Hei Og velkommen til En Illustrert Guide Til Lang Korttidshukommelse (lstm) Og Gated TILBAKEVENDENDE ENHETER (gru). Jeg Er Michael, Og Jeg Er En Maskinlæringsingeniør i AI-stemmeassistentrommet.
i dette innlegget begynner vi med intuisjonen bak LSTM og GRU. Da skal jeg forklare de interne mekanismene som gjør AT LSTM og GRU kan utføre så bra. Hvis du vil forstå hva som skjer under hetten for disse to nettverkene, så er dette innlegget for deg.
du kan også se videoversjonen av dette innlegget på youtube hvis du foretrekker det.
Tilbakevendende Nevrale Nettverk lider av korttidshukommelse. Hvis en sekvens er lang nok, vil de ha det vanskelig å bære informasjon fra tidligere tidstrinn til senere. Så hvis DU prøver å behandle et avsnitt med tekst for å gjøre spådommer, KAN RNNS utelate viktig informasjon fra begynnelsen.under tilbakeutbredelse lider tilbakevendende nevrale nettverk av det forsvinnende gradientproblemet. Gradienter er verdier som brukes til a oppdatere nevrale nettverk vekter. Det forsvinnende gradientproblemet er når gradienten krymper når den tilbake forplanter seg gjennom tiden. Hvis en gradientverdi blir ekstremt liten, bidrar den ikke til for mye læring.

Regel For Gradient Oppdatering
så i tilbakevendende nevrale nettverk slutter lag som får en liten gradientoppdatering å lære. De er vanligvis de tidligere lagene. Så fordi disse lagene ikke lærer, KAN RNN glemme hva det sett i lengre sekvenser, og dermed ha et kortsiktig minne. Hvis du vil vite mer om mekanikken til tilbakevendende nevrale nettverk generelt, kan du lese mitt forrige innlegg her.
LSTM ‘s og GRU’ s som en løsning
LSTM ‘s og GRU’ s ble opprettet som løsningen på korttidshukommelsen. De har interne mekanismer kalt porter som kan regulere informasjonsflyten.

disse portene kan lære hvilke data i en sekvens som er viktig å beholde eller kaste bort. Ved å gjøre det, kan det passere relevant informasjon ned den lange kjeden av sekvenser for å gjøre spådommer. Nesten alle toppmoderne resultater basert på tilbakevendende nevrale nettverk oppnås med disse to nettverkene. LSTM og GRU finnes i talegjenkjenning, talesyntese og tekstgenerering. Du kan også bruke dem til å generere bildetekster for videoer.
Ok, så ved slutten av dette innlegget bør du ha en solid forståelse av hvorfor LSTM og GRU er gode til å behandle lange sekvenser. Jeg skal nærme meg dette med intuitive forklaringer og illustrasjoner og unngå så mye matte som mulig.
Intuisjon
Ok, La Oss starte med et tankeeksperiment. La oss si at du ser på anmeldelser på nettet for å avgjøre om Du vil kjøpe Life cereal (ikke spør meg hvorfor). Du vil først lese anmeldelsen og deretter avgjøre om noen trodde det var bra eller om det var dårlig.

når du leser anmeldelsen, husker hjernen din ubevisst bare viktige søkeord. Du plukker opp ord som » fantastisk «og» perfekt balansert frokost». Du bryr deg ikke mye om ord som «dette»,» ga»,» alt»,» burde», etc. Hvis en venn spør deg neste dag hva anmeldelsen sa, vil du sannsynligvis ikke huske det ord for ord. Du husker kanskje de viktigste punktene skjønt som «vil definitivt være å kjøpe igjen». Hvis du er mye som meg, vil de andre ordene forsvinne fra minnet.

og det er egentlig hva en lstm eller gru gjør. Det kan lære å holde bare relevant informasjon for å gjøre spådommer, og glemme ikke relevante data. I dette tilfellet fikk ordene du husket deg til å dømme at det var bra.
Gjennomgang Av Tilbakevendende Nevrale Nettverk
for å forstå hvordan LSTM eller GRU oppnår dette, la oss se gjennom tilbakevendende nevrale nettverk. En RNN fungerer som dette; Første ord blir forvandlet til maskinlesbare vektorer. DERETTER behandler RNN sekvensen av vektorer en etter en.

Behandler sekvens en etter en
under behandling passerer den forrige skjulte tilstanden til neste trinn i sekvensen. Den skjulte tilstanden fungerer som nevrale nettverk minne. Den inneholder informasjon om tidligere data nettverket har sett før.

neste gang trinn
la oss se på en celle i rnn for å se hvordan du vil beregne skjult tilstand. Først kombineres inngangen og forrige skjulte tilstand for å danne en vektor. Den vektoren har nå informasjon om gjeldende inngang og tidligere innganger. Vektoren går gjennom tanh-aktiveringen, og utgangen er den nye skjulte tilstanden, eller minnet til nettverket.

RNN-Celle / figcaption>
tanh-aktivering
tanh-aktiveringen brukes til å regulere verdiene som strømmer gjennom nettverket. Tanh-funksjonen squishes verdier å alltid være mellom -1 og 1.

være mellom -1 og 1
når vektorer strømmer gjennom et nevralt nettverk, gjennomgår det mange transformasjoner på grunn av ulike matematiske operasjoner. Så forestill deg en verdi som fortsetter å bli multiplisert med la oss si 3. Du kan se hvordan noen verdier kan eksplodere og bli astronomiske, noe som får andre verdier til å virke ubetydelige.

vektortransformasjoner uten tanh
en tanh-funksjon sikrer at verdiene forblir mellom -1 og 1, og regulerer dermed utgangen av det nevrale nettverket. Du kan se hvordan de samme verdiene ovenfra forblir mellom grensene som er tillatt av tanh-funksjonen.

vektortransformasjoner med tanh
så det er en rnn. Den har svært få operasjoner internt, men fungerer ganske bra gitt de rette omstendighetene (som korte sekvenser). RNNS bruker mye mindre beregningsressurser enn det er utviklet varianter, LSTM og GRU.
LSTM
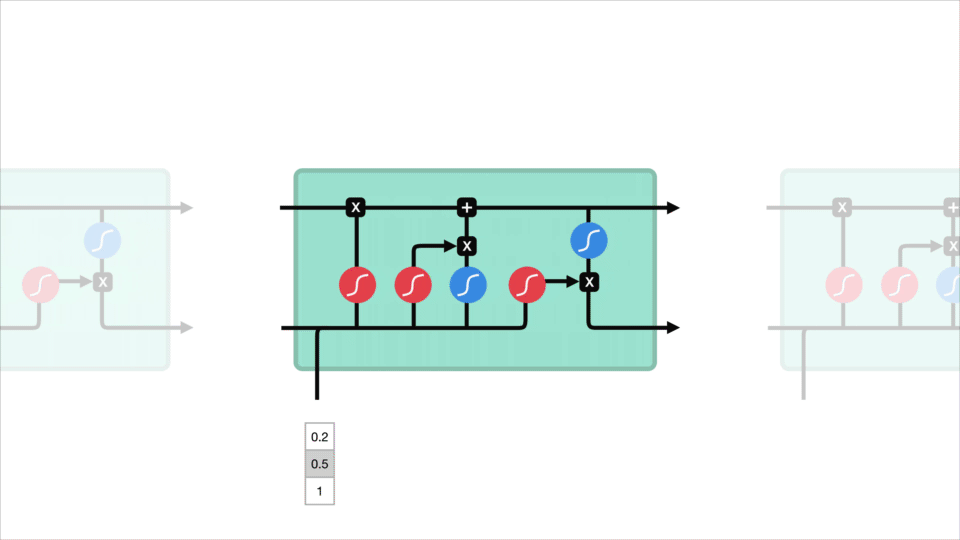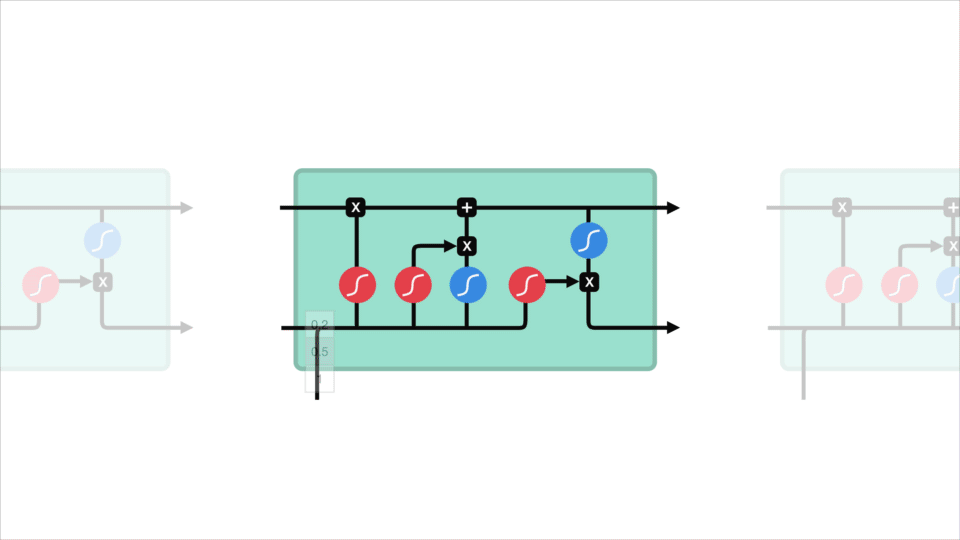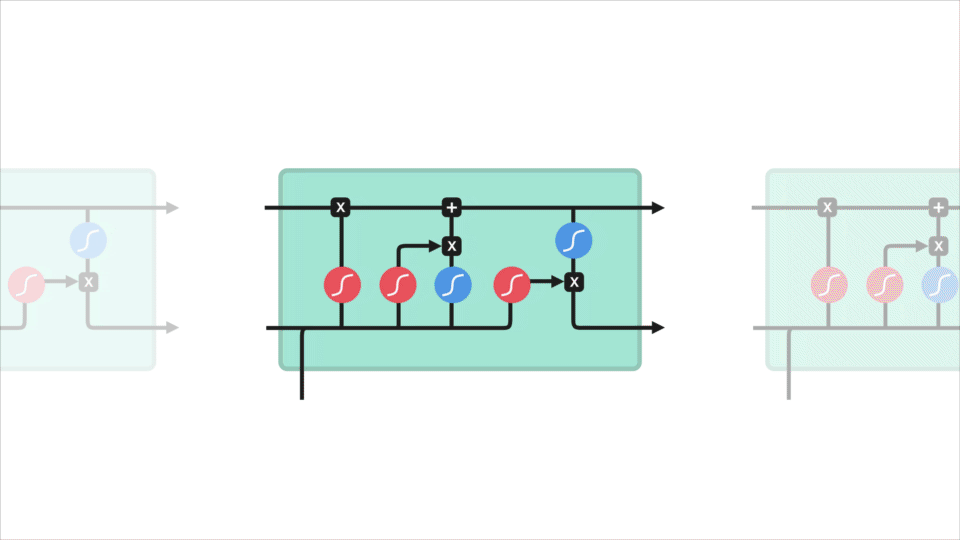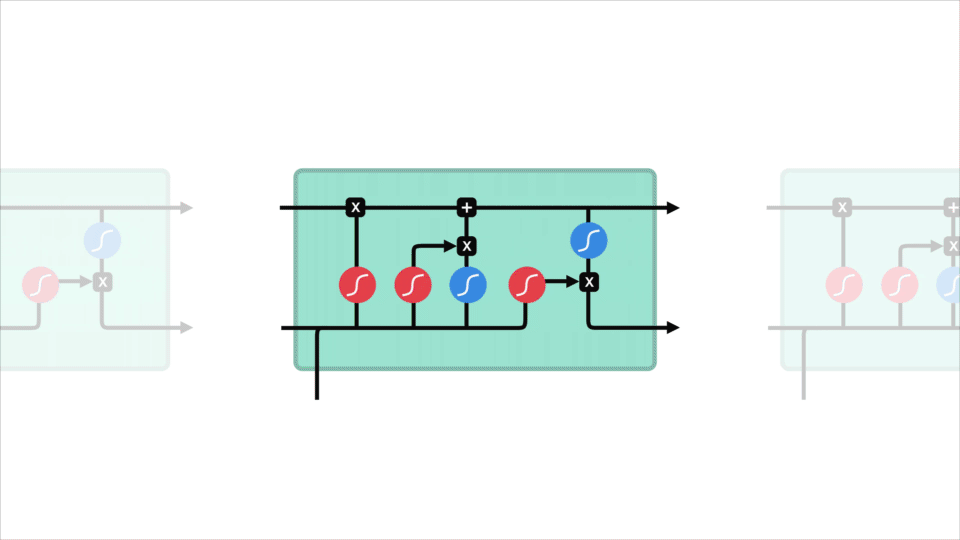
En LSTM har en lignende kontrollflyt som et tilbakevendende nevralt nettverk. Den behandler data som overfører informasjon når den forplanter seg fremover. Forskjellene er operasjonene i lstms celler.

Lstm-Celle og Det operasjoner
disse operasjonene brukes til å la lstm beholde eller glemme informasjon. Nå ser på disse operasjonene kan bli litt overveldende, så vi vil gå over dette steg for steg.
Kjernekonsept
kjernekonseptet TIL LSTM er cellestaten, og det er forskjellige porte. Celletilstanden fungerer som en transportvei som overfører relativ informasjon helt ned i sekvenskjeden. Du kan tenke på det som «minnet» av nettverket. Cellestaten, i teorien, kan bære relevant informasjon gjennom hele behandlingen av sekvensen. Så selv informasjon fra tidligere tidstrinn kan gjøre det til senere tidstrinn, noe som reduserer effekten av korttidshukommelse. Når cellestaten går på sin reise, blir informasjonen lagt til eller fjernet til cellestaten via portene. Portene er forskjellige nevrale nettverk som bestemmer hvilken informasjon som er tillatt på cellestaten. Portene kan lære hvilken informasjon som er relevant for å beholde eller glemme under trening.
Sigmoid
Portene inneholder sigmoid-aktiveringer. En sigmoid aktivering er lik tanh aktivering. I stedet for å knuse verdier mellom -1 og 1, klemmer den verdier mellom 0 og 1. Det er nyttig å oppdatere eller glemme data fordi et tall blir multiplisert med 0 er 0, noe som fører til at verdier forsvinner eller blir » glemt.»Ethvert tall multiplisert med 1 er den samme verdien derfor at verdien opphold er den samme eller er» holdt.»Nettverket kan lære hvilke data som ikke er viktige, derfor kan glemmes eller hvilke data som er viktige å beholde.

Sigmoid squishes verdier til være mellom 0 og 1
la oss grave litt dypere inn i hva de ulike portene gjør, skal vi? Så vi har tre forskjellige porter som regulerer informasjonsflyten i EN lstm-celle. En glem gate, inngang gate, og utgang gate.
Glem gate
Først har vi glem gate. Denne porten bestemmer hvilken informasjon som skal kastes eller holdes. Informasjon fra forrige skjulte tilstand og informasjon fra gjeldende inngang sendes gjennom sigmoid-funksjonen. Verdiene kommer ut mellom 0 og 1. Jo nærmere 0 betyr å glemme, og jo nærmere 1 betyr å holde.

Glem gate operasjoner/figcaption>
inngangsport
for å oppdatere cellestaten har vi inngangsporten. Først passerer vi forrige skjulte tilstand og nåværende inngang til en sigmoid-funksjon. Som bestemmer hvilke verdier vil bli oppdatert ved å transformere verdiene til å være mellom 0 og 1. 0 betyr ikke viktig, og 1 betyr viktig. Du passerer også skjult tilstand og nåværende inngang i tanh-funksjonen for å klemme verdier mellom -1 og 1 for å regulere nettverket. Deretter multipliserer du tanh-utgangen med sigmoid-utgangen. Den sigmoid utgang vil avgjøre hvilken informasjon som er viktig å holde fra tanh utgang.

figcaption>
cellestatus
nå skal vi ha nok informasjon til å beregne cellestaten. For det første blir cellestaten punktvis multiplisert med glemvektoren. Dette har en mulighet for å slippe verdier i celletilstanden hvis den blir multiplisert med verdier nær 0. Så tar vi utgangen fra inngangsporten og gjør et punktvis tillegg som oppdaterer cellestaten til nye verdier som det nevrale nettverket finner relevant. Det gir oss vår nye celletilstand.

Beregning av celletilstand / figcaption>
utgangsport
sist har vi utgangsporten. Utgangsporten bestemmer hva neste skjulte tilstand skal være. Husk at skjult tilstand inneholder informasjon om tidligere innganger. Den skjulte tilstanden brukes også til spådommer. Først passerer vi den forrige skjulte tilstanden og den nåværende inngangen til en sigmoid-funksjon. Deretter sender vi den nylig modifiserte cellestaten til tanh-funksjonen. Vi multipliserer tanh-utgangen med sigmoid-utgangen for å bestemme hvilken informasjon den skjulte tilstanden skal bære. Utgangen er skjult tilstand. Den nye cellestaten og den nye skjulte blir deretter overført til neste gang.

figcaption>
for å se gjennom, bestemmer glem gate hva som er relevant å holde fra tidligere trinn. Inngangsporten bestemmer hvilken informasjon som er relevant for å legge til fra gjeldende trinn. Utgangsporten bestemmer hva neste skjulte tilstand skal være.
Code Demo
for de av dere som forstår bedre gjennom å se koden, her er et eksempel ved hjelp av python pseudokode.

python pseudokode
1. Først blir den forrige skjulte tilstanden og den nåværende inngangen sammenkoblet. Vi kaller det kombinere.
2. Kombiner få er matet inn i glem lag. Dette laget fjerner ikke-relevante data.
4. Et kandidatlag opprettes ved hjelp av kombinere. Kandidaten har mulige verdier for å legge til cellestatus.
3. Kombiner også få er matet inn i inngangslaget. Dette laget bestemmer hvilke data fra kandidaten som skal legges til den nye cellestaten.
5. Etter å ha beregnet glemslaget, kandidatlaget og inngangslaget, beregnes celletilstanden ved hjelp av disse vektorene og den forrige celletilstanden.
6. Utgangen beregnes deretter.
7. Punktvis multiplikasjon av utgangen og den nye cellestaten gir oss den nye skjulte tilstanden.
Det er det! Kontrollflyten til ET LSTM-nettverk er noen få tensor-operasjoner og en for loop. Du kan bruke de skjulte statene for spådommer. Ved å kombinere alle disse mekanismene kan EN LSTM velge hvilken informasjon som er relevant for å huske eller glemme under sekvensbehandling.
GRU
så nå vet vi hvordan EN LSTM fungerer, la oss kort se PÅ GRU. GRU ER den nyere generasjonen Av Tilbakevendende Nevrale nettverk og er ganske lik EN LSTM. GRU kvittet seg med cellestaten og brukte den skjulte tilstanden til å overføre informasjon. Den har også bare to porter, en tilbakestillingsport og oppdateringsport.

gates
oppdateringsporten
oppdateringsporten fungerer som glem-og inngangsporten til en lstm. Det bestemmer hvilken informasjon som skal kastes og hvilken ny informasjon som skal legges til.
Reset Gate
reset gate er en annen gate brukes til å bestemme hvor mye tidligere informasjon å glemme.
Og det er EN GRU. GRU har færre tensor operasjoner; derfor er DE litt raskere å trene DA LSTM. Det er ikke en klar vinner hvilken som er bedre. Forskere og ingeniører prøver vanligvis begge å bestemme hvilken som fungerer bedre for deres brukstilfelle.
Så det er det
for å oppsummere dette, ER RNNS gode for å behandle sekvensdata for spådommer, men lider av kortsiktig minne. LSTM og GRU ble opprettet som en metode for å redusere korttidshukommelsen ved hjelp av mekanismer kalt gates. Gates er bare nevrale nettverk som regulerer strømmen av informasjon som strømmer gjennom sekvenskjeden. LSTMS og GRU er brukt i state of the art dyp læring programmer som talegjenkjenning, talesyntese, naturlig språk forståelse, etc.
hvis du er interessert i å gå dypere, her er lenker av noen fantastiske ressurser som kan gi deg et annet perspektiv i å forstå LSTM og GRU. dette innlegget ble sterkt inspirert av dem.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/https://www.youtube.com/watch?v=WCUNPb-5EYI