Hva Er Forsterkningslæring?
Forsterkningslæring er Definert Som En Maskinlæringsmetode som er opptatt av hvordan programvareagenter skal utføre handlinger i et miljø. Forsterkende Læring er en del av den dype læringsmetoden som hjelper deg med å maksimere en del av den kumulative belønningen. denne læringsmetoden for nevrale nettverk hjelper deg å lære å oppnå et komplekst mål eller maksimere en bestemt dimensjon over mange trinn.
I Forsterkning Læring opplæringen, vil du lære:
- Hva Er Forsterkning Læring?
- Viktige begreper som brukes I Dyp Forsterkning Læringsmetode
- Hvordan Forsterkning Læring fungerer?
- Forsterkning Læring Algoritmer
- Kjennetegn Ved Forsterkning Læring
- Typer Forsterkning Læring
- Læringsmodeller Av Forsterkning
- Forsterkning Læring vs. Veiledet Læring
- Anvendelser Av Forsterkning Læring
- Hvorfor bruke Forsterkning Læring?
- Når Skal Man Ikke Bruke Forsterkningslæring?
- Utfordringer Med Forsterkningslæring
Viktige begreper som brukes I Dyp Forsterkningslæringsmetode
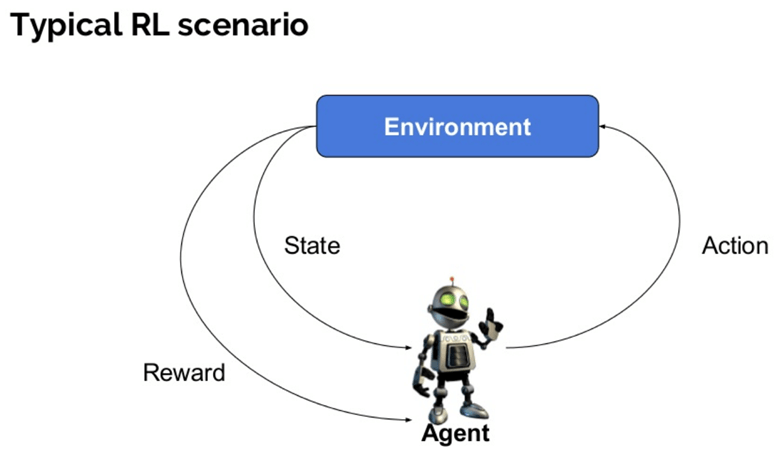
HER er noen viktige begreper som brukes i Forsterkning AI:
- agent: det er en antatt enhet som utfører Handlinger I et miljø for å få litt belønning.
- Miljø (e): et scenario som en agent må møte.
- Belønning (R): En umiddelbar retur gitt til en agent når han eller hun utfører bestemt handling eller oppgave.
- Tilstand (Er): Tilstand refererer til den nåværende situasjonen som returneres av miljøet.
- Politikk (?): Det er en strategi som gjelder av agenten for å bestemme neste handling basert på gjeldende tilstand.
- Verdi (V): det forventes langsiktig avkastning med rabatt, sammenlignet med kortsiktig belønning.
- Verdi Funksjon: den angir verdien av en stat som er den totale belonningen. Det er en agent som bør forventes begynner fra staten.
- Modell av miljøet: dette etterligner miljøets oppførsel. Det hjelper deg å gjøre slutninger skal gjøres og også bestemme hvordan miljøet vil oppføre seg.
- Modellbaserte metoder: Det er en metode for å løse forsterkende læringsproblemer som bruker modellbaserte metoder.
- Q verdi eller handlingsverdi (Q): Q verdi er ganske lik verdi. Den eneste forskjellen mellom de to er at det tar en ekstra parameter som en gjeldende handling.
Hvordan Forsterkende Læring fungerer?
La oss se et enkelt eksempel som hjelper deg med å illustrere forsterkningsmekanismen.
Tenk på scenariet for å lære nye triks til katten din
- siden katten ikke forstår engelsk eller noe annet menneskelig språk, kan vi ikke fortelle henne direkte hva hun skal gjøre. I stedet følger vi en annen strategi.
- vi etterligner en situasjon, og katten prøver å svare på mange forskjellige måter. Hvis kattens svar er ønsket måte, vil vi gi henne fisk.
- nå når katten er utsatt for samme situasjon, utfører katten en lignende handling med enda mer entusiastisk i forventning om å få mer belønning (mat).
- det er som å lære at katten får fra» hva du skal gjøre » fra positive erfaringer.
- samtidig lærer katten også hva som ikke gjør når de står overfor negative erfaringer.
Forklaring om eksemplet:
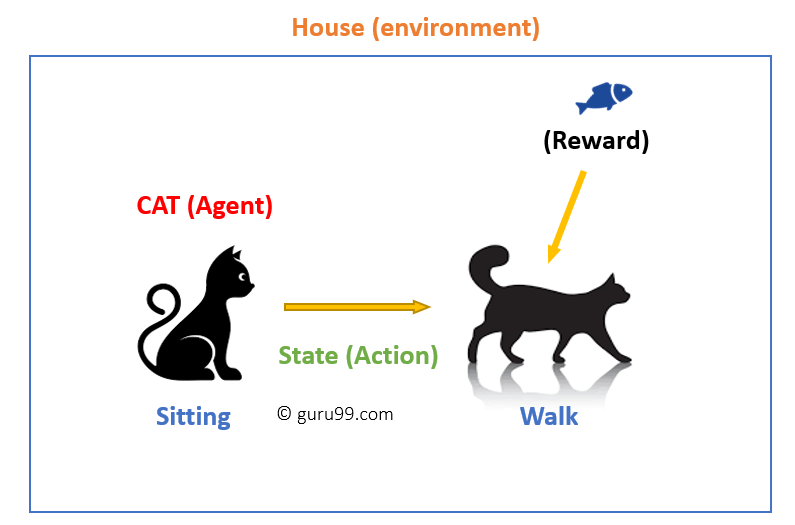
i dette tilfellet er
- katten din en agent som er utsatt for miljøet. I dette tilfellet er det ditt hus. Et eksempel på en tilstand kan være katten din sitter, og du bruker et bestemt ord i for katten å gå.
- vår agent reagerer ved å utføre en handling overgang fra en «tilstand» til en annen «tilstand.»
- for eksempel går katten din fra å sitte til å gå. reaksjonen av en agent er en handling, og politikken er en metode for å velge en handling gitt en tilstand i forventning om bedre resultater.
- etter overgangen kan de få en belønning eller straff i retur.
Forsterkningslærings Algoritmer
det er tre tilnærminger for å implementere En Forsterkningslærings algoritme.
Verdibasert:
i en verdibasert Forsterkningslæringsmetode bør du prøve å maksimere en verdifunksjon V (s). I denne metoden forventer agenten en langsiktig avkastning av dagens stater under politikken ?.
Policy-based:
i en policy-basert RL-metode prøver du å komme opp med en slik policy at handlingen som utføres i hver stat, hjelper deg med å få maksimal belønning i fremtiden.
to typer policybaserte metoder er:
- Deterministisk: for en hvilken som helst stat er den samme handlingen produsert av politikken ?.
- Stokastisk: Hver handling har en viss sannsynlighet, som bestemmes av følgende ligning.Stokastisk Policy:
n{a\s) = P\A, = a\S, =S]
Modellbasert:
i Denne Forsterkningsmetoden Må du opprette en virtuell modell for hvert miljø. Agenten lærer å utføre i det bestemte miljøet.
Kjennetegn Ved Forsterkningslæring
Her er viktige egenskaper ved forsterkningslæring
- det er ingen veileder, bare et reelt tall eller belønningssignal
- Sekvensiell beslutningstaking
- Tid spiller en avgjørende rolle i Forsterkningsproblemer
- Tilbakemelding er alltid forsinket, ikke øyeblikkelig
- Agentens handlinger bestemmer de påfølgende dataene den mottar
Typer Forsterkningslæring
to typer forsterkende læringsmetoder er:
positiv:
det er definert som en hendelse, som oppstår på grunn av spesifikk oppførsel. Det øker styrken og frekvensen av oppførselen og påvirker positivt på handlingen som er tatt av agenten.
Denne Typen Forsterkning hjelper deg å maksimere ytelsen og opprettholde endring i en lengre periode. Imidlertid kan for Mye Forsterkning føre til overoptimalisering av staten, noe som kan påvirke resultatene.
Negativ:
Negativ Forsterkning er definert som styrking av atferd som oppstår på grunn av en negativ tilstand som burde ha stoppet eller unngått. Det hjelper deg å definere minimum stand av ytelse. Ulempen med denne metoden er imidlertid at den gir nok til å møte opp minimumsadferd.
Læringsmodeller Av Forsterkning
Det er to viktige læringsmodeller i forsterkningslæring:
- Markov Decision Process
- Q learning
Markov Decision Process
følgende parametere brukes til å få en løsning:
- sett med handlinger – A
- Sett med stater-S
- Belønning – R
- Policy – n
- Verdi – V
den matematiske tilnærmingen for å kartlegge en løsning i forsterkningslæring er recon som En Markov Beslutningsprosess eller (MDP).
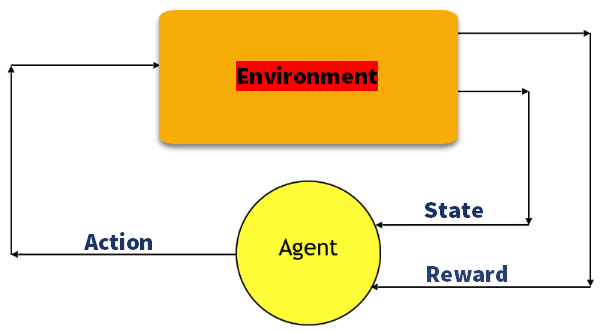
Q-Læring
Q-læring Er en verdibasert metode for å levere informasjon for å informere hvilken handling en agent skal ta.
La oss forstå denne metoden med følgende eksempel:
- det er fem rom i en bygning som er forbundet med dører.
- hvert rom er nummerert 0 til 4
- utsiden av bygningen kan være et stort uteområde (5)
- Dører nummer 1 og 4 fører inn i bygningen fra rom 5
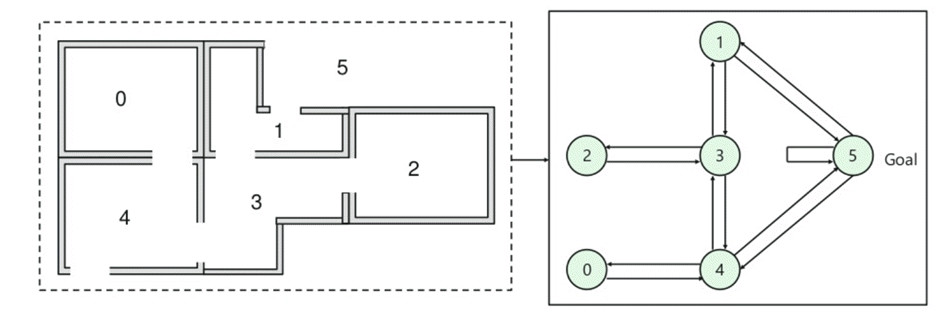
Deretter må du knytte en belønningsverdi til hver dør:
- Dører som fører direkte til målet Har en belønning på 100
- Dører som ikke er direkte koblet til målet rommet gir null belønning
- som dører er toveis, og to piler er tildelt for hvert rom
- Hver pil i bildet ovenfor inneholder en umiddelbar belønning verdi
Forklaring:
I dette bildet kan du se at rommet representerer en tilstand
agentens bevegelse fra ett rom til et annet representerer en handling
I bildet nedenfor beskrives en tilstand som en node, Mens Pilene viser handlingen.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Overvåket Læring
| Parametere | Forsterkningslæring | Veiledet Læring | Beslutningsstil | forsterkningslæring hjelper deg med å ta beslutninger i rekkefølge. | i denne metoden fattes en beslutning om inngangen gitt i begynnelsen. |
| Fungerer på | Fungerer på samspill med miljøet. | Fungerer på eksempler eller gitt eksempeldata. |
| Avhengighet av beslutning | i RL-metoden er læringsbeslutning avhengig. Derfor bør du gi etiketter til alle avhengige beslutninger. | Overvåket læring beslutningene som er uavhengige av hverandre, så etiketter er gitt for hver beslutning. |
| Best egnet | Støtter Og fungerer bedre I AI, hvor menneskelig interaksjon er utbredt. | det drives for det meste med et interaktivt programvaresystem eller applikasjoner. |
| Eksempel | objektgjenkjenning |
Anvendelser Av Forsterkningslæring
Her er anvendelser av Forsterkningslæring:
- Robotikk for industriell automasjon.Maskinlæring og databehandling Det hjelper deg å lage treningssystemer som gir tilpasset instruksjon og materialer i henhold til kravet til studenter.
- Fly kontroll og robot bevegelseskontroll
hvorfor bruke Forsterkning Læring?
her er hovedgrunnene til Å bruke Forsterkningslæring:
- Det hjelper deg å finne hvilken situasjon som trenger en handling
- Hjelper deg å oppdage hvilken handling som gir den høyeste belønningen over lengre periode.
- Forsterkning Læring gir også læring agent med en belønning funksjon.
- det gjør det også mulig å finne ut den beste metoden for å skaffe store belønninger.
Når Skal Man Ikke Bruke Forsterkningslæring?
du kan ikke bruke forsterkende læringsmodell er all situasjonen. Her er noen forhold når du ikke bør bruke forsterkende læringsmodell.
- Når du har nok data til å løse problemet med en veiledet læringsmetode
- Må du huske At Forsterkningslæring er databehandling-tung og tidkrevende. spesielt når handlingsrommet er stort.
Utfordringer Med Forsterkning Læring
Her er de store utfordringene du vil møte mens Du Gjør Forsterkning tjene:
- Funksjon / belønning design som bør være svært involvert
- Parametere kan påvirke hastigheten på læring.
- Realistiske miljøer kan ha delvis observerbarhet.
- For Mye Forsterkning kan føre til en overbelastning av tilstander som kan redusere resultatene.
- Realistiske miljøer kan være ikke-stasjonære.
Oppsummering:
- Forsterkningslæring Er En Maskinlæringsmetode
- Hjelper deg å oppdage hvilken handling som gir høyest belønning over lengre tid.
- Tre metoder for forsterkende læring er 1) Verdibasert 2) Policybasert Og Modellbasert læring.
- Agent, Stat, Belønning, Miljø, Verdi funksjon Modell av miljøet, Modellbaserte metoder, er noen viktige begreper som bruker I RL læringsmetode
- eksemplet på forsterkende læring er katten din er en agent som er utsatt for miljøet.Den største egenskapen ved denne metoden er at det ikke er noen veileder, bare et reelt tall eller belønningssignal
- To typer forsterkningslæring er 1) Positiv 2) Negativ
- To mye brukte læringsmodeller er 1) Markov Beslutningsprosess 2) Q læring
- Forsterkningslæringsmetode fungerer på samspill med miljøet, mens den overvåkede læringsmetoden fungerer på gitt prøvedata eller eksempel.
- Søknad eller forsterkning læringsmetoder er: Robotikk for industriell automatisering og forretningsstrategiplanlegging
- du bør ikke bruke denne metoden når du har nok data til å løse problemet
- den største utfordringen med denne metoden er at parametere kan påvirke læringshastigheten