VMware Høy Tilgjengelighet (HA) er et verktøy som eliminerer behovet for dedikert standby-maskinvare og-programvare i et virtualisert miljø. VMware HA brukes ofte til å forbedre påliteligheten, redusere nedetid i virtuelle miljøer og forbedre katastrofegjenoppretting/forretningskontinuitet.dette kapittelet utdrag FRA VCP4 Eksamen Cram: VMware Certified Professional, 2nd Edition Av Elias Khnaser utforsker VMware HA beste praksis.
VMware High Availability handler primært om ESX / ESXi-vertsfeil og hva som skjer med de virtuelle maskinene (Vm-ene) som kjører på denne verten. HA kan også overvåke og starte EN VM ved å sjekke om VMware-Verktøyene fortsatt kjører. Når EN ESX / ESXi-vert mislykkes av en eller annen grunn, mislykkes alle de løpende Vm-ene også. VMware HA sikrer At Vm-ene fra den mislykkede verten kan startes på nytt på andre ESX / ESXi-verter.
Mange forveksler feilaktig VMware HA med feiltoleranse. VMware HA er ikke feiltolerant ved at Hvis en vert mislykkes, mislykkes Vm-ene på den også. HA handler bare om å starte Disse Vm-ene på andre ESX/ESXi-verter med nok ressurser. Feiltoleranse gir derimot avbruddsfri tilgang til ressurser i tilfelle vertsfeil.
 Klikk på bokomslaget bildet over
Klikk på bokomslaget bildet over å laste Ned Elias Khnaser hele kapittel
på backup og høy tilgjengelighet .VMware HA opprettholder en kommunikasjonskanal med alle DE ANDRE ESX / ESXi-vertene som er medlemmer av samme klynge ved å bruke et hjerteslag som det sender ut hvert 1. sekund i vSphere 4.0 eller hvert 10. sekund i vsphere 4.1 som standard. NÅR EN ESX-server savner et hjerteslag, venter de andre vertene 15 sekunder for at den andre verten skal svare igjen. Etter 15 sekunder starter klyngen omstart Av Vm – ene på den sviktende esx/ESXi-verten på de gjenværende ESX / ESXi-vertene i klyngen. VMware HA overvåker også kontinuerlig esx / ESXi-vertene som er medlemmer av klyngen, og sikrer at ressurser alltid er tilgjengelige for å tilfredsstille krav i tilfelle vertsfeil.
Overvåking Av Virtuell Maskinfeil
Overvåking Av Virtuell Maskinfeil er teknologi som er deaktivert som standard. Funksjonen er å overvåke virtuelle maskiner, som den spør hvert 20. sekund via et hjerteslag. Det gjør dette ved Å bruke Vmware-Verktøyene som er installert inne I VM. Når EN VM savner et hjerteslag, Anser VMware HA DENNE VM som mislyktes og forsøker å tilbakestille den. Tenk På Virtuell Maskinfeilovervåking som En Slags Høy Tilgjengelighet for Vm-er.
Overvåking Av Virtuell Maskinfeil kan oppdage om en virtuell maskin ble slått av manuelt, suspendert eller migrert, og forsøker dermed ikke å starte den på nytt.
vmware HA konfigurasjon forutsetninger
HA krever følgende konfigurasjon forutsetninger før det kan fungere skikkelig:
- vCenter: Fordi VMware HA er en enterprise-klasse funksjon, krever det vCenter før det kan aktiveres.DNS-oppløsning: ALLE esx / ESXi-verter som er medlemmer AV HA-klyngen, må kunne løse hverandre ved HJELP AV DNS.
- Tilgang til delt lagring: alle verter i HA-klyngen må ha tilgang og synlighet til samme delte lagring; ellers ville de ikke ha tilgang til Vm-Ene.
- Tilgang til samme nettverk: ALLE esx / ESXi-verter må ha samme nettverk konfigurert på alle verter, slik at NÅR EN VM startes på en vert, har den igjen tilgang til riktig nettverk.
Redundans For Tjenestekonsoll
Anbefalt praksis tilsier At Tjenestekonsollen (SC) har redundans. VMware HA klager og utsteder en advarsel hvis den oppdager At Servicekonsollen er konfigurert på en vSwitch med bare en vmnic. Som Figur 1 viser, kan Du konfigurere Service Console redundans på en av to måter:
- Opprett to Service Console port grupper, hver på en annen vSwitch.
- Tilordne to fysiske nettverkskort (Nic) i form AV ET nic-team til Tjenestekonsollen vSwitch.
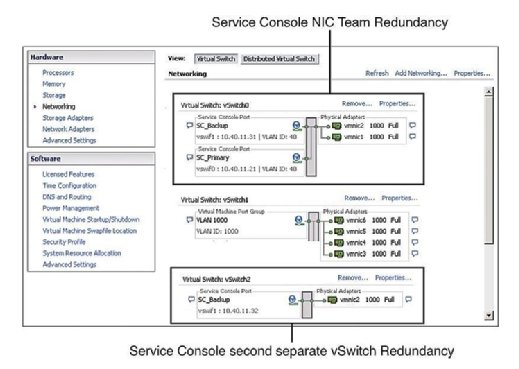
i begge tilfeller må du konfigurere HELE IP-stakken MED IP-adresse, delnett og gateway. Tjenesten Konsollen vSwitches brukes for hjerteslag og staten synkronisering og bruke følgende porter:
- Innkommende TCP-port 8042
- Innkommende UDP-port 8045
- Utgående TCP-port 2050
- Utgående UDP-port 2250
- Innkommende TCP-port 8042-8045
- Utgående TCP-port 2050-2250
- utgående udp-port 2050-2250
HVIS du IKKE KONFIGURERER sc-redundans, får du en advarsel når du aktiverer ha. Så, for å unngå å se denne feilmeldingen og å overholde beste praksis, konfigurer SC til å være overflødig.
host failover capacity planning
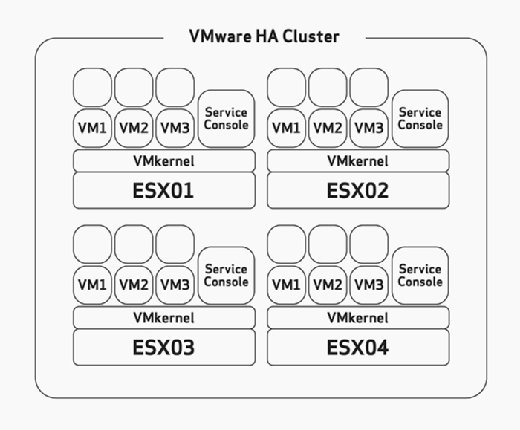
når du konfigurerer HA, må du manuelt konfigurere maksimal vert feiltoleranse. Dette er en oppgave som du bør nøye vurdere under maskinvarestørrelsen og planleggingsfasen av distribusjonen. Dette vil anta at DU har bygget DINE ESX / ESXi-verter med nok ressurser til å kjøre Flere Vm-Er enn planlagt for Å kunne imøtekomme HA. I Figur 2 kan du for Eksempel se AT HA-klyngen har fire ESX-verter, og at alle fire av disse vertene har nok kapasitet til å kjøre minst tre Vm-Er til. Fordi de allerede kjører tre Vm-Er, betyr det at denne klyngen har råd til tap av to ESX / ESXi-verter fordi de resterende TO ESX / ESXi-vertene kan slå på de seks mislykkede Vm-ene uten problem hvis det oppstår feil.
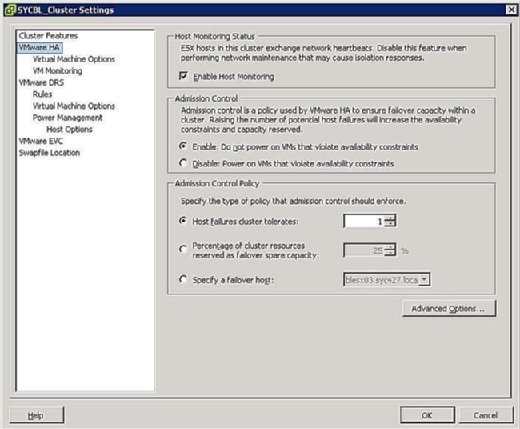
under konfigurasjonsfasen AV HA-klyngen blir du presentert med en skjerm som ligner den som vises i Figur 3 som ber deg om å definere to clusterwide konfigurasjoner som følger:
- Vertsovervåkingsstatus:
- Aktiver Vertsovervåking: denne innstillingen lar deg kontrollere om HA-klyngen skal overvåke vertene for et hjerteslag. Dette er klyngens måte å avgjøre om en vert fortsatt er aktiv. I noen tilfeller, når du kjører vedlikeholdsoppgaver PÅ ESX / ESXi-verter, kan det være ønskelig å deaktivere dette alternativet for å unngå å isolere en vert.
- Adgangskontroll:
- Aktiver: ikke slå På Vm som bryter tilgjengelighet begrensninger: Hvis du velger dette alternativet, angir du at hvis ingen ressurser er tilgjengelige for å tilfredsstille EN VM, bør DEN ikke være slått på.
- Deaktiver: Slå På Virtuelle Maskiner som bryter med tilgjengelighetsbegrensninger: Hvis du Velger dette alternativet, må du slå på EN VM selv om du må overcommit ressurser.
- Adgangskontrollpolicy:
- Vertsfeil klynge tolererer: denne innstillingen lar deg konfigurere hvor mange vertsfeil du vil tolerere. De tillatte innstillingene er 1 til 4.
- Prosentandel av klyngeressurser reservert som failover reservekapasitet: Hvis du velger dette alternativet, reserverer du en prosentandel av de totale klyngeressursene i reserve for failover. I en klynge med fire verter angir en 25% reservasjon at du setter til side en full vert for failover. Hvis du vil sette til side færre, kan du velge 10% av klyngeressursene i stedet.
- Angi en failover-vert: Hvis du Velger dette alternativet, angir du at du velger en bestemt vert som failover-vert i klyngen. Dette kan være tilfelle hvis du har en ledig vert eller har en bestemt vert som har betydelig mer beregne og minne ressurser tilgjengelig.
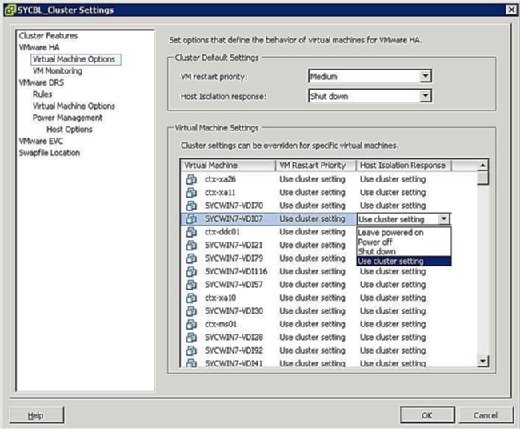
- La Være Slått På: som etiketten antyder, betyr denne innstillingen at VM forblir slått på ved vertsisolasjon.
- Slå AV: denne innstillingen definerer AT VM er slått av i tilfelle isolasjon. Dette er en hard strøm av.
- Shut down: denne innstillingen definerer AT I tilfelle en isolasjon, BLIR VM slått av grasiøst ved Hjelp Av VMware Tools. Hvis denne oppgaven ikke er fullført innen fem minutter, utføres en strøm av umiddelbart. Hvis VMware Tools ikke er installert, utføres en strøm av i stedet.
- Bruk Cluster Setting: denne innstillingen videresender oppgaven til clusterwide-innstillingen som er definert i vinduet vist tidligere i Figur 4.
- Høy: Vm-Er med høy prioritet startes på nytt først.
- Medium: dette er standardinnstillingen.
- Lav: Vm-Er med lav prioritet startes på nytt sist.
- Bruk Klyngeinnstilling: Vm-er startes på nytt basert på innstillingen som er definert på klyngenivå definert i vinduet vist i figuren nedenfor.
- Deaktivert: VM slår seg ikke på.
- Cluster-in-a-box: i dette scenariet ligger Alle Vm-ene som er en del av klyngen, på SAMME ESX/ESXi-vert. Som du kanskje har gjettet, skaper dette umiddelbart et enkelt feilpunkt: ESX / ESXi-verten. Når det gjelder delt lagring, kan du bruke virtuelle disker som delt lagring i dette scenariet, eller Du kan bruke RAW Device Mapping (RDM) i virtuell kompatibilitetsmodus.Cluster-across-boxes: i dette scenariet ligger klyngenodene (Vm-er som er medlemmer av klyngen) på FLERE esx / ESXi-verter, der hver av nodene som utgjør klyngen, kan få tilgang til samme lagring, slik at hvis EN VM mislykkes, kan den andre fortsette å fungere og få tilgang til de samme dataene. Dette scenariet skaper et ideelt klyngemiljø ved å eliminere et enkelt feilpunkt. Delt lagring er en forutsetning i dette og må ligge På Fibre Channel SAN. DU må også bruke EN RDM I Fysisk Eller Virtuell Kompatibilitetsmodus, da virtuelle disker ikke er en støttet konfigurasjon for delt lagring. Der hver av nodene som utgjør klyngen, kan få tilgang til samme lagring, slik at hvis en VM mislykkes, kan den andre fortsette å fungere og få tilgang til de samme dataene.
- fysisk-til-virtuell klynge: I dette scenariet er ett medlem av klyngen en virtuell maskin, mens det andre medlemmet er en fysisk maskin. Delt lagring er en forutsetning i dette scenariet og må konfigureres SOM EN RDM I Fysisk Kompatibilitetsmodus.
- Virtuelle disker: Du kan bare bruke en virtuell disk som et delt lagringsområde hvis du gjør clustering i en boks-med andre ord, bare hvis begge Vm-ene ligger på SAMME ESX / ESXi-vert.RDM I Fysisk Kompatibilitetsmodus: DENNE modusen lar deg koble en fysisk LUN direkte til EN VM eller fysisk maskin. Denne modusen forhindrer deg i å bruke funksjonalitet som øyeblikksbilder, og brukes ideelt når ett medlem av klyngen er en fysisk maskin mens den andre er EN VM.RDM I Virtuell Kompatibilitetsmodus: denne modusen lar deg koble en fysisk LUN direkte til EN VM eller fysisk maskin. Denne modusen gir deg alle fordelene med virtuelle disker som kjører PÅ VMFS, inkludert øyeblikksbilder og avansert fillåsing. Disken er tilgjengelig via hypervisoren og er ideell når du konfigurerer et cluster-across-box scenario der du må gi Begge Vm-ene tilgang til delt lagring.
Vertsisolasjon
et nettverksfenomen kjent som en delt hjerne oppstår når esx / ESXi-verten har sluttet å motta hjerteslag fra resten av klyngen. Hjerteslaget spørres for hvert sekund i vSphere 4.0 eller 10 sekunder i vSphere 4.1. Hvis et svar ikke mottas, klyngen mener esx / ESXi verten har mislyktes. NÅR DETTE skjer, HAR esx/ESXi-verten mistet nettverkstilkoblingen på styringsgrensesnittet. Verten kan fortsatt være oppe og går, Og Vm-Ene kan ikke engang bli påvirket med tanke på at de kanskje bruker et annet nettverksgrensesnitt som ikke er påvirket. VSphere må imidlertid handle når dette skjer fordi det mener at en vert har mislyktes. For den saks skyld ble vertsisolasjonsresponsen opprettet. Host isolation response er HAS måte å håndtere EN ESX / ESXi-vert som har mistet nettverksforbindelsen.
du kan kontrollere hva som skjer Med Vm-Er i tilfelle en vertsisolasjon. For Å komme TIL VM Isolation Response-skjermen, høyreklikk den aktuelle klyngen og klikk På Rediger Innstillinger. Du kan deretter klikke Alternativer For Virtuell Maskin under vmware HA-banneret i venstre rute. Du kan kontrollere alternativer clusterwide ved å angi alternativet host isolation response tilsvarende. Dette brukes på Alle Vm-Ene på den berørte verten. Når det er sagt, kan du alltid overstyre klyngeinnstillingene ved å definere et annet svar på VM-nivå.
som vist i Figur 4, Er Isoleringsresponsalternativene dine som følger:
i tilfelle isolasjon betyr dette ikke nødvendigvis at verten er nede. Fordi Vm-ene kan være konfigurert med forskjellige fysiske Nic-Er og koblet til forskjellige nettverk, kan De fortsette å fungere som de skal; du må derfor vurdere dette når du angir prioritet for isolasjon. Når en vert er isolert, betyr dette ganske enkelt at Tjenestekonsollen ikke kan kommunisere med resten AV ESX / ESXi-vertene i klyngen.
Virtual machine recovery priority
SKULLE HA-klyngen din ikke kunne imøtekomme alle Vm-ene i tilfelle feil, har du muligheten til å prioritere På Vm-Er. Prioriteringene dikterer hvilke Vm-er som startes på nytt først, og hvilke Vm-Er som ikke er så viktige i nødstilfeller. Disse alternativene er konfigurert på samme skjerm som Isoleringsresponsen som er dekket i forrige del. Du kan konfigurere clusterwide-innstillinger som skal brukes på Alle Vm-Er på den berørte verten, eller du kan overstyre klyngeinnstillingene ved å konfigurere en overstyring på VM-nivå.
Du kan angi EN VM-omstartsprioritet til ett av følgende:
prioriteten bør settes basert på Betydningen Av Vm-ene. Med andre ord vil du kanskje starte domenekontrollere på nytt og ikke starte utskriftsservere på nytt. De høyere prioriterte virtuelle maskinene startes på nytt først. Vm-er som kan tolerere gjenværende slått av i nødstilfeller, bør konfigureres til å forbli slått av for å spare ressurser.
mscs clustering
hovedformålet med en klynge er å sikre at kritiske systemer forblir online til enhver pris og til enhver tid. På samme måte som fysiske maskiner som kan grupperes, kan virtuelle maskiner også grupperes MED ESX ved hjelp av tre forskjellige scenarier:
Når du designer en klyngeløsning, må du løse problemet med delt lagring, noe som vil tillate flere verter eller Vm-er tilgang til de samme dataene. vSphere tilbyr flere metoder som du kan klargjøre delt lagring som følger:
Den eneste vmware-støttede clustering-tjenesten er Microsoft Clustering Services (MSCS). Du kan konsultere vmware white paper » Oppsett For Failover Clustering Og Microsoft Cluster Service.»
VMware Feiltoleranse
VMWARE Feiltoleranse (FT) er en annen FORM FOR VM clustering utviklet av VMware for systemer som krever ekstrem oppetid. EN av DE mest overbevisende funksjonene I FT er enkel oppsett. FT er bare en avkrysningsboks som kan aktiveres. SAMMENLIGNET med tradisjonell clustering som krever spesifikke konfigurasjoner og i noen tilfeller kabling, ER FT enkel, men kraftig.
hvordan fungerer det?
når du beskytter Vm med FT, opprettes en sekundær VM i lockstep av den beskyttede VM, den første VM. FT fungerer ved samtidig å skrive til den første VM og den andre VM samtidig. Hver oppgave er skrevet to ganger. Hvis Du klikker På Start-menyen på den første VM, Vil Start-menyen på den andre VM også bli klikket. KRAFTEN TIL FT er dens evne til å holde Begge Vm-ene synkronisert.
hvis den beskyttede VM skal gå ned av en eller annen grunn, tar den sekundære VM umiddelbart sin plass, griper sin identitet OG IP-adresse, fortsetter å betjene brukere uten avbrudd. Den nyopprettede beskyttede VM oppretter da en sekundær for seg selv på en annen vert, og syklusen starter på nytt.
for å klargjøre, la oss se et eksempel. Hvis du vil beskytte En Exchange-server, kan DU aktivere FT. HVIS ESX/ESXi-verten som bærer den beskyttede VM, av en eller annen grunn mislykkes, slår den sekundære VM inn og påtar seg sine plikter uten avbrudd i tjenesten.
tabellen nedenfor skisserer De Ulike Høy Tilgjengelighet og clustering teknologier som du har tilgang til med vSphere og fremhever begrensninger av hver.

Feiltoleransekrav
Feiltoleranse er ikke forskjellig fra noen annen virksomhet funksjon i at det krever visse forutsetninger for å være oppfylt før teknologien kan fungere skikkelig og effektivt. Disse kravene er beskrevet i følgende liste og brutt ned i de ulike kategoriene som krever spesifikke minimumskrav:
- Vertskrav:
- FT-kompatibel CPU. Se denne VMWARE KB-artikkelen for mer informasjon.
- Maskinvarevirtualisering må være aktivert i bios.
- Vertsens CPU – klokkehastigheter må være innenfor 400 MHz av hverandre.
- VM-krav:
- Vm-er må ligge på støttet delt lagring(FC, iSCSI og NFS).
- Vm-Er må kjøre et STØTTET OS.
- VMs må lagres i enten EN VMDK eller en virtuell RDM.
- Vm-Er kan ikke ha tynt klargjort VMDK og må bruke En Eagerzeroedthick virtuell disk.
- Vm-Er kan ikke ha mer enn en vCPU konfigurert.
- Cluster krav:
- ALLE esx / ESXi verter må være samme versjon og samme patch nivå.
- ALLE esx / ESXi-verter må ha tilgang TIL VM-datalagre og nettverk.
- VMware HA må være aktivert på klyngen.
- hver vert må ha en vMotion Og FT Logging NIC konfigurert.
- Kontroll Av Vertssertifikat må også være aktivert.
det anbefales sterkt at du i tillegg til å sjekke prosessorkompatibilitet med FT, sjekker serverens merke og modellkompatibilitet med FT mot VMWARE Hardware Compatibility List (HCL).MENS FT er en flott clustering løsning, er det viktig å merke seg at det også har visse begrensninger. FT VMs kan for eksempel ikke snapshotted, og De Kan Ikke Være Lagring vMotioned. Faktisk vil Disse Vm-Ene automatisk bli flagget DRS-Deaktivert og vil ikke delta i noen dynamisk ressursbelastningsbalansering.
slik aktiverer DU FT
Aktivering AV FT er ikke vanskelig, men det innebærer å konfigurere noen forskjellige innstillinger. FØLGENDE innstillinger må være riktig konfigurert FOR AT FT skal fungere:
- Aktiver Kontroll Av Vertssertifikat: For å aktivere denne innstillingen, logg på din vCenter server og klikk På Administrasjon Fra Fil-menyen og klikk på Vcenter Server Settings. I den venstre ruten klikker DU SSL-Innstillinger og merker av for vcenter Krever Verified Host SSL-Sertifikater.
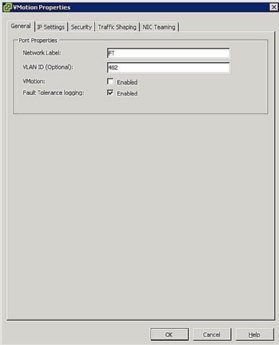
Figur 5. FT-portgruppeinnstillinger - Konfigurer Vertsnettverk: Nettverkskonfigurasjonen FOR FT er enkel og følger de samme trinnene og prosedyrene som vMotion, bortsett fra i stedet for å sjekke vmotion-boksen, sjekk Feiltoleranseloggingsboksen som vist i Figur 5.
- SLÅ FT på Og Av: Når du har oppfylt de foregående kravene, kan du nå slå FT på og av For Vm-Er. Denne prosessen er også grei: Finn VM du vil beskytte, høyreklikk den og velg Feiltoleranse>Slå På Feiltoleranse.MENS FT er en første generasjons klyngeteknologi, fungerer DEN imponerende godt og forenkler overkompliserte tradisjonelle metoder for å bygge, konfigurere og vedlikeholde klynger. FT er en imponerende teknologi for en oppetid ståsted og fra en sømløs failover ståsted.