Aktiveringsfunksjoner er den mest avgjørende delen av ethvert nevrale nettverk i dyp læring. I dyp læring er svært kompliserte oppgaver bildeklassifisering, språktransformasjon, objektdeteksjon, etc som trengs for å adressere ved hjelp av nevrale nettverk og aktiveringsfunksjon. Så uten det er disse oppgavene ekstremt komplekse å håndtere. i nøtteskallet er et nevralt nettverk en veldig kraftig teknikk i maskinlæring som i utgangspunktet etterligner hvordan en hjerne forstår, hvordan? Hjernen mottar stimuli, som inngang, fra miljøet, behandler det og produserer deretter utgangen tilsvarende.
Introduksjon
nevrale nettverksaktiveringsfunksjoner er generelt den viktigste komponenten Av Dyp Læring, de er fundamentalt brukt til å bestemme utgangen av dype læringsmodeller, dens nøyaktighet og ytelseseffektivitet av treningsmodellen som kan designe eller dele et stort skala nevralt nettverk.Aktiveringsfunksjoner har etterlatt betydelige effekter på nevrale nettverks evne til å konvergere og konvergenshastighet, vil du ikke hvordan? La oss fortsette med en introduksjon til aktiveringsfunksjonen, typer aktiveringsfunksjoner & deres betydning og begrensninger gjennom denne bloggen.
Hva er aktiveringsfunksjonen?
Aktiveringsfunksjonen definerer utgangen av inngang eller sett med innganger eller i andre termer definerer noden for utgangen av noden som er gitt i innganger. De bestemmer seg i utgangspunktet for å deaktivere nevroner eller aktivere dem for å få ønsket utgang. Det utfører også en ikke-lineær transformasjon på inngangen for å få bedre resultater på et komplekst nevralt nettverk.
Aktiveringsfunksjonen bidrar også til å normalisere utgangen av noen inngang i området mellom 1 til -1. Aktiveringsfunksjonen må være effektiv, og den bør redusere beregningstiden fordi det nevrale nettverket noen ganger trent på millioner av datapunkter.Aktiveringsfunksjonen bestemmer i utgangspunktet i ethvert nevralt nettverk som gir inndata eller mottar informasjon, er relevant eller det er irrelevant. La oss ta et eksempel for å forstå bedre hva som er en nevron og hvordan aktiveringsfunksjonen begrenser utgangsverdien til en viss grense.nevronet er i utgangspunktet et vektet gjennomsnitt av inngang, da denne summen sendes gjennom en aktiveringsfunksjon for å få en utgang.
y = ∑ (vekter*input + bias)
Her Kan Y være alt for en nevron mellom rekkevidde-uendelig til +uendelig. Så, vi må binde vår produksjon for å få ønsket prediksjon eller generaliserte resultater.
Y = Aktiveringsfunksjon (∑(vekter*input + bias))
så sender vi nevronen til aktiveringsfunksjon til bundne utgangsverdier.
Hvorfor trenger Vi Aktiveringsfunksjoner?
uten aktiveringsfunksjon ville vekt og bias bare ha en lineær transformasjon, eller nevrale nettverk er bare en lineær regresjonsmodell, en lineær ligning er polynom av en grad bare som er enkel å løse, men begrenset når det gjelder evne til å løse komplekse problemer eller høyere gradspolynomer. Men motsatt til det, tillegg av aktiveringsfunksjonen til nevrale nettverk utfører ikke-lineær transformasjon til input og gjøre det i stand til å løse komplekse problemer som språk oversettelser og bilde klassifikasjoner. I tillegg Til Det Er Aktiveringsfunksjoner differensierbare på grunn av hvilke de enkelt kan implementere bakforplantninger, optimalisert strategi mens de utfører backpropagasjoner for å måle gradienttapsfunksjoner i nevrale nettverk.
Typer Av Aktiveringsfunksjoner
de mest kjente aktiveringsfunksjonene er gitt nedenfor,
-
Binær trinn
-
ReLU
-
Sigmoid
-
Tanh
-
softmax
1. Binær Trinn Aktiveringsfunksjon
denne aktiveringsfunksjonen er veldig grunnleggende, og det kommer til å tenke hver gang hvis vi prøver å binde utgang. Det er i utgangspunktet en terskelbaseklassifiserer, i dette bestemmer vi noen terskelverdi for å bestemme at neuron skal aktiveres eller deaktiveres.
f(x) = 1 hvis x > 0 ellers 0 hvis x < 0
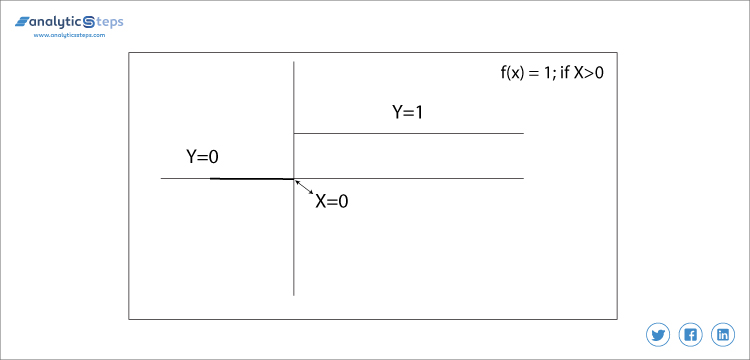
Binær trinnfunksjon
i dette bestemmer vi terskelverdien til 0. Det er veldig enkelt og nyttig å klassifisere binære problemer eller klassifiserer.
2. Lineær Aktiveringsfunksjon
det er en enkel rettlinjeaktiveringsfunksjon hvor vår funksjon er direkte proporsjonal med den vektede summen av nevroner eller inngang. Lineære aktiveringsfunksjoner er bedre i å gi et bredt spekter av aktiveringer, og en linje med en positiv helling kan øke avfyringshastigheten etter hvert som inngangshastigheten øker.
i binær, enten en nevron skyter eller ikke. Hvis du vet gradient nedstigning i dyp læring, vil du legge merke til at i denne funksjonen er derivat konstant.
Y = mZ
hvor derivat med hensyn Til Z er konstant m. betydningsgradienten er også konstant Og den har ingenting Å gjøre Med Z. I dette, hvis endringene i backpropagation vil være konstant Og ikke avhengig Av Z, så dette vil ikke være bra for læring.
i dette er vårt andre lag utgangen av en lineær funksjon av tidligere laginngang. Vent litt, hva har vi lært i dette at hvis vi sammenligner våre alle lagene og fjerner alle lagene bortsett fra det første og siste, kan vi også bare få en utgang som er en lineær funksjon av det første laget.
3. ReLU (Rectified Linear unit) Aktiveringsfunksjon
Rectified linear unit eller ReLU er mest brukt aktiveringsfunksjon akkurat nå som spenner fra 0 til uendelig, alle negative verdier konverteres til null, og denne konverteringsfrekvensen er så rask at verken det kan kartlegge eller passe inn i data riktig som skaper et problem, men der det er et problem er det en løsning.
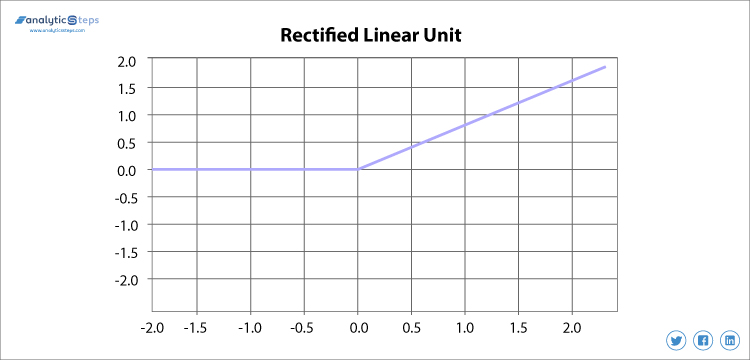
Rettet Lineær Enhet aktivering funksjon
Vi bruker Leaky ReLU funksjon i stedet For ReLU å unngå dette uegnet, I Leaky ReLU området er utvidet som forbedrer ytelsen.
Leaky ReLU Activation Function
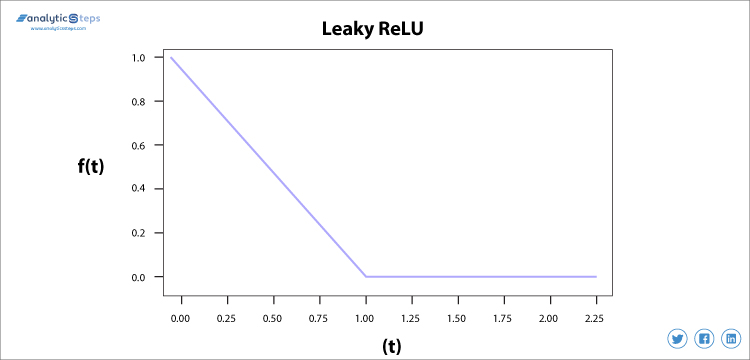
Leaky ReLU Activation Function
vi trengte Leaky ReLU activation function for å løse ‘Døende ReLU’ problemet, som diskutert I ReLU, observerer vi at alle negative inngangsverdier blir til null veldig raskt, og i Tilfelle Leaky ReLU gjør vi ikke alle negative innganger til null, men til en verdi nær null som løser det store problemet Med ReLU activation function.
Sigmoid Aktiveringsfunksjon
sigmoid aktiveringsfunksjonen brukes mest som den gjør sin oppgave med stor effektivitet, det er i utgangspunktet en probabilistisk tilnærming til beslutningstaking og varierer mellom 0 til 1, så når vi må ta en beslutning eller forutsi en utgang, bruker vi denne aktiveringsfunksjonen på grunn av at området er minimum, derfor vil prediksjonen være mer nøyaktig.
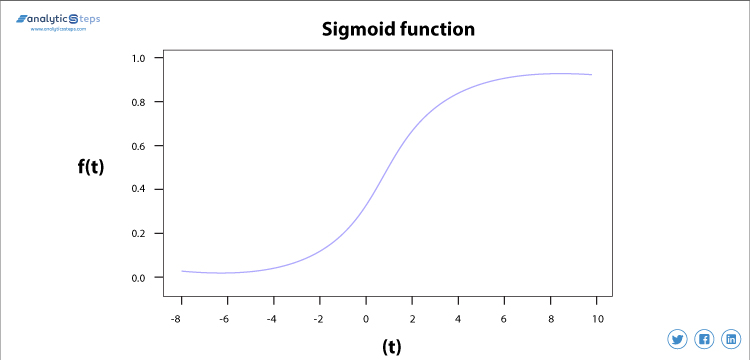
Sigmoid Aktiveringsfunksjon
f(x)=1 /(1+e(-x))
Sigmoid-Funksjonen forårsaker et problem som hovedsakelig kalles forsvinnende gradientproblem som oppstår fordi vi konverterer stor inngang mellom området 0 til 1 og derfor blir deres derivater mye mindre som ikke gir tilfredsstillende utgang. For å løse dette problemet brukes en annen aktiveringsfunksjon som ReLU der vi ikke har et lite derivatproblem.
Hyperbolsk Tangent Aktiveringsfunksjon(Tanh)
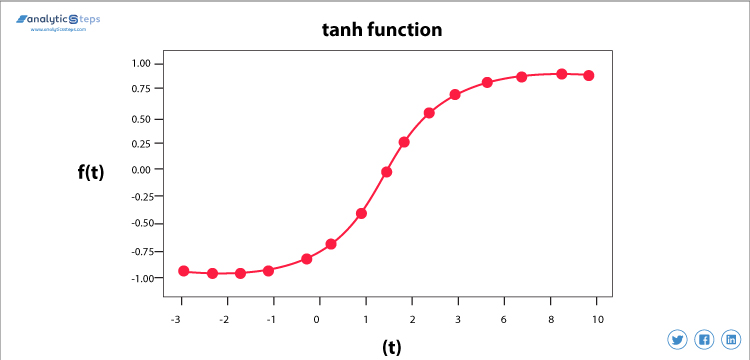
Tanh Aktiveringsfunksjon
denne aktiveringsfunksjonen er litt bedre enn sigmoid-funksjonen, som sigmoid-funksjonen, brukes den også til å forutsi eller skille mellom to klasser, men den kartlegger den negative inngangen til negativ mengde og varierer mellom -1 til 1.
Softmax Aktiveringsfunksjon
Softmax brukes hovedsakelig på det siste laget i.e output layer for beslutningstaking det samme som sigmoid aktivering fungerer, gir softmax i utgangspunktet verdi til inngangsvariabelen i henhold til vekten, og summen av disse vektene er til slutt en.
Softmax På Binær Klassifisering
For Binær klassifisering, både sigmoid, samt softmax, er like tilnærmelig, men i tilfelle multi-klasse klassifisering problem vi vanligvis bruker softmax og cross-entropi sammen med det.
Konklusjon
aktiveringsfunksjonene er de viktige funksjonene som utfører en ikke-lineær transformasjon til inngangen og gjør den dyktig til å forstå og utføre mer komplekse oppgaver. Vi har diskutert 7 majorly brukte aktiveringsfunksjoner med begrensning (hvis noen), disse aktiveringsfunksjonene brukes til samme formål, men under forskjellige forhold.