Av William W Wold
I løpet av de siste 6 månedene har jeg jobbet med et programmeringsspråk kalt Pinecone. Jeg vil ikke kalle det modent ennå, men det har allerede nok funksjoner som fungerer for å være brukbare, for eksempel:
- variabler
- funksjoner
- brukerdefinerte strukturer
hvis du er interessert i Det, sjekk Ut Pinecones destinasjonsside eller GitHub-repo.
jeg er ikke en ekspert. Da jeg startet dette prosjektet, hadde jeg ingen anelse om hva jeg gjorde, og det gjør jeg fortsatt ikke. jeg har tatt null klasser på språkopprettelse, lest bare litt om det på nettet, og fulgte ikke mye av rådene jeg har fått.
Og likevel gjorde jeg fortsatt et helt nytt språk. Og det fungerer. Så jeg må gjøre noe riktig.
I dette innlegget vil jeg dykke under hetten og vise deg pipeline Pinecone (og andre programmeringsspråk) bruk for å slå kildekoden til magi.
jeg vil også berøre noen av avveiningene jeg har gjort, og hvorfor jeg tok de avgjørelsene jeg gjorde.
Dette er på ingen måte en komplett opplæring om å skrive et programmeringsspråk, men det er et godt utgangspunkt hvis du er nysgjerrig på språkutvikling.
Komme I Gang
«jeg har absolutt ingen anelse om hvor jeg ville selv starte» er noe jeg hører mye når jeg forteller andre utviklere jeg skriver et språk. Hvis det er din reaksjon, vil jeg nå gå gjennom noen første beslutninger som er gjort og skritt som tas når du starter et nytt språk.
Kompilert vs Tolket
det er to hovedtyper av språk: kompilert og tolket:
- en kompilator finner ut alt et program vil gjøre, gjør det til «maskinkode» (et format datamaskinen kan kjøre veldig fort), og lagrer det for å bli utført senere.
- en tolk går gjennom kildekoden linje for linje, finne ut hva det gjør som det går.Teknisk sett kan ethvert språk kompileres Eller tolkes, men det ene eller det andre gir vanligvis mer mening for et bestemt språk. Generelt har tolking en tendens til å være mer fleksibel, mens kompilering har en tendens til å ha høyere ytelse. Men dette skraper bare overflaten av et svært komplekst tema.
jeg verdsetter ytelse, og jeg så mangel på programmeringsspråk som er både høy ytelse og enkelhetsorientert, så jeg gikk med kompilert For Pinecone.
Dette var en viktig beslutning å ta tidlig, fordi mange språkdesignbeslutninger påvirkes av det (for eksempel er statisk skriving en stor fordel for kompilerte språk, men ikke så mye for tolket).Til Tross For At Pinecone ble designet med kompilering i tankene, har Den en fullt funksjonell tolk som var den eneste måten å kjøre den på en stund. Det er flere grunner til dette, som jeg vil forklare senere.
Velge Et Språk
jeg vet at det er litt meta, men et programmeringsspråk er selv et program, og dermed må du skrive det på et språk. Jeg valgte C++ på grunn av sin ytelse og store funksjonssett. Dessuten liker jeg Faktisk Å jobbe I C++.
hvis du skriver et tolket språk, er det mye fornuftig å skrive det i en kompilert (Som C, C++ eller Swift) fordi ytelsen tapt på tolkens språk og tolken som tolker tolken din, vil sammensatte.
hvis du planlegger å kompilere, er et langsommere språk (Som Python eller JavaScript) mer akseptabelt. Kompileringstid kan være dårlig, men etter min mening er det ikke så stor en avtale som dårlig kjøretid.
Design på Høyt Nivå
et programmeringsspråk er generelt strukturert som en rørledning. Det vil si at den har flere stadier. Hvert trinn har data formatert på en bestemt, veldefinert måte. Det har også funksjoner for å transformere data fra hvert trinn til neste.
det første trinnet er en streng som inneholder hele inngangskildefilen. Den siste fasen er noe som kan kjøres. Dette vil alt bli klart når vi går gjennom Pinecone-rørledningen trinnvis.
Lexing
det første trinnet i de fleste programmeringsspråk er lexing, eller tokenizing. ‘Lex’ er kort for leksikalsk analyse, et veldig fancy ord for å dele en haug med tekst i tokens. Ordet ‘tokenizer’ gir mye mer mening, men ‘lexer’ er så gøy å si at jeg bruker det uansett.
Tokens
et token er en liten enhet av et språk. Et token kan v re en variabel eller funksjonsnavn (AKA en identifikator), en operator eller et tall.
Oppgave Av Lexeren
lexeren skal ta inn en streng som inneholder en hel fil verdt kildekoden og spytte ut en liste som inneholder hvert token.Fremtidige stadier av rørledningen vil ikke referere tilbake til den opprinnelige kildekoden, så lexeren må produsere all informasjon som trengs av dem. Årsaken til dette relativt strenge rørledningsformatet er at lexeren kan gjøre oppgaver som å fjerne kommentarer eller oppdage om noe er et tall eller en identifikator. Du vil beholde den logikken låst inne i lexeren, begge slik at du ikke trenger å tenke på disse reglene når du skriver resten av språket, og slik at du kan endre denne typen syntaks alt på ett sted.
Flex
dagen jeg startet språket, var det første jeg skrev en enkel lexer. Kort tid etter begynte jeg å lære om verktøy som tilsynelatende ville gjøre lexing enklere og mindre buggy.
det overordnede verktøyet Er Flex, et program som genererer lexers. Du gir den en fil som har en spesiell syntaks for å beskrive språkets grammatikk. Fra det genererer det Et C-program som lexes en streng og produserer ønsket utgang.
Min Beslutning
jeg valgte å beholde lexeren jeg skrev for tiden. Til slutt så jeg ikke betydelige fordeler med Å bruke Flex, i hvert fall ikke nok til å rettferdiggjøre å legge til en avhengighet og komplisere byggeprosessen.min lexer er bare noen få hundre linjer lang, og gir meg sjelden noen problemer. Å rulle min egen lexer gir meg også mer fleksibilitet, for eksempel muligheten til å legge til en operatør på språket uten å redigere flere filer.
Parsing
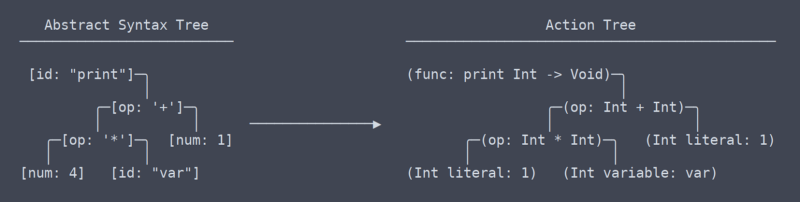
den andre fasen av rørledningen er parseren. Parseren gjør en liste over tokens til et tre av noder. Et Tre som brukes til å lagre denne typen data er kjent som Et Abstrakt Syntakstre, ELLER AST. I Hvert Fall I Pinecone har AST ingen informasjon om typer eller hvilke identifikatorer som er hvilke. Det er bare strukturerte tokens.
Parser Plikter
parseren legger struktur til i den bestilte listen over tokens lexer produserer. For å stoppe tvetydigheter må parseren ta hensyn til parentes og rekkefølgen av operasjonene. Bare parsing operatører er ikke veldig vanskelig, men etter hvert som flere språkkonstruksjoner blir lagt til, kan parsing bli svært komplisert.
Bison
Igjen var det en beslutning om å involvere et tredjepartsbibliotek. Den dominerende parsing biblioteket Er Bison. Bison fungerer mye Som Flex. Du skriver en fil i et egendefinert format som lagrer grammatikkinformasjonen, og Bison bruker det til å generere Et C-program som vil gjøre parsing. Jeg valgte Ikke Å bruke Bison.
Hvorfor Tilpasset Er Bedre
med lexeren var beslutningen om å bruke min egen kode ganske åpenbar. En lexer er et så trivielt program som ikke å skrive min egen føltes nesten like dumt som ikke å skrive min egen ‘left-pad’.
med parseren er det en annen sak. Min Pinecone parser er for tiden 750 linjer lang, og jeg har skrevet tre av dem fordi de to første var søppel.
jeg opprinnelig gjorde min beslutning for en rekke årsaker, og mens det ikke har gått helt greit, de fleste av dem holder sant. De store er som følger:
- Minimer kontekstbytte i arbeidsflyt: kontekstveksling Mellom C++ og Pinecone er ille nok uten å kaste Inn bisons grammatikkgrammatikk grammatikk
- Keep build simple: hver gang grammatikken endres, Må Bison kjøres før bygningen. Dette kan automatiseres, men det blir en smerte når du bytter mellom byggesystemer.
- jeg liker å bygge kul dritt: jeg gjorde Ikke Pinecone fordi jeg trodde det ville være enkelt, så hvorfor skulle jeg delegere en sentral rolle når jeg kunne gjøre det selv? En tilpasset parser kan ikke være trivielt, men det er helt gjennomførbart.
i begynnelsen var jeg ikke helt sikker på om jeg gikk ned en levedyktig sti, men jeg fikk tillit av Hva Walter Bright (en utvikler på en tidlig versjon Av C++, og skaperen Av d-språket) måtte si om emnet:
«Noe mer kontroversielt, jeg ville ikke bry å kaste bort tid med lexer eller parser generatorer og andre såkalte» kompilator kompilatorer.»De er bortkastet tid. Skrive en lexer og parser er en liten prosentandel av jobben med å skrive en kompilator. Bruk av en generator vil ta opp omtrent like mye tid som å skrive en for hånd ,og det vil gifte deg med generatoren (som betyr noe når du overfører kompilatoren til en ny plattform). Og generatorer har også uheldig rykte for å sende ut elendig feilmeldinger.»
Handlingstreet
Vi har nå forlatt området med vanlige, universelle termer, eller i det minste vet jeg ikke hva vilkårene er lenger. Fra min forståelse er det jeg kaller ‘action tree’ mest lik LLVMS IR (intermediate representation).
det er en subtil, men svært signifikant forskjell mellom handlingstreet og det abstrakte syntakstreet. Det tok meg en stund å finne ut at det selv skulle være en forskjell mellom dem (som bidro til behovet for omskrivninger av parseren).
Handlingstreet vs AST
enkelt sagt er handlingstreet AST med kontekst. Den konteksten er informasjon som hvilken type en funksjon som returnerer, eller at to steder der en variabel brukes, faktisk bruker den samme variabelen. Fordi den trenger å finne ut og huske all denne konteksten, trenger koden som genererer handlingstreet mange navneområdeoppslagstabeller og andre thingamabobs.
Kjører Handlingstreet
når vi har handlingstreet, er det enkelt å kjøre koden. Hver handling node har en funksjon ‘execute’ som tar noen innspill, gjør hva handlingen skal (inkludert muligens ringer under handling) og returnerer handlingens utgang. Dette er tolken i aksjon.
Kompileringsalternativer
» men vent!»Jeg hører du sier ,»er Ikke Pinecone ment å være kompilert?»Ja, det er det. Men kompilering er vanskeligere enn å tolke. Det er noen mulige tilnærminger.
Bygg Min Egen Kompilator
dette hørtes ut som en god ide for meg først. Jeg elsker å lage ting selv, og jeg har vært kløe for en unnskyldning for å bli god på montering.Dessverre er det ikke så enkelt å skrive en bærbar kompilator som å skrive noen maskinkode for hvert språkelement. På grunn av antall arkitekturer og operativsystemer, er det upraktisk for enhver person å skrive en cross platform compiler backend.Selv lagene bak Swift, Rust og Clang vil ikke bry seg med alt på egen hånd, så i stedet bruker de alle…
LLVM
LLVM er en samling kompilatorverktøy. Det er i utgangspunktet et bibliotek som vil gjøre språket ditt til en kompilert kjørbar binær. Det virket som det perfekte valget, så jeg hoppet rett inn. Dessverre sjekket jeg ikke hvor dypt vannet var, og jeg druknet umiddelbart.LLVM, MENS ikke assembly hard, er gigantisk kompleks bibliotek vanskelig. Det er ikke umulig å bruke, og de har gode opplæringsprogrammer, men jeg skjønte at jeg måtte få litt øvelse før jeg var klar til å fullt ut implementere En Pinecone-kompilator med den.
Transpiling
jeg ville ha en slags kompilert Pinecone og jeg ville ha det raskt, så jeg vendte meg til en metode jeg visste at jeg kunne gjøre arbeid: transpiling.
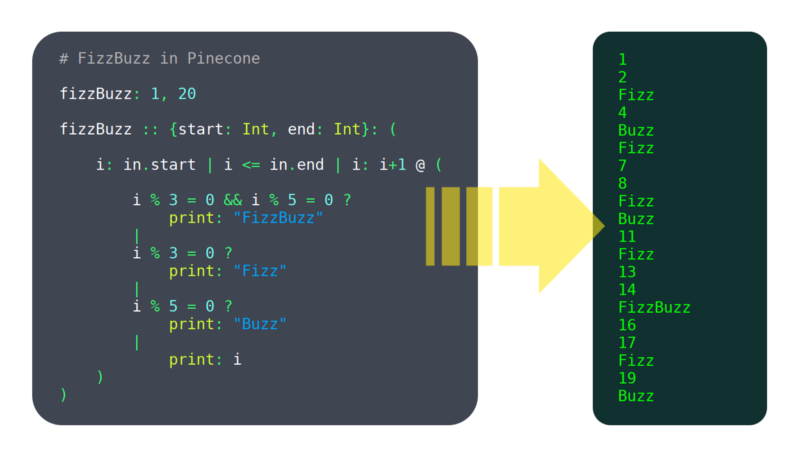
jeg skrev En Pinecone Til C++ transpiler, og la til muligheten til å automatisk kompilere utgangskilden med GCC. Dette fungerer for tiden for nesten alle Pinecone-programmer (selv om det er noen kantsaker som bryter det). Det er ikke en spesielt bærbar eller skalerbar løsning, men det fungerer for tiden.
Future
Forutsatt at jeg fortsetter å utvikle Pinecone, vil DEN FÅ LLVM-kompileringsstøtte før eller senere. Jeg mistenker ingen mater hvor mye jeg jobber med det, transpiler vil aldri være helt stabil og fordelene MED LLVM er mange. Det er bare et spørsmål om når jeg har tid til å lage noen prøveprosjekter I LLVM og få tak i det.
Inntil da er tolken stor for trivielle programmer og C++ transpiling fungerer for de fleste ting som trenger mer ytelse.
Konklusjon
jeg håper jeg har gjort programmeringsspråk litt mindre mystisk for deg. Hvis du vil lage en selv, anbefaler jeg det. Det er massevis av implementeringsdetaljer å finne ut, men oversikten her bør være nok til å komme i gang.
Her er mitt høyt nivå råd for å komme i gang (husk, jeg vet egentlig ikke hva jeg gjør, så ta det med et saltkorn):
- hvis du er i tvil, gå tolket. Tolket språk er generelt enklere design, bygge og lære. Jeg fraråder deg ikke å skrive en kompilert hvis du vet det er det du vil gjøre, men hvis du er på gjerdet, ville jeg tolket.
- når det gjelder lexers og parsers, gjør hva du vil. Det er gyldige argumenter for og mot å skrive din egen. Til slutt, hvis du tenker ut ditt design og implementerer alt på en fornuftig måte, spiller det ingen rolle.
- Lær av rørledningen jeg endte opp med. Mye prøving og feiling gikk inn i utformingen av rørledningen jeg har nå. Jeg har forsøkt å eliminere ASTs, ASTs som blir til handlinger trær på plass, og andre forferdelige ideer. Denne rørledningen fungerer, så ikke endre den med mindre du har en veldig god ide.
- hvis du ikke har tid eller motivasjon til å implementere et komplekst generelt språk, kan du prøve å implementere et esoterisk språk som Brainfuck. Disse tolkene kan være så kort som noen få hundre linjer.
jeg har svært få angrer når det gjelder Pinecone utvikling. Jeg gjorde en rekke dårlige valg underveis, men jeg har omskrevet det meste av koden som er berørt av slike feil.Akkurat Nå Er Pinecone i en god nok tilstand at den fungerer bra og lett kan forbedres. Skrive Pinecone har vært en enormt lærerik og hyggelig opplevelse for meg, og det er bare å komme i gang.