Versjon info: Koden for denne siden ble testet I Stata 12.
Poisson regresjon brukes til å modellere telle variabler.
merk: formålet med denne siden er å vise hvordan du bruker ulike dataanalysekommandoer. Det dekker ikke alle aspekter av forskningsprosessen som forskere forventes å gjøre. Den omfatter særlig ikke datarensing og kontroll, verifisering av forutsetninger, modelldiagnostikk eller potensielle oppfølgingsanalyser.
Eksempler På Poisson-regresjon
Eksempel 1. Antall personer drept av mule eller hest spark i den Prøyssiske hæren per år.Ladislaus Bortkiewicz samlet data fra 20 volumer ofPreussischen Statistikk. Disse dataene ble samlet på 10 korps Av Den Prøyssiske hæren på slutten av 1800-tallet i løpet av 20 år.
Eksempel 2. Antall personer i kø foran deg på matbutikken. Prediktorer kan inkludere antall varer som for øyeblikket tilbys til en spesiell nedsatt pris, og om en spesiell begivenhet (f.eks. en ferie, en stor sportsbegivenhet) er tre eller færre dager unna.
Eksempel 3. Antall priser opptjent av studenter på en videregående skole. Prediktorer av antall priser opptjent inkluderer typen program der studenten ble registrert (f.eks. yrkesrettet, generell eller akademisk) og poengsummen på slutteksamen i matte.
Beskrivelse av dataene
for illustrasjonsformål har vi simulert et datasett for eksempel 3 ovenfor. I dette eksemplet er num_awards utfallsvariabelen og angir antall priser opptjent av studenter på en videregående skole i et år, matematikk er en kontinuerlig prediktorvariabel og representerer elevers score på matematikkeksamen, og prog er en kategorisk prediktorvariabel med tre nivåer som indikerer hvilken type program studentene ble registrert i.
La oss starte med å laste inn dataene og se på noen beskrivende statistikk.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
hver variabel har 200 gyldige observasjoner og deres fordelinger virker ganske rimelige. I dette spesielle er ubetinget gjennomsnitt og varians av utfallsvariabelen ikke ekstremt forskjellig.
La oss fortsette med vår beskrivelse av variablene i dette datasettet. Tabellen nedenfor viser gjennomsnittlig antall priser etter programtype og synes å tyde på at programtype er en god kandidat for å forutsi antall priser, vår utfallsvariabel, fordi gjennomsnittsverdien av utfallet ser ut til å variere etter prog.
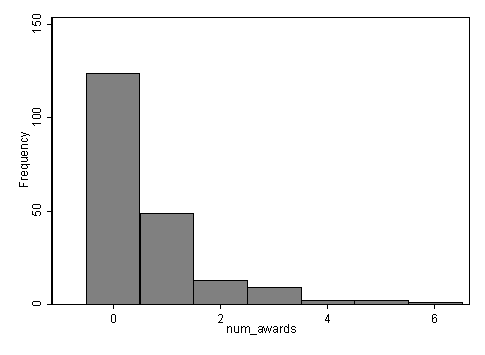
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
analysemetoder du kan vurdere
nedenfor er en liste over noen analysemetoder du kan ha møtt. Noen av metodene som er oppført er ganske rimelige, mens andre enten har falt ut av favør eller har begrensninger.
- Poisson regresjon-Poisson regresjon brukes ofte til modellering av telledata. Poisson regresjon har en rekke utvidelser som er nyttige for tellemodeller.
- Negativ binomial regresjon-Negativ binomial regresjon kan brukes til over-dispergerte telledata, det vil si når den betingede variansen overstiger det betingede gjennomsnittet. Det kan betraktes som en generalisering Av Poisson-regresjon siden Den har samme middelstruktur Som Poisson-regresjon, og den har en ekstra parameter for å modellere over-dispersjonen. Hvis den betingede fordelingen av utfallsvariabelen er over-spredt, vil konfidensintervallene For Negativ binomialregresjon sannsynligvis være smalere sammenlignet Med De Fra En Poisson-regresjon.Null-oppblåst regresjonsmodell-null-oppblåste modeller forsøker å regne for overskytende nuller. Med andre ord, to typer nuller antas å eksistere i dataene, «sanne nuller» og «overflødige nuller». Null-oppblåste modeller estimerer to ligninger samtidig, en for tellemodellen og en for overskytende nuller.
- OLS regresjon – Count utfall variabler er noen ganger log-transformert og analysert VED HJELP AV OLS regresjon. Mange problemer oppstår med denne tilnærmingen, inkludert tap av data på grunn av udefinerte verdier generert ved å ta loggen null (som er udefinert) og partiske estimater.
Poisson regresjon
Nedenfor bruker vi poisson-kommandoen for å estimere En Poisson regresjonsmodell. I. før prog indikerer at det er en faktor variabel (dvs., kategorisk variabel), og at den skal inkluderes i modellen som en serie indikatorvariabler.
Vi bruker alternativet vce(robust) for å oppnå robuste standardfeil for parameterestimatene som Anbefalt av Cameron and Trivedi (2009) for å kontrollere for mildt brudd på underliggende forutsetninger.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
de to grad-av-frihet chi-kvadrat test indikerer at prog, tatt sammen, er en statistisk signifikant prediktor for num_awards.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
Dette er ikke en test av modellkoeffisientene (som vi så i topptekstinformasjonen), men en test av modellformen: passer poisson-modellformen til våre data?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
vi konkluderer med at modellen passer rimelig bra fordi godhetsprøven i kjikvadratet ikke er statistisk signifikant. Hvis testen hadde vært statistisk signifikant, ville det indikere at dataene ikke passer godt til modellen. I den situasjonen kan vi prøve å avgjøre om det er utelatte prediktorvariabler, hvis vår linearitetsforutsetning holder og / eller om det er et problem med overdispersjon. Noen ganger vil vi kanskje presentere regresjonsresultatene som hendelsesfrekvensforhold, vi kan bruke deres r-alternativ. DISSE IRR-verdiene er lik våre koeffisienter fra utgangen over eksponentiert.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
utgangen ovenfor indikerer at hendelsesraten for 2.prog er 2,96 ganger hendelsesraten for referansegruppen (1.prog). På samme måte er hendelsesraten for 3.prog er 1,45 ganger hendelsesraten for referansegruppen som holder de andre variablene konstant. Prosentendringen i hendelsesraten for num_awards er en økning på 7% for hver enhetsøkning i matte.
Recall form av vår modell ligningen:
logg(num_awards) = Avskjære + b1(prog=2) + b2 ( prog=3) + b3math.
dette innebærer:
num_awards = exp(Intercept + b1(prog=2) + b2(prog=3)+ b3math) = exp(Intercept) * exp(b1(prog=2)) * exp(b2(prog=3))) * exp(b3math)
koeffisientene har en additiv effekt i log(y) skalaen og irr har en multiplikativ effekt i y-skalaen. For ytterligere informasjon om de ulike beregningene der resultatene kan presenteres, og tolkningen av slike, se Regresjonsmodeller For Kategoriske Avhengige Variabler Ved Hjelp Av Stata, Andre Utgave Av J. Scott Long og Jeremy Freese (2006).
for å forstå modellen bedre, kan vi bruke marginer-kommandoen. Nedenfor bruker vi kommandoen marginer til å beregne de forventede tellingene på hvert nivå avprog, og holder alle andre variabler (i dette eksemplet matte) i modellen på deres middelverdier.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
i utgangen ovenfor ser vi at det forutsagte antall hendelser for nivå 1 av prog er ca.21, holder matte på sitt middel. Det forventede antall hendelser for nivå 2 av prog er høyere på .62, og det forutsagte antall hendelser for nivå 3 av prog er ca .31. Merk at den forutsagte tellingen av nivå 2 av prog er (.6249446/.211411) = 2,96 ganger høyere enn forventet antall for nivå 1 av prog. Dette samsvarer med DET vi så I IRR-utgangstabellen.
Nedenfor vil vi få de forutsagte teller for verdier av matematikk som spenner fra 35 til 75 i trinn på 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
tabellen over viser at med prog ved sine observerte verdier og matte holdt på 35 for alle observasjoner, er gjennomsnittlig forventet telling (eller gjennomsnittlig antall priser) omtrent .13; når matte = 75, er gjennomsnittlig forventet telling omtrent 2,17. Hvis vi sammenligner de forutsagte tellingene i matte = 35 og matte = 45, kan vi se at forholdet er (.2644714/.1311326) = 2.017. DETTE samsvarer MED IRR av 1.0727 for en 10 enhet endring: 1.0727^10 = 2.017.
den brukerskrevne fitstat-kommandoen (Samt statas estat-kommandoer) kan brukes til å skaffe ytterligere informasjon som kan være nyttig hvis du vil sammenligne modeller. Du kan skrive søk fitstat for å laste ned dette programmet (se Hvordan kan jeg bruke søkekommandoen til å søke etter programmer og få ekstra hjelp? for mer informasjon om bruk av søk).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
du kan tegne grafen for det antatte antallet hendelser med kommandoene nedenfor. Grafen indikerer at de fleste priser er spådd for de i det akademiske programmet (prog = 2), spesielt hvis studenten har en høy matte score. Det laveste antall forventede priser er for de studentene i det generelle programmet (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
ting å vurdere
- hvis overdispersion ser ut til å være et problem, bør vi først sjekk om vår modell er riktig spesifisert, for eksempel utelatte variabler og funksjonelle skjemaer. For eksempel, hvis vi utelot prediktorvariabelen progin eksemplet ovenfor, synes vår modell å ha et problem med overdispersjon. Med andre ord kan en feilspesifisert modell presentere et symptom som et over-dispersjonsproblem.
- Forutsatt at modellen er riktig angitt, vil du kanskje sjekke foroverdispersion. Det er flere måter å gjøre dette på, inkludert sannsynlighets-ratio-testen av over-dispersjonsparameteren alfa ved å kjøre den samme regresjonsmodellen ved hjelp av negativ binomialfordeling (nbreg).
- en vanlig årsak til over-dispersjon er overskytende nuller, som igjen genereres av en ekstra datagenereringsprosess. I denne situasjonen bør nulloppblåst modell vurderes.
- hvis datagenereringsprosessen ikke tillater noen 0s (for eksempel antall dager brukt på sykehuset), kan en null-avkortet modell være mer hensiktsmessig.
- Telledata har ofte en eksponeringsvariabel, som angir antall ganger hendelsen kunne ha skjedd. Denne variabelen bør inkorporeres I En Poisson-modell ved bruk av exp () – alternativet.
- utfallsvariabelen i En Poisson-regresjon kan ikke ha negative tall, og eksponeringen kan ikke ha 0s.
- i Stata kan En Poisson-modell estimeres via glm-kommandoen med loggkoblingen og Poisson-familien.
- du må bruke glm-kommandoen for å få restene til å sjekke andre forutsetninger For Poisson-modellen (Se Cameron and Trivedi (1998) og Dupont (2002) for mer informasjon).
- Mange forskjellige tiltak av pseudo-r-kvadrat eksisterer. De forsøker alle å gi informasjon som ligner Den som er gitt Av R-squared i OLS-regresjon, selv om ingen av dem kan tolkes nøyaktig som R-squared i OLS-regresjon tolkes. For en diskusjon av ulike pseudo-R-firkanter, se Long and Freese (2006) eller VÅR FAQ-sidehva er pseudo R-squareds?.
- Poisson regresjon er estimert via maksimal sannsynlighet estimering. Det krever vanligvis en stor prøvestørrelse.
Se også
- Kommenterte utdata for poisson-kommandoen
- STATA FAQ: Hvordan kan jeg bruke countfit i å velge en tellemodell?
- Stata online manual
- poisson
- Stata Vanlige Spørsmål
- Hvordan beregnes Standardfeilene og konfidensintervallene for Insidensrater (Irr) av poisson og nbreg?
- Cameron, A. C. Og Trivedi, P. K. (2009). Mikroøkonometri Ved Hjelp Av Stata. College Station, TX:Stata Press.Cameron, A. C. Og Trivedi, P. K. (1998). Regresjonsanalyse Av Telledata. New York: Cambridge Press.S.Cameron, Ac Fremskritt I Telle Data Regresjon Snakke For Anvendt Statistikk Workshop, Mars 28, 2009.http://cameron.econ.ucdavis.edu/racd/count.html .Dupont, W. D. (2002). Statistisk Modellering For Biomedisinske Forskere: En Enkel Introduksjon til Analyse Av Komplekse Data. New York: Cambridge Press.S.
- Long, J. S. (1997). Regresjonsmodeller For Kategoriske Og Begrensede Avhengige Variabler.Thousand Oaks, CA: Sage Publikasjoner.
- Long, J. s. Og Freese, J. (2006). Regresjonsmodeller For Kategoriske Avhengige Variabler Ved Bruk Av Stata, Andre Utgave. College Station, TX:Stata Press.