Sist Oppdatert 17. februar 2021
en prediksjon fra et maskinlæringsperspektiv er et enkelt punkt som skjuler usikkerheten i denne prediksjonen.
Prediksjonsintervaller gir en måte å kvantifisere og kommunisere usikkerheten i en prediksjon. De er forskjellige fra konfidensintervaller som i stedet søker å kvantifisere usikkerheten i en populasjonsparameter som et gjennomsnitt eller standardavvik. Prediksjonsintervaller beskriver usikkerheten for et enkelt bestemt utfall.
i denne opplæringen vil du oppdage prediksjonsintervallet og hvordan du beregner det for en enkel lineær regresjonsmodell.
etter å ha fullført denne opplæringen, vil du vite:
- At et prediksjonsintervall kvantifiserer usikkerheten til en enkeltpunktsprognose.
- at prediksjonsintervaller kan estimeres analytisk for enkle modeller, men er mer utfordrende for ikke-lineære maskinlæringsmodeller.
- hvordan beregne prediksjonsintervallet for en enkel lineær regresjonsmodell.Kick-start prosjektet med min nye Bok Statistikk For Maskinlæring, inkludert trinn-for-trinn tutorials og Python kildekodefiler for alle eksempler.
La oss komme i gang.
- Oppdatert Juni / 2019: Korrigert signifikansnivå som en brøkdel av standardavvik.
- Oppdatert April / 2020: Fast skrivefeil i plott av prediksjonsintervall.

Prediksjonsintervaller for Maskinlæring
Foto Av Jim Bendon, noen rettigheter reservert.Tutorial Oversikt
denne opplæringen er delt inn i 5 deler; de er:
- Hva Er Galt med Et Punktestimat?
- Hva Er Et Prediksjonsintervall?
- Hvordan Beregne Et Prediksjonsintervall
- Prediksjonsintervall For Lineær Regresjon
- Jobbet Eksempel
Trenger Du Hjelp Med Statistikk for Maskinlæring?
Ta min gratis 7-dagers e-lynkurs nå (med eksempelkode).
Klikk for å registrere deg og få også en GRATIS Pdf Ebook-versjon av kurset.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
1yhat = model.predict (x)hvor yhat er estimert utfall eller prediksjon gjort Av den trente modellen For de gitte inngangsdata X.
Dette er et punkt prediksjon.
per definisjon er det et estimat eller en tilnærming og inneholder noe usikkerhet.
usikkerheten kommer fra feilene i selve modellen og støy i inngangsdataene. Modellen er en tilnærming av forholdet mellom inngangsvariablene og utgangsvariablene.
gitt prosessen som brukes til å velge og justere modellen, vil det være den beste tilnærmingen gitt tilgjengelig informasjon, men det vil fortsatt gjøre feil. Data fra domenet vil naturlig skjule det underliggende og ukjente forholdet mellom input-og output-variablene. Dette vil gjøre det til en utfordring å passe modellen, og vil også gjøre det til en utfordring for en fit modell å gjøre spådommer.Gitt disse to hovedkildene til feil, er deres punktprediksjon fra en prediktiv modell utilstrekkelig for å beskrive den sanne usikkerheten i prediksjonen.
Hva Er Et Prediksjonsintervall?
et prediksjonsintervall er en kvantifisering av usikkerheten på en prediksjon.
det gir en probabilistisk øvre og nedre grenser på estimatet av en utfallsvariabel.
et prediksjonsintervall for en enkelt fremtidig observasjon er et intervall som med en spesifisert grad av tillit vil inneholde en fremtidig tilfeldig valgt observasjon fra en fordeling.
— Side 27, Statistiske Intervaller: En Veiledning for Utøvere og Forskere, 2017.
Prediksjonsintervaller brukes oftest når du gjør spådommer eller prognoser med en regresjonsmodell, hvor en mengde blir spådd.
et eksempel på presentasjonen av et prediksjonsintervall er som følger:
Gitt en prediksjon av ‘ y ‘gitt ‘ x’, er det en 95% sannsynlighet for at området ‘a’ til ‘b’ dekker det sanne utfallet.
prediksjonsintervallet omgir prediksjonen laget av modellen og forhåpentligvis dekker området for det sanne utfallet.
diagrammet nedenfor bidrar til å visuelt forstå forholdet mellom prediksjon, prediksjon intervall, og det faktiske utfallet.
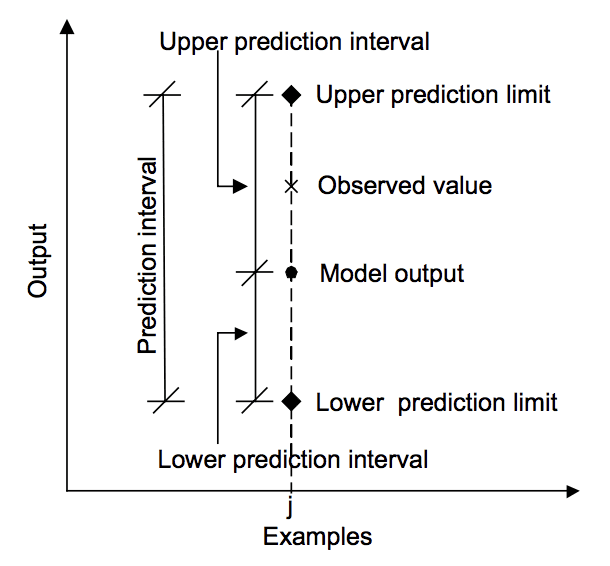
Forholdet mellom prediksjon, faktisk verdi og prediksjonsintervall.
Hentet Fra «Machine learning approaches for estimering av prediksjonsintervall for modellutgangen», 2006.et prediksjonsintervall er forskjellig fra et konfidensintervall.
et konfidensintervall kvantifiserer usikkerheten på en estimert populasjonsvariabel, for eksempel gjennomsnitts-eller standardavviket. Mens et prediksjonsintervall kvantifiserer usikkerheten på en enkelt observasjon estimert fra befolkningen.i prediktiv modellering kan et konfidensintervall brukes til å kvantifisere usikkerheten til den estimerte ferdigheten til en modell, mens et prediksjonsintervall kan brukes til å kvantifisere usikkerheten til en enkelt prognose.
et prediksjonsintervall er ofte større enn konfidensintervallet, da det må tas hensyn til konfidensintervallet og variansen i utgangsvariabelen.
Prediksjonsintervaller vil alltid være bredere enn konfidensintervaller fordi de står for usikkerheten knyttet til e, den irreducible feilen.
— Side 103, En Introduksjon Til Statistisk Læring: Med Applikasjoner I R, 2013.
Hvordan Beregne Et Prediksjonsintervall
et prediksjonsintervall beregnes som en kombinasjon av estimert varians av modellen og variansen av utfallsvariabelen.
Prediksjonsintervaller er enkle å beskrive, men vanskelig å beregne i praksis.
i enkle tilfeller som lineær regresjon, kan vi estimere prediksjonsintervallet direkte.i tilfeller av ikke-lineære regresjonsalgoritmer, som kunstige nevrale nettverk, er det mye mer utfordrende og krever valg og implementering av spesialiserte teknikker. Generelle teknikker som bootstrap resampling metoden kan brukes, men er beregningsmessig dyrt å beregne.papiret» En Omfattende Gjennomgang Av Nevrale Nettverksbaserte Prediksjonsintervaller og Nye Fremskritt » gir en rimelig nylig studie av prediksjonsintervaller for ikke-lineære modeller i sammenheng med nevrale nettverk. Følgende liste oppsummerer noen metoder som kan brukes til prediksjonsusikkerhet for ikke-lineære maskinlæringsmodeller:
- Delta-Metoden, fra feltet ikke-lineær regresjon.Den Bayesianske Metoden, Fra Bayesiansk modellering og statistikk.
- Gjennomsnittlig Varians Estimeringsmetode, ved hjelp av estimert statistikk.
- Bootstrap-Metoden, ved hjelp av data resampling og utvikling av et ensemble av modeller.
vi kan gjøre beregningen av et prediksjonsintervall betong med et bearbeidet eksempel i neste avsnitt.
Prediksjonsintervall for Lineær Regresjon
en lineær regresjon er en modell som beskriver den lineære kombinasjonen av innganger for å beregne utgangsvariablene.
For example, an estimated linear regression model may be written as:
1yhat = b0 + b1 . xWhere yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
vi vet ikke de sanne verdiene til koeffisientene b0 og b1. Vi vet heller ikke de sanne populasjonsparametrene som gjennomsnitt og standardavvik for x eller y. Alle disse elementene må estimeres, noe som introduserer usikkerhet i bruken av modellen for å gjøre spådommer.
Vi kan gjøre noen forutsetninger, for eksempel fordelingene av x og y og prediksjonsfeilene gjort av modellen, kalt residuals, Er Gaussiske.
prediksjonsintervallet rundt yhat kan beregnes som følger:
1yhat +/- z * sigmaWhere yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
Vi vet ikke i praksis. Vi kan beregne et objektivt estimat av den forventede standardavviket som følger (tatt Fra Maskinlæringsmetoder for estimering av prediksjonsintervall for modellutgangen):
1stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
Jobbet Eksempel
La oss gjøre tilfelle av lineære regresjon prediksjon intervaller betong med en jobbet eksempel.
la Oss først definere et enkelt to-variabelt datasett hvor utgangsvariabelen (y) avhenger av inngangsvariabelen (x) med Noe Gaussisk støy.
eksemplet nedenfor definerer datasettet vi vil bruke for dette eksemplet.
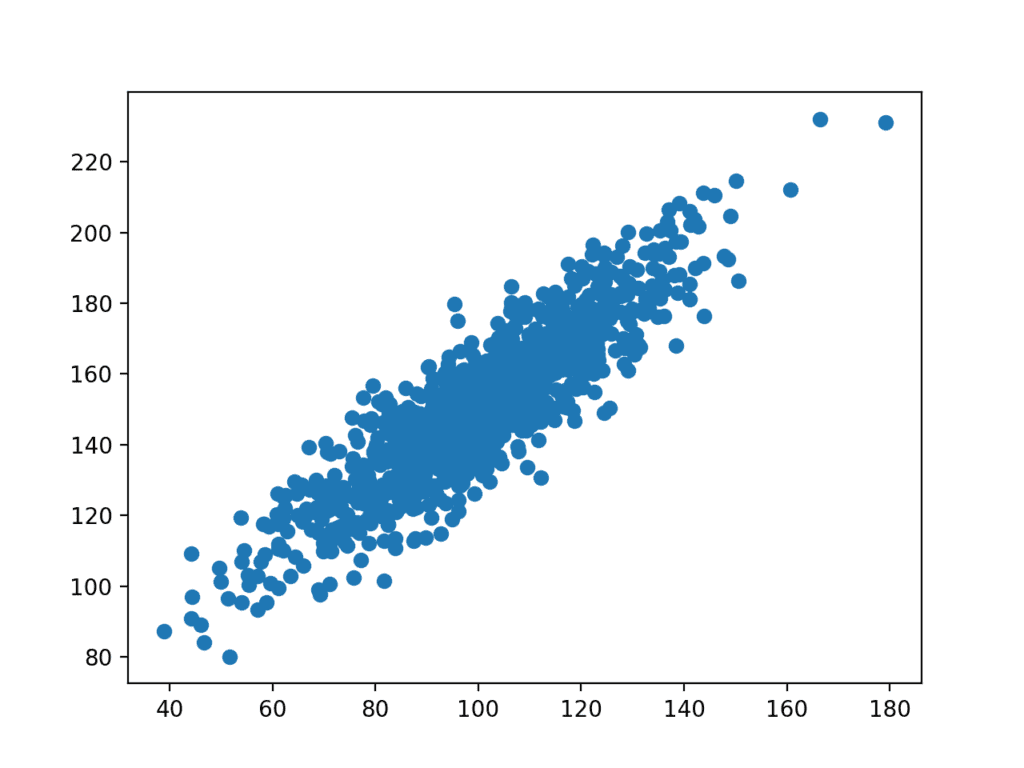
124567891011121314151617# generer relaterte variablerfra numpy import betyrfra numpy import stdfrom numpy.random import randnfrom numpy.random import seedfrom matplotlib import pyplot# seed random number generatorseed(1)# prepare datax = 20 * randn(1000) + 100y = x + (10 * randn(1000) + 50)# summarizeprint(‘x: mean=%.3f stdv=%.3f’ % (mean(x), std(x)))print(‘y: mean=%.3f stdv=%.3f’ % (mean(y), std(y)))# plotpyplot.scatter(x, y)pyplot.show()Running the example first prints the mean and standard deviations of the two variables.
12x: mean=100.776 stdv=19.620y: mean=151.050 stdv=22.358et plott av datasettet blir da opprettet.
Vi kan se det klare lineære forholdet mellom variablene med spredningen av punktene som fremhever støy eller tilfeldig feil i forholdet.
deretter kan vi utvikle en enkel lineær regresjon som gitt inngangsvariabelen x, vil forutsi y-variabelen. Vi kan bruke linregress () SciPy-funksjonen til å passe modellen og returnere b0-og b1-koeffisientene for modellen.
12# fit linear regression modelb1, b0, r_value, p_value, std_err = linregress(x, y)We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
12# make predictionyhat = b0 + b1 * xThe complete example is listed below.
12456789
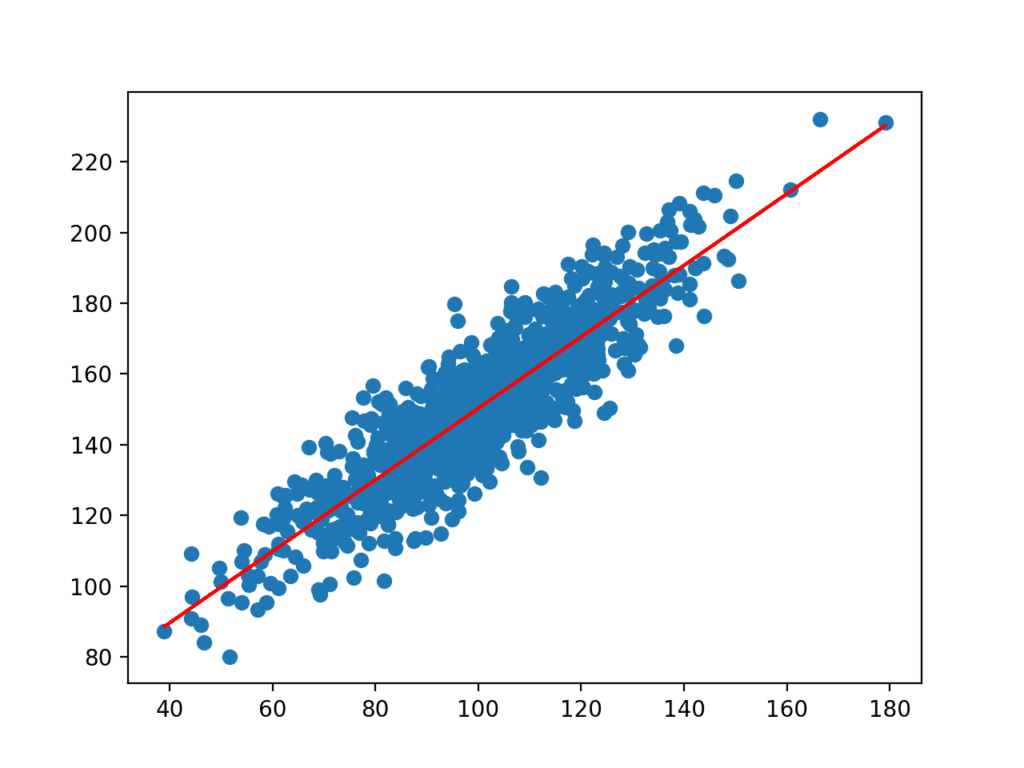
10111213141516171819# enkel ikke-lineær regresjonsmodellfra numpy.random import randnfrom numpy.random import seedfrom scipy.stats import linregressfrom matplotlib import pyplot# seed random number generatorseed(1)# prepare datax = 20 * randn(1000) + 100y = x + (10 * randn(1000) + 50)# fit linear regression modelb1, b0, r_value, p_value, std_err = linregress(x, y)print(‘b0=%.3f, b1=%.3f’ % (b1, b0))# make predictionyhat = b0 + b1 * x# plot data and predictionspyplot.scatter(x, y)pyplot.plot(x, yhat, color=’r’)pyplot.show()Running the example fits the model and prints the coefficients.
1b0=1.011, b1=49.117koeffisientene brukes deretter med inngangene fra datasettet for å lage en prediksjon. De resulterende inngangene og forventede y-verdiene tegnes som en linje på toppen av spredningsplottet for datasettet.
vi kan tydelig se at modellen har lært det underliggende forholdet i datasettet.
Vi er nå klare Til å lage en prediksjon med vår enkle lineære regresjonsmodell og legge til et prediksjonsintervall.
vi passer til modellen som før. Denne gangen vil vi ta en prøve fra datasettet for å demonstrere prediksjonsintervallet. Vi vil bruke inngangen til å lage en prediksjon, beregne prediksjonsintervallet for prediksjonen, og sammenligne prediksjonen og intervallet med den kjente forventede verdien.
la Oss først definere inndata, prediksjon og forventede verdier.
13x_in=xy_out = yyhat_out = yhat
deretter kan vi estimere standardkrumningen i prediksjonsretningen.
1SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)We can calculate this directly using the NumPy arrays as follows:
123# estimate stdev of yhatsum_errs = arraysum((y – yhat)**2)stdev = sqrt(1/(len(y)-2) * sum_errs)Next, we can calculate the prediction interval for our chosen input:
1interval = z . stdevWe will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
123# calculate prediction intervalinterval = 1.96 * stdevlower, upper = yhat_out – interval, yhat_out + intervalWe can tie all of this together. The complete example is listed below.
12456789
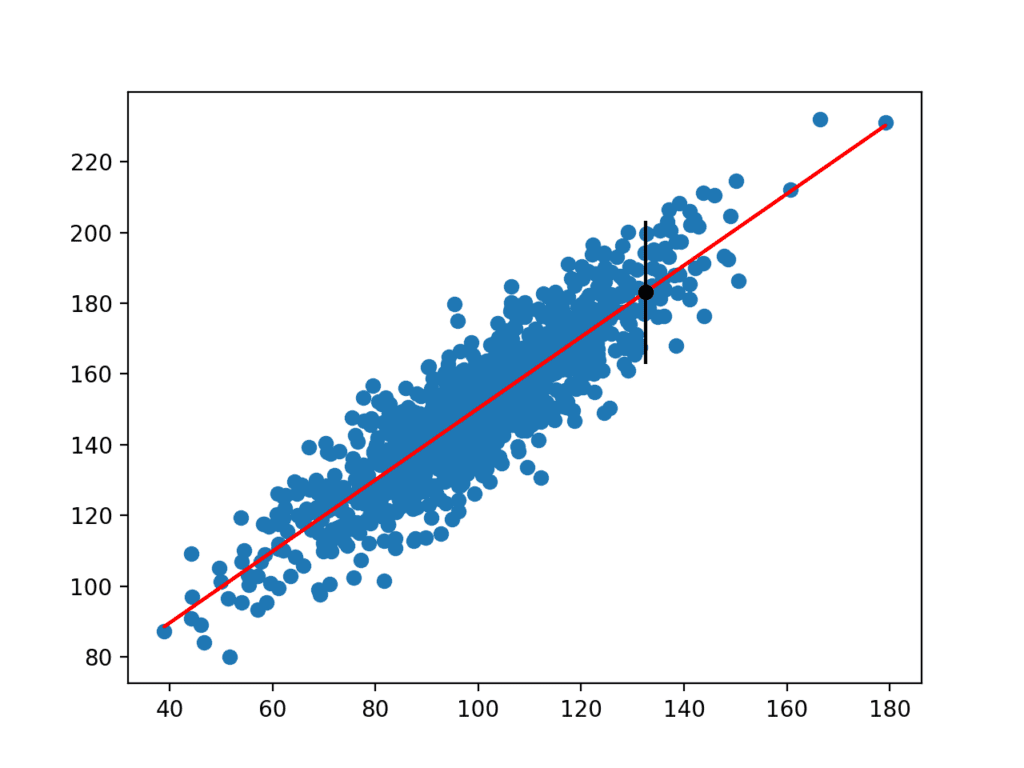
10111213141516171819202122232425262728293031323334353637# linear regression prediction with prediction intervalfrom numpy.random import randnfrom numpy.random import seedfrom numpy import powerfrom numpy import sqrtfrom numpy import meanfrom numpy import stdfrom numpy import sum as arraysumfrom scipy.statistikk importere linregressfra matplotlib importere pyplot# frø tilfeldig tall generatorfrø(1)# forberede dataenex = 20 * randn(1000) + 100y = x + (10 * randn(1000) + 50)# tilpass den ikke-lineære regresjonsmodellenb1, b0, r_value, p_value, std_err = linregress(x, y)# merk spådommeryhat = b0 + b1 * x# definer ny inngang, forventet verdi og prediksjonx_in = xy_out = yyhat_out = yhat# estimat stdev av yhatsum_errs = arraysum ((y – yhat) * * 2)stdev = sqrt(1 / (len(y)-2) * sum_errs)# beregn prediksjon intervallintervall = 1,96 * stdevskriv ut (‘Prediksjon Intervall:%.3f ‘ % intervall)nedre, øvre = yhat_out – intervall, yhat_out + intervallskriv ut (‘95% % sannsynlighet for at den sanne verdien er mellom %.3f og %.3f ‘ % (nedre, øvre))skriv ut (‘sann verdi:%.3f ‘ % y_out)# plott datasett og prediksjon med intervallpyplot.scatter (x, y)pyplot.plott (x, yhat, farge = ‘rød’)pyplot.errorbar (x_in, yhat_out, yerr=intervall, farge=’ svart’, fmt = ‘o’)pyplot.show()Kjører eksemplet estimerer yhat-standardavviket og beregner deretter prediksjonsintervallet.
når det er beregnet, presenteres prediksjonsintervallet for brukeren for den gitte inngangsvariabelen. Fordi vi konstruerte dette eksemplet, vet vi det sanne resultatet, som vi også viser. Vi kan se at i dette tilfellet dekker 95% prediksjonsintervallet den sanne forventede verdien.
123Prediction Interval: 20.20495% likelihood that the true value is between 160.750 and 201.159True value: 183.124det Opprettes også et plott som viser det rå datasettet som et spredningsplott, prognosene for datasettet som en rød linje, og prediksjons-og prediksjonsintervallet som henholdsvis en svart prikk og linje.
Utvidelser
denne delen viser noen ideer for å utvide opplæringen som du kanskje ønsker å utforske.
- Oppsummerer forskjellen mellom toleranse, tillit og prediksjonsintervaller.
- Utvikle en lineær regresjonsmodell for et standard maskinlæringsdatasett og beregne prediksjonsintervaller for et lite testsett.
- Beskriv i detalj hvordan en ikke-lineær prediksjonsintervallmetode fungerer.
hvis du utforsker noen av disse utvidelsene, vil jeg gjerne vite.
Videre Lesing
denne delen gir flere ressurser om emnet hvis du ønsker å gå dypere.
Innlegg
- Hvordan Rapportere Klassifikatorytelse med Konfidensintervaller
- Hvordan Beregne Bootstrap Konfidensintervaller For Maskinlæringsresultater I Python
- Forstå Tidsserieprognoseusikkerhet Ved Hjelp Av Konfidensintervaller med Python
- Anslå Antall Eksperimenter Som Gjentas For Stokastiske Maskinlæringsalgoritmer
Bøker
- Forstå Den Nye Statistikken: Effektstørrelser, Konfidensintervaller og Meta-Analyse, 2017.
- Statistiske Intervaller: En Veiledning for Utøvere og Forskere, 2017.
- En Introduksjon Til Statistisk Læring: Med Applikasjoner I R, 2013.
- Introduksjon til Den Nye Statistikken: Estimering, Åpen Vitenskap og Utover, 2016.
- Prognoser: prinsipper og praksis, 2013.
Papers
- en sammenligning av noen feilestimater for nevrale nettverksmodeller, 1995.
- Maskinlæring tilnærminger for estimering av prediksjon intervall for modellen utgang, 2006.En Omfattende Gjennomgang Av Nevrale Nettverksbaserte Prediksjonsintervaller og Nye Fremskritt, 2010.
API
- scipy.statistikk.linregress () API
- matplotlib.pyplot.scatter () API
- matplotlib.pyplot.Errorbar() API
Artikler
- Prediksjonsintervall På Wikipedia
- Bootstrap prediksjonsintervall På Kryss Validert
Sammendrag
i denne opplæringen oppdaget du prediksjonsintervallet og hvordan du beregner det for en enkel lineær regresjonsmodell.
spesielt lærte du:
- At et prediksjonsintervall kvantifiserer usikkerheten til en enkeltpunktsprognose.
- at prediksjonsintervaller kan estimeres analytisk for enkle modeller, men er mer utfordrende for ikke-lineære maskinlæringsmodeller.
- hvordan beregne prediksjonsintervallet for en enkel lineær regresjonsmodell.
har du noen spørsmål?
Still dine spørsmål i kommentarfeltet nedenfor, og jeg vil gjøre mitt beste for å svare.Få Et Håndtak På Statistikk For Maskinlæring!

Utvikle en fungerende forståelse av statistikk
…Ved å skrive linjer med kode I python
Oppdag hvordan I min nye Ebok: Statistiske Metoder for Maskinlæring
Det gir selvstudium tutorials på emner som: Hypotese Tester, Korrelasjon, Nonparametric Statistikk, Resampling, og mye mer…
Oppdag Hvordan Du Forvandler Data til Kunnskap
Hopp Over Akademikerne. Bare Resultater.
Se Hva Som Er Inni
Tweet Share Share