Version info: kode for denne side blev testet i Stata 12.
Poisson-regression bruges til at modellere tællevariabler.
Bemærk: formålet med denne side er at vise, hvordan du bruger forskellige dataanalysekommandoer. Det dækker ikke alle aspekter af den forskningsproces, som forskere forventes at gøre. Det omfatter navnlig ikke datarensning og-kontrol, verifikation af antagelser, modeldiagnostik eller potentielle opfølgningsanalyser.
eksempler på Poisson-regression
eksempel 1. Antallet af personer dræbt af muldyr eller hestespark i den preussiske hær om året.Ladislaus Bortkios indsamlede data fra 20 volumener af preussischen Statistik. Disse data blev indsamlet på 10 korps af den preussiske hær i slutningen af 1800-tallet i løbet af 20 år.
eksempel 2. Antallet af mennesker i kø foran dig i købmanden. Forudsigere kan omfatte antallet af varer, der i øjeblikket tilbydes til en særlig nedsat pris, og om en særlig begivenhed (f.eks.
eksempel 3. Antallet af priser optjent af studerende på en gymnasium. Forudsigere for antallet af optjente priser inkluderer den type program, hvor den studerende blev tilmeldt (f.eks. erhvervsmæssig, generel eller akademisk) og scoren på deres afsluttende eksamen i matematik.
beskrivelse af dataene
med henblik på illustration har vi simuleret et datasæt for eksempel 3 ovenfor. I dette eksempel er num_priser resultatvariablen og angiver antallet af priser, der er optjent af studerende på en gymnasium om et år, matematik er en kontinuerlig forudsigelsesvariabel og repræsenterer elevernes score på deres matematiske afsluttende eksamen, og prog er en kategorisk forudsigelsesvariabel med tre niveauer, der angiver den type program, hvor de studerende blev tilmeldt.
lad os starte med at indlæse dataene og se på nogle beskrivende statistikker.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
hver variabel har 200 gyldige observationer, og deres distributioner virker ret rimelige. I denne særlige er den ubetingede middelværdi og varians af vores resultatvariabel ikke meget anderledes.
lad os fortsætte med vores beskrivelse af variablerne i dette datasæt. Tabellen nedenfor viser det gennemsnitlige antal priser efter programtype og synes at antyde, at programtype er en god kandidat til at forudsige antallet af priser, vores resultatvariabel, fordi gennemsnitsværdien af resultatet ser ud til at variere efter prog.
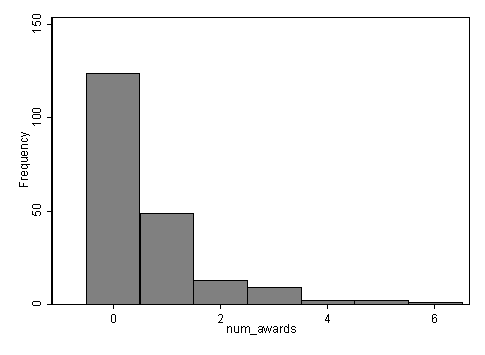
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
analysemetoder du kan overveje
nedenfor er en liste over nogle analysemetoder, du måske er stødt på. Nogle af de nævnte metoder er ret rimelige, mens andre enten er faldet ud af favør eller har begrænsninger.
- Poisson regression – Poisson regression bruges ofte til modellering af tælledata. Poisson-regression har en række udvidelser, der er nyttige til tællemodeller.
- negativ binomial regression – negativ binomial regression kan bruges til overdispergerede tælledata, det vil sige når den betingede varians overstiger det betingede gennemsnit. Det kan betragtes som en generalisering af Poisson-regression, da den har den samme gennemsnitlige struktur som Poisson-regression, og den har en ekstra parameter til at modellere overdispersionen. Hvis den betingede fordeling af resultatvariablen er overdispergeret, vil konfidensintervallerne for negativ binomialregression sandsynligvis være snævrere sammenlignet med dem fra en Poisson-regression.
- nul-oppustet regressionsmodel – nul-oppustede modeller forsøger at tage højde for overskydende nuller. Med andre ord menes to slags nuller at eksistere i dataene, “sande nuller” og “overskydende nuller”. Nul-oppustede modeller estimerer to ligninger samtidigt, en for tællemodellen og en for de overskydende nuller.
- OLS regression – Count resultatvariabler er undertiden log-transformeret og analyseret ved hjælp af OLS regression. Mange problemer opstår med denne tilgang, herunder tab af data på grund af udefinerede værdier genereret ved at tage loggen på nul (som er udefineret) og forudindtaget estimater.
Poisson-regression
nedenfor bruger vi poisson-kommandoen til at estimere en Poisson-regressionsmodel. I. before prog angiver, at det er en faktorvariabel (dvs., kategorisk variabel), og at den skal inkluderes i modellen som en række indikatorvariabler.
Vi bruger VCE(robust) mulighed for at opnå robuste standardfejl for parameterestimaterne som anbefalet af Cameron og Trivedi (2009) til at kontrollere for mild overtrædelse af underliggende antagelser.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
de to grad-of-freedom chi-kvadrat test indikerer, at prog, taget sammen, er en statistisk signifikant forudsigelse for antal priser.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
for at hjælpe med at vurdere modelens pasform kan estat gof-kommandoen bruges til at opnå godhed-of-fit chi-kvadreret test. Dette er ikke en test af modelkoefficienterne (som vi så i overskriftsoplysningerne), men en test af modelformularen: passer poisson-modelformularen til vores data?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
vi konkluderer, at modellen passer rimeligt godt, fordi Godheds-of-fit chi-kvadreret test ikke er statistisk signifikant. Hvis testen havde været statistisk signifikant, ville det indikere, at dataene ikke passer godt til modellen. I den situation kan vi forsøge at afgøre, om der er udeladt forudsigelsesvariabler, hvis vores linearitet antagelse holder og/eller hvis der er et spørgsmål om overdispersion.
Nogle gange vil vi måske præsentere regressionsresultaterne som hændelsesfrekvensforhold, vi kan bruge deres mulighed. Disse IRR-værdier er lig med vores koefficienter fra outputtet ovenfor eksponentieret.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
outputtet ovenfor angiver, at hændelsesfrekvensen for 2.prog er 2,96 gange hændelsesfrekvensen for referencegruppen (1.prog). Ligeledes, hændelsesfrekvensen for 3.prog er 1,45 gange hændelsesfrekvensen for referencegruppen, der holder de andre variabler konstant. Den procentvise ændring i hændelsesfrekvensen for antal præmier er en stigning på 7% for hver enheds stigning i matematik.
husk formularen af vores model ligning:
log(antal priser) = aflytning + b1(prog=2) + b2(prog=3) + b3math.
Dette indebærer:
num_priser = eksp(Intercept + b1(prog=2) + b2(prog=3)+ b3math) = eksp(Intercept) * eksp(b1(prog=2)) * eksp(b2(prog=3)) * eksp(b3math)
koefficienterne har en additiv effekt i Log(y) skalaen, og IRR har en multiplikativ effekt i Y skalaen.
For yderligere information om de forskellige målinger, hvor resultaterne kan præsenteres, og fortolkningen af sådanne, se regressionsmodeller for kategoriske afhængige variabler ved hjælp af Stata, anden udgave af J. Scott Long og Jeremy Freese (2006).
for at forstå modellen bedre kan vi bruge kommandoen margener. Nedenfor bruger vi kommandoen margener til at beregne de forudsagte tællinger på hvert niveau afprog og holder alle andre variabler (i dette eksempel matematik) i modellen ved deres middelværdier.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
i output ovenfor ser vi, at det forudsagte antal begivenheder for niveau 1 af prog handler om .21, der holder matematik i gennemsnit. Det forudsagte antal hændelser for niveau 2 af prog er højere på .62, og det forudsagte antal begivenheder for niveau 3 af prog handler om .31. Bemærk, at det forudsagte antal niveau 2 i prog er (.6249446/.211411) = 2,96 gange højere end det forudsagte antal for niveau 1 af prog. Dette svarer til det, vi så i IRR-outputtabellen.
nedenfor får vi de forudsagte tællinger for matematiske værdier, der spænder fra 35 Til 75 i trin på 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
tabellen ovenfor viser, at med prog ved dets observerede værdier og matematik, der holdes ved 35 for alle observationer, er det gennemsnitlige forudsagte antal (eller det gennemsnitlige antal priser) ca .13; når matematik = 75, er det gennemsnitlige forudsagte antal omkring 2,17. Hvis vi sammenligner de forudsagte tællinger ved matematik = 35 og matematik = 45, kan vi se, at forholdet er (.2644714/.1311326) = 2.017. Dette matcher IRR på 1.0727 for en ændring af 10 enheder: 1.0727^10 = 2.017.
den brugerskrevne fitstat-kommando (såvel som statas estat-kommandoer) kan bruges til at få yderligere oplysninger, der kan være nyttige, hvis du vil sammenligne modeller. Du kan skrive søg fitstat for at hente dette program (se hvordan kan jeg bruge søgekommandoen til at søge efter programmer og få yderligere hjælp? for mere information om brug af søgning).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
Du kan tegne det forudsagte antal begivenheder med kommandoerne nedenfor. Grafen angiver, at de fleste priser forudsiges for dem i det akademiske program (prog = 2), især hvis den studerende har en høj matematikscore. Det laveste antal forudsagte priser er for de studerende i det generelle program (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
ting at overveje
- hvis overdispersion ser ud til at være et problem, bør vi kontroller først, om vores model er korrekt specificeret, såsom udeladte variabler og funktionelle former. For eksempel, hvis vi udeladte forudsigelsesvariablen progin eksemplet ovenfor, vores model ser ud til at have et problem med overdispersion. Med andre ord kan en mis-specificeret model præsentere et symptom som et overdispersionsproblem.
- hvis du antager, at modellen er korrekt angivet, kan du kontrollere foroverdispersion. Der er flere måder at gøre dette på, herunder sandsynlighedsforholdstesten for overdispersionsparameter alpha ved at køre den samme regressionsmodel ved hjælp af negativ binomialfordeling (nbreg).
- en almindelig årsag til overdispersion er overskydende nuller, som igen genereres af en yderligere datagenererende proces. I denne situation bør nul-oppustet model overvejes.
- hvis datagenereringsprocessen ikke tillader nogen 0 ‘er (såsom antallet af dage brugt på hospitalet), kan en nul-afkortet model være mere passende.
- Tælledata har ofte en eksponeringsvariabel, der angiver antallet af gange, begivenheden kunne være sket. Denne variabel skal indarbejdes i en Poisson-model ved brug af indstillingen eksp ().
- resultatvariablen i en Poisson-regression kan ikke have negative tal, og eksponeringen kan ikke have 0s.
- i Stata kan en Poisson-model estimeres via glm-kommando med loglinket og Poisson-familien.
- du bliver nødt til at bruge glm-kommandoen for at få resterne til at kontrollere andre antagelser om Poisson-modellen (se Cameron and Trivedi (1998) og Dupont (2002) for mere information).
- Der findes mange forskellige målinger af pseudo-R-kvadreret. De forsøger alle at give information svarende til den, der leveres af R-kvadreret i OLS-regression, selvom ingen af dem kan fortolkes nøjagtigt som R-kvadreret i OLS-regression fortolkes. For en diskussion af forskellige pseudo-R-firkanter, se Long and Freese (2006) eller vores Ofte stillede spørgsmålhvad er pseudo-r-firkanter?.
- Poisson-regression estimeres via estimering af maksimal sandsynlighed. Det kræver normalt en stor prøvestørrelse.
Se også
- kommenteret output til poisson-kommandoen
- Stata ofte stillede spørgsmål: Hvordan kan jeg bruge countfit til at vælge en count-model?
- Stata online manual
- poisson
- Stata Ofte Stillede Spørgsmål
- hvordan beregnes standardfejl og konfidensintervaller for incidensfrekvensforhold (IRR ‘ er) af poisson og nbreg?
- Cameron, A. C. Og Trivedi, P. K. (2009). Mikroøkonometri Ved Hjælp Af Stata. College Station, t: Stata Press.Cameron, A. C. Og Trivedi, P. K. (1998). Regressionsanalyse af Tælledata. København: Cambridge Press.Cameron, A. C. fremskridt i Count Data Regression Talk for Anvendt Statistik værksted, marts 28, 2009.http://cameron.econ.ucdavis.edu/racd/count.html.Dupont (2002). Statistisk modellering for biomedicinske forskere: en simpel introduktion til analysen af komplekse Data. København: Cambridge Press.
- Lang, J. S. (1997). Regressionsmodeller for kategoriske og begrænsede afhængige variabler.Thousand Oaks, CA: Sage publikationer.
- Long, J. S. og Freese, J. (2006). Regressionsmodeller for kategoriske afhængige variabler ved hjælp af Stata, anden udgave. College Station, t: Stata Press.