Du kan ikke let bruge kategoriske variabler som forudsigere i lineær regression: du skal bryde dem op i dikotome variabler kendt som dummy variabler.
den ideelle måde at skabe disse er vores dummy variabler værktøj. Hvis du ikke vil bruge dette værktøj, viser denne tutorial den rigtige måde at gøre det manuelt på.
- eksempel i – enhver numerisk variabel
- eksempel II – numerisk variabel med tilstødende heltal
- eksempel III – String variabel med konvertering
- eksempel IV – String variabel uden konvertering
eksempel datafil
denne tutorial bruger personale.sav hele. En del af denne datafil er vist nedenfor.
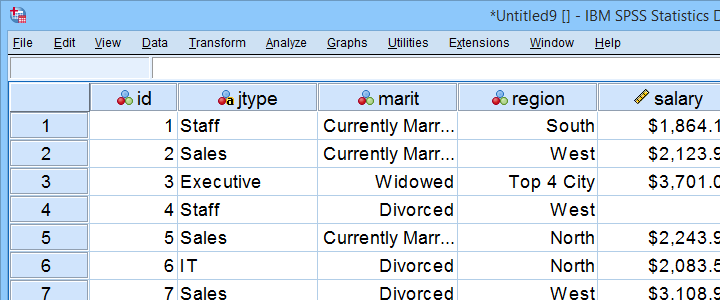
eksempel i – enhver numerisk variabel
lad os først oprette dummyvariabler til marit, forkortelse for civilstand. Vores første skridt er at køre en grundlæggende frekvenstabel medfrekvenser marit.Tabellen nedenfor viser den resulterende tabel.
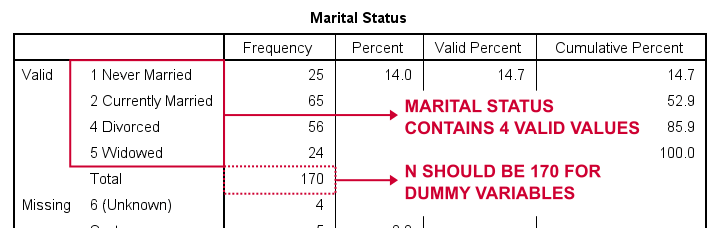
så hvordan opdeles civilstand i dummyvariabler? For det første udelader vi altid en kategori, referencekategorien. Du kan vælge en hvilken som helst kategori som referencekategori.
så for dette eksempel vælger vi 5 (Enke). Dette indebærer, at vi opretter 3 dummyvariabler, der repræsenterer kategori 1, 2 og 4 (Bemærk, at 3 ikke forekommer i denne variabel).syntaksen nedenfor viser, hvordan du opretter og mærker vores 3 dummyvariabler. Lad os køre det.
Beregn marit_1 = (marit = 1).
Beregn marit_2 = (marit = 2).
Beregn marit_4 = (marit = 4).
*Anvend variable etiketter til dummy variabler.
variable labels
marit_1 ‘civilstand = aldrig gift’
marit_2 ‘civilstand = aktuelt gift’
marit_4 ‘civilstand = skilt’.
* Hurtig kontrol første dummy variabel
frekvenser marit_1.
resultater
bemærk først, at vi oprettede 3 pænt mærkede dummyvariabler i vores aktive datasæt.
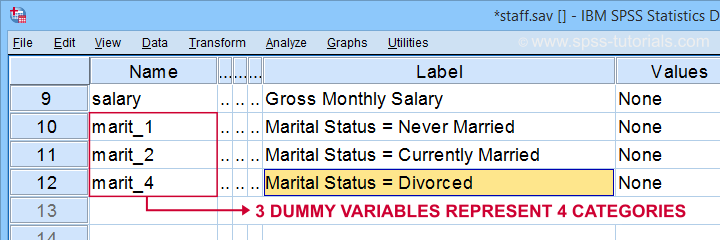
nedenstående tabel viser frekvensfordelingen for vores første dummyvariabel.

Bemærk, at vores dummy variabel har 3 forskellige værdier:
- respondenter, hvis civilstand ikke er “aldrig gift” score 0;
- respondenter, hvis civilstand er “aldrig gift” score 1;
- respondenter, hvis civilstand er en manglende værdi (og derfor ukendt) har en system manglende værdi.
Vi kan nu kontrollere resultaterne mere grundigt ved at runningcrosstabs marit af marit_1 til marit_4.Hvis du gør det, oprettes 3 beredskabstabeller, hvoraf den første er vist nedenfor.
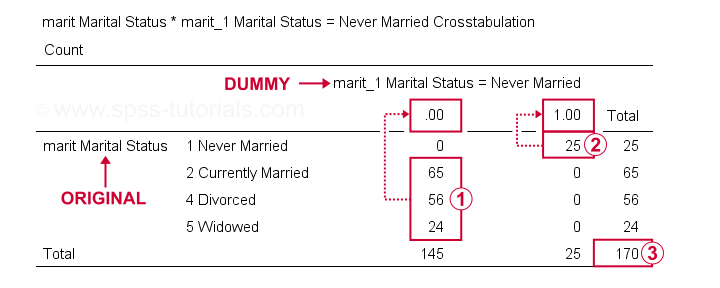
på vores dummy variabel, respondenter, der har andre ægteskabelige status end “aldrig gift” alle score 0;
respondenter, der har andre ægteskabelige status end “aldrig gift” alle score 0; respondenter, der “aldrig gift” alle score 1;
respondenter, der “aldrig gift” alle score 1; vi har en stikprøvestørrelse på N = 170 (denne tabel inkluderer kun respondenter uden manglende værdier på nogen af variablerne).
vi har en stikprøvestørrelse på N = 170 (denne tabel inkluderer kun respondenter uden manglende værdier på nogen af variablerne).
Valgfrit er en endelig-meget grundig – kontrol at sammenligne ANOVA-resultater for den oprindelige variabel med regressionsresultater ved hjælp af vores dummy-variabler. Syntaksen nedenfor gør netop det ved at bruge månedsløn som den afhængige variabel.
regression
/ afhængig løn
/ metode indtast marit_1 til marit_4.
*Minimal ANOVA hjælp oprindelige variabel.
envejsløn af marit.
Bemærk, at begge analyser resulterer i identiske ANOVA-tabeller. Vi vil diskutere ANOVA versus dummy variabel regression mere grundigt i en fremtidig tutorial.
eksempel II – numerisk variabel med tilstødende heltal
Vi opretter nu dummyvariabler for region. Igen starter vi med at inspicere en minimal frekvenstabel, som vi opretter ved at køre frekvensregionen.Dette resulterer i nedenstående tabel.
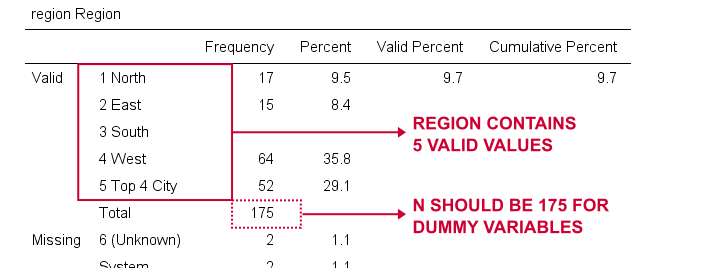
Vi vælger 1 (“Nord”) som vores referencekategori. Vi opretter derfor dummyvariabler for kategori 2 til 5. Da disse er tilstødende heltal, kan vi fremskynde tingene ved at bruge do REPEAT som vist nedenfor.
gentag # vals = 2 til 5 / #vars = region_2 til region_5.
omkode region (#vals = 1) (lo gennem hi = 0) til #vars.
Afslut gentag udskrivning.
*Anvend variable etiketter til nye variabler.
variable labels
region_2 ‘Region = Øst’
region_3 ‘Region = Syd’
region_4 ‘Region = Vest’
region_5 ‘Region = Top 4 By’.
* Hurtig kontrol.
crosstabs region efter region_2 til region_5.
en omhyggelig inspektion af de resulterende tabeller bekræfter, at alle resultater er korrekte.
eksempel III-Strengvariabel med konvertering
desværre fungerer vores første 2 metoder ikke for strengvariabler som jtype-forkortelse for “jobtype”). Den nemmeste løsning er at konvertere den til en numerisk variabel som diskuteret i SPSS konverter streng til numerisk variabel. Syntaksen nedenfor bruger AUTORECODE til at få arbejdet gjort.
autorecode jtype
/til njtype.
*tjek resultat.
frekvenser njtype.
*Indstil manglende værdier.
manglende værdier njtype (1,2).
*Kontroller resultatet igen.
frekvenser njtype.
resultat

da njtype-forkortelse for “numerisk jobtype”- er en numerisk variabel, kan vi nu bruge metode i eller metode II til at opdele den i dummyvariabler.
eksempel IV – Strengvariabel uden konvertering
konvertering af strengvariabler til numeriske er det let at oprette dummyvariabler til dem. Uden denne konvertering er processen besværlig, fordi SPSS ikke håndterer manglende værdier for strengvariabler korrekt. Syntaks nedenfor får dog jobbet udført korrekt.
frekvenser jtype.
*Chance’ (ukendt) ’til’NA’.
recode jtype (‘(ukendt) ‘ = ‘NA’).
*Indstil brugerens manglende værdier.
manglende værdier jtype ( ” ,’NA’).
*reinspect frekvenser.
frekvenser jtype.
*Opret dummy variabler for streng variabel.
Hvis(ikke mangler (jtype)) jtype_1 = (jtype = ‘IT’).
Hvis(ikke mangler (jtype)) jtype_2 = (jtype = ‘Management’).
Hvis(ikke mangler (jtype)) jtype_3 = (jtype = ‘salg’).
Hvis(ikke mangler (jtype)) jtype_4 = (jtype = ‘Staff’).
*Anvend variable etiketter til dummy variabler.
variable labels
jtype_1 ‘jobtype = IT’
jtype_2 ‘jobtype = Management’
jtype_3 ‘jobtype = salg’
jtype_4 ‘jobtype = personale’.
*Tjek resultater.
crosstabs jtype af jtype_1 til jtype_4.
endelige noter
oprettelse dummy variabler for numeriske variabler kan gøres hurtigt og nemt. Indstilling af korrekte variable etiketter tager dog altid lidt arbejde. Strengvariabler kræver nogle ekstra trin, men er også ret gennemførlige.
ikke desto mindre er den nemmeste mulighed vores SPSS Opret Dummy variabler værktøj, da det tager perfekt pleje af alt.