tilfælde fik de ord, du huskede, dig til at bedømme, at det var godt.
gennemgang af tilbagevendende neurale netværk
for at forstå, hvordan LSTM ‘er eller GRU’ er opnår dette, lad os gennemgå det tilbagevendende neurale netværk. En RNN fungerer sådan; første ord bliver omdannet til maskinlæsbare vektorer. Derefter behandler RNN sekvensen af vektorer en efter en.

under behandling passerer den den tidligere skjulte tilstand til næste trin i sekvensen. Den skjulte tilstand fungerer som neurale netværk hukommelse. Det indeholder oplysninger om tidligere data, som netværket har set før.
lad os se på en celle i RNN for at se, hvordan du ville beregne den skjulte tilstand. For det første kombineres input og tidligere skjult tilstand for at danne en vektor. Denne vektor har nu information om det aktuelle input og tidligere input. Vektoren går gennem tanh-aktiveringen, og udgangen er den nye skjulte tilstand eller netværkets hukommelse.

tanh-aktivering
tanh-aktiveringen bruges til at hjælpe med at regulere de værdier, der strømmer gennem netværket. Tanh-funktionen klemmer værdier for altid at være mellem -1 og 1.

når vektorer strømmer gennem et neuralt netværk, gennemgår det mange transformationer på grund af forskellige matematiske operationer. Så forestil dig en værdi, der fortsat ganges med lad os sige 3. Du kan se, hvordan nogle værdier kan eksplodere og blive astronomiske, hvilket får andre værdier til at virke ubetydelige.

en tanh-funktion sikrer, at værdierne forbliver mellem -1 og 1, hvilket regulerer udgangen af det neurale netværk. Du kan se, hvordan de samme værdier ovenfra forbliver mellem de grænser, der er tilladt af tanh-funktionen.

så det er en RNN. Det har meget få operationer internt, men fungerer ret godt under de rigtige omstændigheder (som korte sekvenser). RNN ‘er bruger meget mindre beregningsressourcer end det er udviklede varianter, LSTM’ er og GRU ‘ er.
LSTM
en LSTM har en lignende kontrolstrøm som et tilbagevendende neuralt netværk. Den behandler data, der videregiver information, når den formerer sig fremad. Forskellene er operationerne inden for LSTM ‘ s celler.

disse operationer bruges til at tillade LSTM at holde eller glemme oplysninger. Nu ser på disse operationer kan få lidt overvældende, så vi vil gå over dette trin for trin.
kernekoncept
kernekonceptet for LSTM ‘ er er celletilstanden, og det er forskellige porte. Celletilstanden fungerer som en transportvej, der overfører relativ information helt ned i sekvenskæden. Du kan tænke på det som “hukommelsen” af netværket. Celletilstanden kan i teorien bære relevant information gennem hele behandlingen af sekvensen. Så selv oplysninger fra de tidligere tidstrin kan gøre det til senere tidstrin, hvilket reducerer virkningerne af kortvarig hukommelse. Når celletilstanden går på sin rejse, bliver information tilføjet eller fjernet til celletilstanden via porte. Portene er forskellige neurale netværk, der bestemmer, hvilke oplysninger der er tilladt på celletilstanden. Portene kan lære, hvilke oplysninger der er relevante at holde eller glemme under træning.
Sigmoid
Gates indeholder sigmoid aktiveringer. En sigmoid-aktivering svarer til tanh-aktiveringen. I stedet for at klemme værdier mellem -1 og 1, klemmer det værdier mellem 0 og 1. Det er nyttigt at opdatere eller glemme data, fordi ethvert tal, der ganges med 0, er 0, hvilket får værdier til at forsvinde eller blive “glemt.”Ethvert tal ganget med 1 er den samme værdi, derfor forbliver værdien den samme eller “holdes.”Netværket kan lære, hvilke data der ikke er vigtige, derfor kan glemmes, eller hvilke data der er vigtige at opbevare.
div mellem 0 og 1
lad os grave lidt dybere ned i, hvad de forskellige porte laver, skal vi? Så vi har tre forskellige porte, der regulerer informationsstrømmen i en LSTM-celle. En glemme gate, input gate og output gate.
glem gate
først har vi glemme porten. Denne port bestemmer, hvilke oplysninger der skal smides eller opbevares. Oplysninger fra den tidligere skjulte tilstand og information fra den aktuelle indgang sendes gennem sigmoid-funktionen. Værdier kommer ud mellem 0 og 1. Jo tættere på 0 betyder at glemme, og jo tættere på 1 betyder at holde.
input gate
for at opdatere celletilstanden har vi input gate. Først passerer vi den tidligere skjulte tilstand og nuværende indgang til en sigmoid-funktion. Det bestemmer, hvilke værdier der vil blive opdateret ved at omdanne værdierne til at være mellem 0 og 1. 0 betyder ikke vigtigt, og 1 betyder vigtigt. Du sender også den skjulte tilstand og den aktuelle indgang til tanh-funktionen for at klemme værdier mellem -1 og 1 for at hjælpe med at regulere netværket. Derefter multiplicerer du tanh-udgangen med sigmoid-udgangen. Sigmoid-udgangen bestemmer, hvilke oplysninger der er vigtige for at holde fra tanh-udgangen.

celletilstand
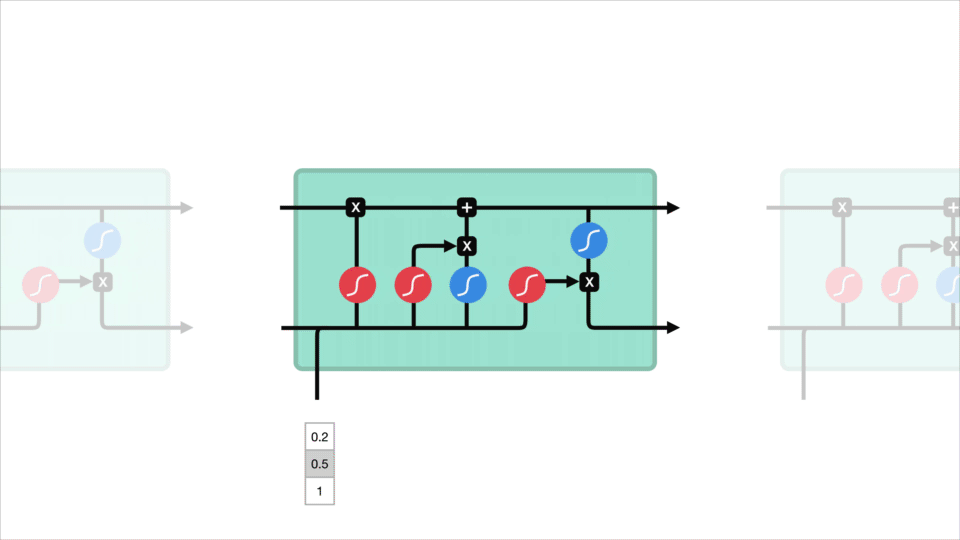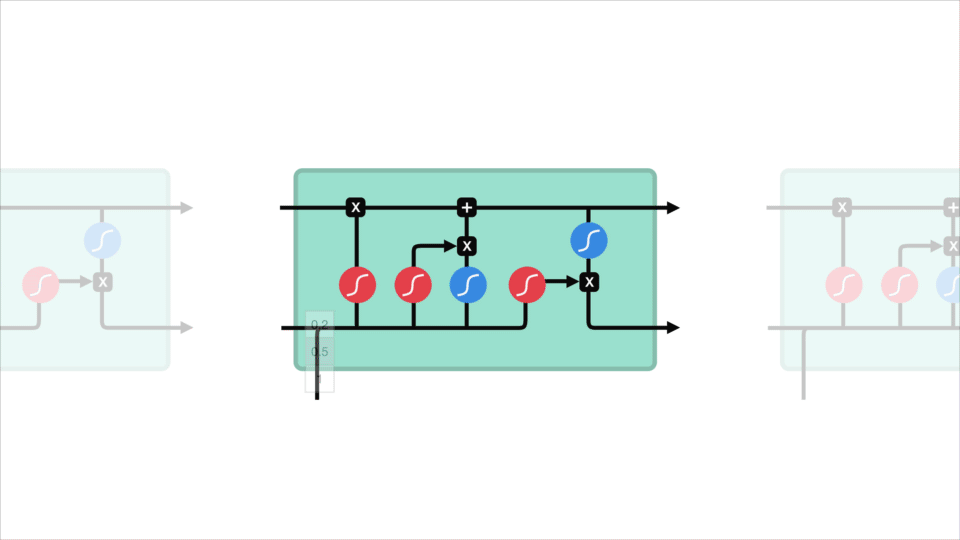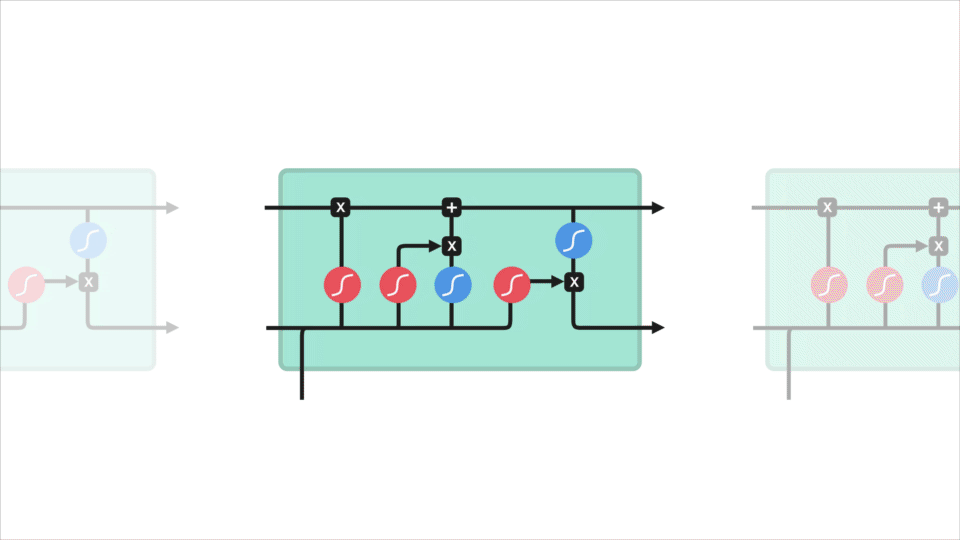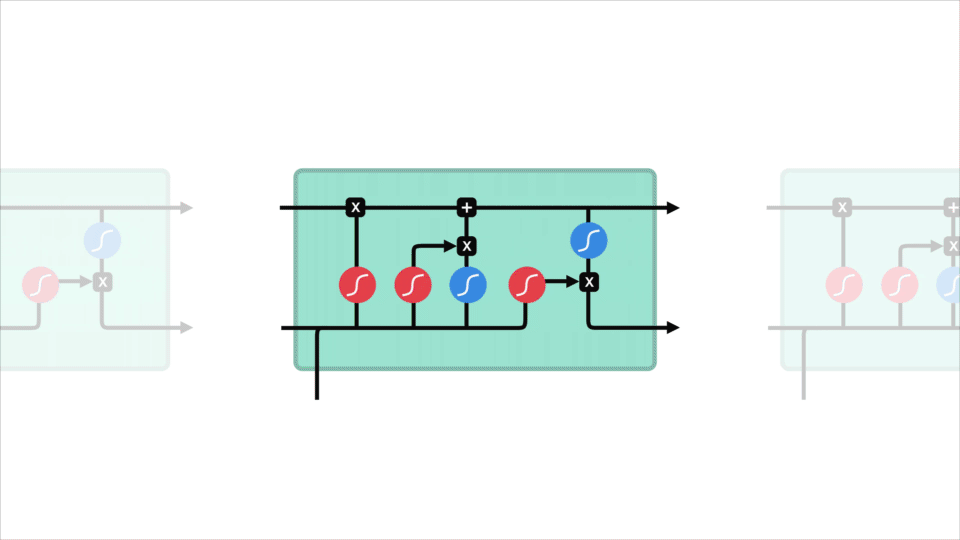
nu skal vi have nok information til at beregne celletilstanden. For det første bliver celletilstanden punktvis multipliceret med glemvektoren. Dette har en mulighed for at droppe værdier i celletilstand, hvis det bliver ganget med værdier nær 0. Derefter tager vi output fra inputporten og foretager en punktvis tilføjelse, der opdaterer celletilstanden til nye værdier, som det neurale netværk finder relevant. Det giver os vores nye celletilstand.

output Gate
sidste vi har output Gate. Outputporten bestemmer, hvad den næste skjulte tilstand skal være. Husk, at den skjulte tilstand indeholder oplysninger om tidligere input. Den skjulte tilstand bruges også til forudsigelser. Først passerer vi den tidligere skjulte tilstand og den aktuelle indgang til en sigmoid-funktion. Derefter passerer vi den nyligt modificerede celletilstand til tanh-funktionen. Vi multiplicerer tanh-udgangen med sigmoid-udgangen for at bestemme, hvilke oplysninger den skjulte tilstand skal bære. Udgangen er den skjulte tilstand. Den nye celletilstand og den nye skjulte overføres derefter til næste gangstrin.

for at gennemgå, glemmer porten, hvad der er relevant at holde fra tidligere trin. Inputporten bestemmer, hvilke oplysninger der er relevante at tilføje fra det aktuelle trin. Outputporten bestemmer, hvad den næste skjulte tilstand skal være.
Code Demo
for dem af jer, der forstår bedre ved at se koden, er her et eksempel ved hjælp af python pseudokode.

1. For det første bliver den tidligere skjulte tilstand og den aktuelle indgang sammenkædet. Vi kalder det combine.
2 . Kombiner get ‘ s fodret ind i glemlaget. Dette lag fjerner ikke-relevante data.
4. Et kandidatlag oprettes ved hjælp af kombiner. Kandidaten har Mulige værdier, der kan føjes til celletilstanden.
3. Kombiner også få er fodret ind i input lag. Dette lag bestemmer, hvilke data fra kandidaten der skal føjes til den nye celletilstand.
5. Efter beregning af Glem-laget, kandidatlaget og inputlaget beregnes celletilstanden ved hjælp af disse vektorer og den forrige celletilstand.
6. Udgangen beregnes derefter.
7. Punktvis multiplicering af output og den nye celletilstand giver os den nye skjulte tilstand.
det er det! Kontrolstrømmen af et LSTM-netværk er et par tensoroperationer og en for loop. Du kan bruge de skjulte stater til forudsigelser. Ved at kombinere alle disse mekanismer kan en LSTM vælge, hvilke oplysninger der er relevante at huske eller glemme under sekvensbehandling.
GRU
så nu ved vi, hvordan en LSTM fungerer, lad os kort se på GRU. GRU er den nyere generation af tilbagevendende neurale netværk og ligner stort set en LSTM. GRU har fjernet celletilstanden og brugt den skjulte tilstand til at overføre oplysninger. Det har også kun to porte, en reset gate og opdatering gate.

Opdater Gate
opdateringsporten fungerer svarende til Glem-og indtastningsporten til en LSTM. Det bestemmer, hvilke oplysninger der skal smides, og hvilke nye oplysninger der skal tilføjes.
Reset Gate
reset gate er en anden gate bruges til at bestemme, hvor meget tidligere oplysninger at glemme.
og det er en GRU. GRU ‘ er har færre tensoroperationer; derfor er de lidt hurtigere at træne så LSTM ‘ s. der er ikke en klar vinder, hvilken er bedre. Forskere og ingeniører forsøger normalt begge at bestemme, hvilken der fungerer bedre til deres brugssag.
så det er det
for at opsummere dette er RNN ‘ er gode til behandling af sekvensdata til forudsigelser, men lider af kortvarig hukommelse. LSTM ‘er og GRU’ er blev oprettet som en metode til at afbøde kortvarig hukommelse ved hjælp af mekanismer kaldet gates. Porte er bare neurale netværk, der regulerer strømmen af information, der strømmer gennem sekvenskæden. LSTM ‘er og GRU’ er bruges i avancerede dybe læringsapplikationer som talegenkendelse, talesyntese, naturlig sprogforståelse osv.
Hvis du er interesseret i at gå dybere, er her links til nogle fantastiske ressourcer, der kan give dig et andet perspektiv i forståelsen af LSTM ‘s og GRU’ s. Dette indlæg blev stærkt inspireret af dem.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/