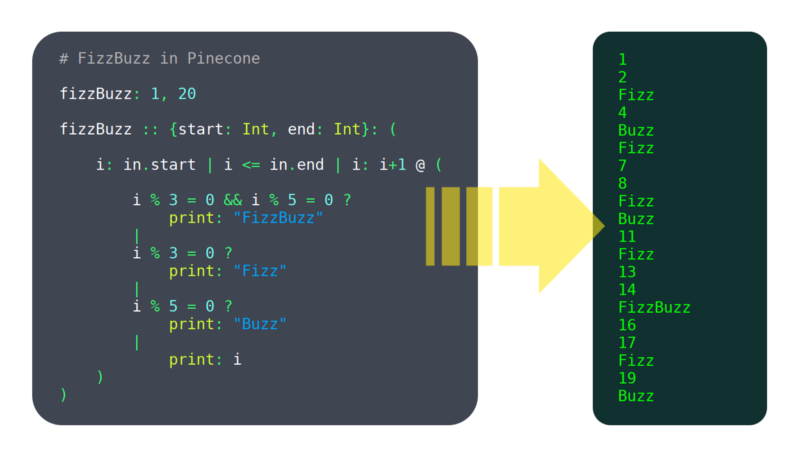
i løbet af de sidste 6 måneder har jeg arbejdet på et programmeringssprog kaldet Pinecone. Jeg ville ikke kalde det modent endnu, men det har allerede nok funktioner, der fungerer til at være brugbare, såsom:
- variabler
- funktioner
- brugerdefinerede strukturer
Hvis du er interesseret i det, skal du tjekke pinecones destinationsside eller dens GitHub repo.
Jeg er ikke ekspert. Da jeg startede dette projekt, havde jeg ingen anelse om, hvad jeg gjorde, og det gør jeg stadig ikke. jeg har taget nul klasser om sprogoprettelse, læst kun lidt om det online og fulgte ikke meget af de råd, jeg har fået.
og alligevel lavede jeg stadig et helt nyt sprog. Og det virker. Så jeg må gøre noget rigtigt.
i dette indlæg dykker jeg under hætten og viser dig pipeline Pinecone (og andre programmeringssprog), der bruges til at gøre kildekode til magi.
Jeg vil også komme ind på nogle af de kompromiser, jeg har haft, og hvorfor jeg tog de beslutninger, jeg gjorde.
dette er på ingen måde en komplet tutorial om at skrive et programmeringssprog, men det er et godt udgangspunkt, hvis du er nysgerrig efter sprogudvikling.
Kom godt i gang
“jeg aner absolut ikke, hvor jeg endda ville starte” er noget, jeg hører meget, når jeg fortæller andre udviklere, at jeg skriver et sprog. Hvis det er din reaktion, vil jeg nu gennemgå nogle indledende beslutninger, der træffes, og skridt, der tages, når du starter et nyt sprog.
kompileret vs fortolket
der er to hovedtyper af sprog: kompileret og fortolket:
- en kompilator finder ud af alt, hvad et program vil gøre, gør det til “maskinkode” (et format, som computeren kan køre rigtig hurtigt), og gemmer derefter det, der skal udføres senere.
- en tolk trin gennem kildekoden linje for linje, finde ud af, hvad det gør, som det går.
teknisk set kunne ethvert sprog kompileres eller fortolkes, men det ene eller det andet giver normalt mere mening for et bestemt sprog. Generelt har tolkning en tendens til at være mere fleksibel, mens kompilering har en tendens til at have højere ydeevne. Men dette skraber kun overfladen af et meget komplekst emne.
Jeg sætter stor pris på ydeevne, og jeg så en mangel på programmeringssprog, der både er høj ydeevne og enkelhedsorienteret, så jeg gik med compiled for Pinecone.
dette var en vigtig beslutning at tage tidligt, fordi mange sprogdesignbeslutninger påvirkes af det (for eksempel er statisk skrivning en stor fordel for kompilerede sprog, men ikke så meget for fortolkede).
På trods af at Pinecone blev designet med kompilering i tankerne, har den en fuldt funktionel tolk, som var den eneste måde at køre det på et stykke tid. Der er en række grunde til dette, som jeg vil forklare senere.
valg af sprog
jeg ved, det er lidt meta, men et programmeringssprog er i sig selv et program, og derfor skal du skrive det på et sprog. Jeg valgte C++ på grund af dens ydeevne og store funktionssæt. Jeg kan også godt lide at arbejde i C++.
Hvis du skriver et fortolket sprog, giver det meget mening at skrive det i en kompileret (som C, C++ eller hurtig), fordi præstationen tabt på din tolkes sprog og tolken, der fortolker din tolk, vil sammensatte.
Hvis du planlægger at kompilere, er et langsommere sprog (som Python eller JavaScript) mere acceptabelt. Kompileringstid kan være dårlig, men efter min mening er det ikke nær så stor en aftale som dårlig løbetid.
højt niveau Design
et programmeringssprog er generelt struktureret som en pipeline. Det vil sige, det har flere faser. Hvert trin har data formateret på en bestemt, veldefineret måde. Det har også funktioner til at omdanne data fra hvert trin til det næste.
det første trin er en streng, der indeholder hele inputkildefilen. Den sidste fase er noget, der kan køres. Dette vil alt blive klart, når vi går gennem Pinecone-rørledningen trin for trin.
Leksering

det første trin i de fleste programmeringssprog er leksering eller tokenisering. ‘Leksikalsk analyse’ er en forkortelse for leksikalsk analyse, et meget fancy ord for at opdele en masse tekst i tokens. Ordet ‘tokenisator’ giver meget mere mening, men’ lekser ‘ er så sjovt at sige, at jeg alligevel bruger det.
Tokens
et token er en lille enhed af et sprog. Et token kan være en variabel eller funktionsnavn (AKA en identifikator), en operatør eller et nummer.
Lekserens opgave
lekseren skal tage en streng, der indeholder en hel fil, der er værd for kildekoden, og spytte en liste, der indeholder hvert token.
fremtidige faser af rørledningen henviser ikke tilbage til den oprindelige kildekode, så lekseren skal producere alle de oplysninger, de har brug for. Årsagen til dette relativt strenge pipeline-format er, at lekseren kan udføre opgaver såsom at fjerne kommentarer eller opdage, om noget er et nummer eller en identifikator. Du vil holde denne logik låst inde i lekseren, begge, så du ikke behøver at tænke over disse regler, når du skriver resten af sproget, og så du kan ændre denne type syntaks alt sammen på et sted.
bøj
den dag jeg startede sproget, var det første, jeg skrev, en simpel lekser. Kort efter begyndte jeg at lære om værktøjer, der angiveligt ville gøre leksning enklere og mindre buggy.
det dominerende sådant værktøj er fleks, et program, der genererer leksere. Du giver den en fil, der har en særlig syntaks til at beskrive sprogets grammatik. Fra at det genererer et c-program, som lekser en streng og producerer det ønskede output.
min beslutning
Jeg valgte at beholde den lekser, jeg skrev for øjeblikket. I sidste ende så jeg ikke betydelige fordele ved at bruge fleks, i det mindste ikke nok til at retfærdiggøre at tilføje en afhængighed og komplicere byggeprocessen.
min lekser er kun et par hundrede linjer lang, og sjældent giver mig nogen problemer. At rulle min egen lekser giver mig også mere fleksibilitet, såsom muligheden for at tilføje en operatør til sproget uden at redigere flere filer.
Parsing

den anden fase af rørledningen er parseren. Parseren forvandler en liste over tokens til et træ af noder. Et træ, der bruges til lagring af denne type data, er kendt som et abstrakt Syntakstræ eller AST. I det mindste i Pinecone har AST ikke nogen information om typer eller hvilke identifikatorer der er. Det er simpelthen strukturerede tokens.
Parser opgaver
parseren tilføjer struktur til den ordnede liste over tokens, som lekseren producerer. For at stoppe uklarheder skal parseren tage hensyn til parentes og rækkefølgen af operationer. Simpelthen parsing operatører er ikke frygtelig svært, men som flere sprogkonstruktioner bliver tilføjet, kan parsing blive meget kompleks.
Bison
igen var der en beslutning om at involvere et tredjepartsbibliotek. Den dominerende parsing bibliotek er Bison. Bison fungerer meget som fleks. Du skriver en fil i et brugerdefineret format, der gemmer grammatikoplysningerne, så bruger Bison det til at generere et C-program, der vil gøre din parsing. Jeg valgte ikke at bruge Bison.
hvorfor brugerdefineret er bedre
med lekseren var beslutningen om at bruge min egen kode ret indlysende. En lekser er sådan et trivielt program, der ikke skriver min egen følte næsten lige så fjollet som ikke at skrive min egen ‘venstre-pad’.
med parseren er det en anden sag. Min Pinecone parser er i øjeblikket 750 linjer lang, og jeg har skrevet tre af dem, fordi de to første var papirkurven.
Jeg tog oprindeligt min beslutning af en række grunde, og selvom det ikke er gået helt glat, holder de fleste af dem sandt. De vigtigste er som følger:
- Minimer kontekstskift i arbejdsgang: kontekstskift mellem C++ og Pinecone er dårligt nok uden at smide Bisons grammatikgrammatik
- Keep build simple: Hver gang grammatikken ændrer Bison skal køres før bygningen. Dette kan automatiseres, men det bliver en smerte, når du skifter mellem byggesystemer.
- jeg kan godt lide at bygge cool lort: jeg lavede ikke Pinecone, fordi jeg troede, det ville være let, så hvorfor skulle jeg delegere en central rolle, når jeg selv kunne gøre det? En brugerdefineret parser er muligvis ikke triviel, men det er helt gennemførligt.
i begyndelsen var jeg ikke helt sikker på, om jeg gik ned ad en levedygtig vej, men jeg fik tillid til, hvad Valter Bright (en udvikler på en tidlig version af C++ og skaberen af D-sproget) måtte sige om emnet:
“noget mere kontroversielt, jeg ville ikke gider at spilde tid med lekser eller parser generatorer og andre såkaldte “compiler compilere.”De er spild af tid. At skrive en lekser og parser er en lille procentdel af jobbet med at skrive en kompilator. Brug af en generator vil tage omtrent lige så meget tid som at skrive en for hånd, og det vil gifte dig med generatoren (hvilket betyder noget, når du overfører kompilatoren til en ny platform). Og generatorer har også det uheldige ry for at udsende elendige fejlmeddelelser.”
Handlingstræ
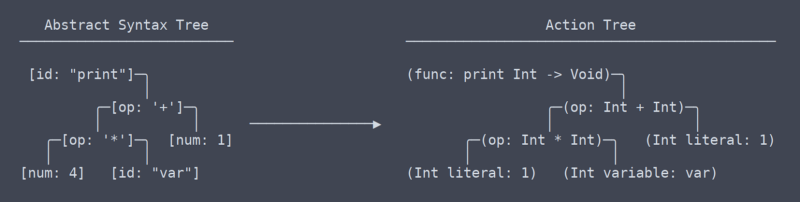
Vi har nu forladt området med fælles, universelle udtryk, eller i det mindste ved jeg ikke, hvad det er, der er tale om. ” div hvad betingelserne er længere. Fra min forståelse er det, jeg kalder ‘action tree’, mest beslægtet med LLVMS IR (intermediate representation).
der er en subtil, men meget signifikant forskel mellem handlingstræet og det abstrakte syntakstræ. Det tog mig et stykke tid at finde ud af, at der endda skulle være en forskel mellem dem (hvilket bidrog til behovet for omskrivninger af parseren).
Action Tree vs AST
kort sagt er action tree AST med kontekst. Denne kontekst er info, såsom hvilken type en funktion returnerer, eller at to steder, hvor en variabel bruges, faktisk bruger den samme variabel. Fordi det er nødvendigt at finde ud af og huske al denne sammenhæng, har koden, der genererer handlingstræet, brug for masser af navnerum opslagstabeller og andre tingamabobs.
kørsel af Handlingstræet
når vi har handlingstræet, er det nemt at køre koden. Hver handlingsknude har en funktion ‘udfør’, der tager noget input, gør hvad handlingen skal (inklusive muligvis kald underhandling) og returnerer handlingens output. Dette er tolken i aktion.
Kompileringsindstillinger
” men vent!”Jeg hører dig sige,” er det ikke Pinecone, der skal kompileres?”Ja, det er. Men kompilering er sværere end tolkning. Der er et par mulige tilgange.
Byg min egen Compiler
dette lød som en god ide til mig i starten. Jeg elsker at lave ting selv, og jeg har kløet efter en undskyldning for at blive god til samling.
Desværre er det ikke så nemt at skrive en bærbar kompilator som at skrive en maskinkode for hvert sprogelement. På grund af antallet af arkitekturer og operativsystemer er det upraktisk for enhver person at skrive en cross platform compiler backend.
selv holdene bag hurtig, Rust og Clang vil ikke gider med det hele alene, så i stedet bruger de alle…
LLVM
LLVM er en samling af kompilatorværktøjer. Det er dybest set et bibliotek, der vil gøre dit sprog til en kompileret eksekverbar binær. Det virkede som det perfekte valg, så jeg sprang lige ind. Desværre kontrollerede jeg ikke, hvor dybt vandet var, og jeg druknede straks.
LLVM, mens ikke samling sprog hårdt, er gigantisk kompleks bibliotek hårdt. Det er ikke umuligt at bruge, og de har gode tutorials, men jeg indså, at jeg skulle få lidt øvelse, før jeg var klar til fuldt ud at implementere en Pinecone compiler med den.
Transpiling
Jeg ville have en slags kompileret Pinecone, og jeg ville have det hurtigt, så jeg vendte mig til en metode, jeg vidste, at jeg kunne gøre arbejde: transpiling.
Jeg skrev en Pinecone til C++ transpiler, og tilføjede muligheden for automatisk at kompilere outputkilden med GCC. Dette fungerer i øjeblikket for næsten alle Pinecone-programmer (selvom der er et par kantsager, der bryder det). Det er ikke en særlig bærbar eller skalerbar løsning, men den fungerer indtil videre.
Future
forudsat at jeg fortsætter med at udvikle Pinecone, vil det få LLVM kompilering support før eller senere. Jeg formoder ingen mater hvor meget jeg arbejder på det, transpiler vil aldrig være helt stabil og fordelene ved LLVM er talrige. Det er bare et spørgsmål om, hvornår jeg har tid til at lave nogle prøveprojekter i LLVM og få fat i det.
indtil da er tolken fantastisk til trivielle programmer, og C++ transpiling fungerer til de fleste ting, der har brug for mere ydeevne.
konklusion
Jeg håber, jeg har gjort programmeringssprog lidt mindre mystisk for dig. Hvis du vil lave en selv, kan jeg varmt anbefale det. Der er masser af implementeringsdetaljer at finde ud af, men omridset her skal være nok til at komme i gang.
Her er mit råd på højt niveau til at komme i gang (husk, Jeg ved ikke rigtig, hvad jeg laver, så tag det med et saltkorn):
- hvis du er i tvivl, gå fortolket. Fortolkede sprog er generelt lettere at designe, bygge og lære. Jeg afskrækker dig ikke fra at skrive en kompileret, hvis du ved, det er hvad du vil gøre, men hvis du er på hegnet, ville jeg blive fortolket.
- når det kommer til leksere og parsere, gør hvad du vil. Der er gyldige argumenter for og imod at skrive din egen. I sidste ende, hvis du tænker på dit design og implementerer alt på en fornuftig måde, betyder det ikke rigtig noget.
- Lær af den pipeline, jeg endte med. En masse forsøg og fejl gik i at designe den rørledning, jeg har nu. Jeg har forsøgt at fjerne AST ‘er, AST’ er, der bliver til handlinger træer på plads, og andre forfærdelige ideer. Denne rørledning fungerer, så du skal ikke ændre den, medmindre du har en rigtig god ide.
- hvis du ikke har tid eller motivation til at implementere et komplekst sprog til generelle formål, kan du prøve at implementere et esoterisk sprog som Brainfuck. Disse tolke kan være så korte som et par hundrede linjer.
Jeg har meget få beklagelser, når det kommer til Pinecone udvikling. Jeg lavede en række dårlige valg undervejs, men jeg har omskrevet det meste af koden, der er berørt af sådanne fejl.
lige nu er Pinecone i en god nok tilstand, at den fungerer godt og let kan forbedres. Skrivning Pinecone har været en enormt lærerig og fornøjelig oplevelse for mig, og det er lige begyndt.