Lineær Diskriminantanalyse Eller Normal Diskriminantanalyse eller Diskriminant Funksjonsanalyse er en dimensjonalitetsreduksjonsteknikk som ofte brukes til de overvåkede klassifiseringsproblemene. Den brukes til modellering av forskjeller i grupper, dvs. å skille to eller flere klasser. Den brukes til å projisere funksjonene i høyere dimensjon plass i en lavere dimensjon plass.
for eksempel har vi to klasser, og vi må skille dem effektivt. Klasser kan ha flere funksjoner. Bruk av bare en enkelt funksjon for å klassifisere dem kan resultere i noen overlapping som vist i figuren nedenfor. Så, vi vil fortsette å øke antall funksjoner for riktig klassifisering.

Eksempel:
Anta at vi har to sett med datapunkter som tilhører to forskjellige klasser som vi vil klassifisere. Som vist i den gitte 2d-grafen, når datapunktene er plottet på 2D-flyet, er det ingen rett linje som kan skille de to klassene av datapunktene helt. Derfor brukes I DETTE tilfellet Lda (Linear Discriminant Analysis) som reduserer 2d-grafen til EN 1d-graf for å maksimere separabiliteten mellom de TO klassene.
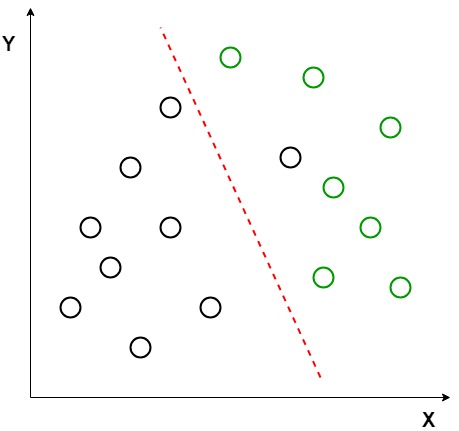
Her bruker Lineær Diskriminantanalyse både aksene (X og Y) for å lage en ny akse og projiserer data på en ny akse på en måte å maksimere separasjonen av de to kategoriene og dermed redusere 2d-grafen til EN 1d-graf.
To kriterier brukes AV LDA for å opprette en ny akse:
- Maksimer avstanden mellom middelene til de to klassene.
- Minimer variasjonen i hver klasse.
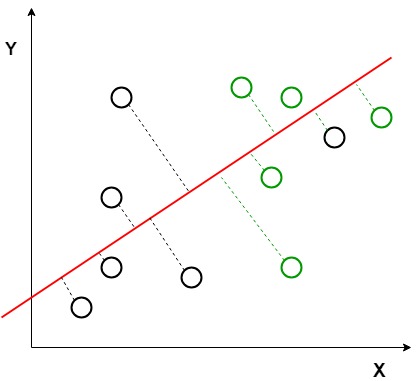
i grafen ovenfor kan det ses at en ny akse (i rødt) genereres og tegnes i 2d-grafen slik at den maksimerer avstanden mellom middelene til de to klassene og minimerer variasjonen i hver klasse. Enkelt sagt øker denne nylig genererte aksen separasjonen mellom dtla-punktene i de to klassene. Etter å ha generert denne nye aksen ved hjelp av de ovennevnte kriteriene, er alle datapunktene i klassene plottet på denne nye aksen og vist i figuren nedenfor.

Men Lineær Diskriminantanalyse mislykkes når gjennomsnittet av fordelingene deles, da DET blir umulig FOR LDA å finne en ny akse som gjør begge klassene lineært separerbare. I slike tilfeller bruker vi ikke-lineær diskriminantanalyse.
Utvidelser TIL LDA:
- Kvadratisk Diskriminant Analyse (QDA): Hver klasse bruker sitt eget estimat av varians (eller kovarians når det er flere inngangsvariabler).
- Fleksibel Diskriminantanalyse (FDA) : hvor ikke-lineære kombinasjoner av innganger brukes som splines.
- Regularized Discriminant Analysis (RDA): Introduserer regularisering i estimatet av variansen( faktisk kovarians), moderere påvirkning av ulike variabler PÅ LDA.
Applikasjoner:
- Ansiktsgjenkjenning: Innen Datasyn er ansiktsgjenkjenning et svært populært program der hvert ansikt er representert av et meget stort antall pikselverdier. Lineær diskriminantanalyse (lda) brukes her for å redusere antall funksjoner til et mer håndterbart tall før klassifiseringsprosessen. Hver av de nye dimensjonene som genereres er en lineær kombinasjon av pikselverdier, som danner en mal. De lineære kombinasjonene Som Oppnås ved Bruk Av Fishers lineære diskriminant kalles Fisher-ansikter.
- Medisinsk: I Dette feltet Brukes Lineær diskriminantanalyse (Lda) til å klassifisere pasientens sykdomstilstand som mild, moderat eller alvorlig basert på pasientens ulike parametere og den medisinske behandlingen han går gjennom. Dette hjelper legene til å intensivere eller redusere tempoet i behandlingen.
- Kundeidentifikasjon: Anta at vi ønsker å identifisere hvilken type kunder som mest sannsynlig vil kjøpe et bestemt produkt i et kjøpesenter. Ved å gjøre en enkel spørsmål og svar undersøkelse, kan vi samle alle funksjonene til kundene. Her Vil Lineær diskriminantanalyse hjelpe oss med å identifisere og velge funksjonene som kan beskrive egenskapene til kundegruppen som mest sannsynlig vil kjøpe det aktuelle produktet i kjøpesenteret.
