funkcje aktywacyjne są najważniejszą częścią każdej sieci neuronowej w deep learning. W uczeniu głębokim bardzo skomplikowanymi zadaniami są klasyfikacja obrazów, transformacja języka, wykrywanie obiektów itp., które są potrzebne do rozwiązania za pomocą sieci neuronowych i funkcji aktywacji. Tak więc bez niego zadania te są niezwykle złożone w obsłudze.
W skrócie, sieć neuronowa jest bardzo silną techniką uczenia maszynowego, która zasadniczo naśladuje to, jak mózg rozumie, w jaki sposób? Mózg odbiera bodźce, jako wkład, ze środowiska, przetwarza je, a następnie odpowiednio wytwarza dane wyjściowe.
wprowadzenie
funkcje aktywacji sieci neuronowej są ogólnie najważniejszym elementem uczenia głębokiego, są zasadniczo wykorzystywane do określania wyników modeli uczenia głębokiego, jego dokładności i wydajności modelu treningowego, który może zaprojektować lub podzielić ogromną sieć neuronową.
funkcje aktywacyjne pozostawiły znaczny wpływ na zdolność sieci neuronowych do konwergencji i szybkości konwergencji, nie chcesz jak? Kontynuujmy wprowadzenie do funkcji aktywacji, rodzaje funkcji aktywacji & ich znaczenie i ograniczenia za pośrednictwem tego bloga.
co to jest funkcja aktywacji?
funkcja aktywacji definiuje wyjście wejścia lub zestawu wejść lub w innych terminach definiuje węzeł wyjścia węzła, który jest podany w wejściach. Zasadniczo decydują się dezaktywować neurony lub aktywować je, aby uzyskać pożądany wynik. Wykonuje również nieliniową transformację na wejściu, aby uzyskać lepsze wyniki na złożonej sieci neuronowej.
funkcja aktywacji pomaga również normalizować wyjście dowolnego wejścia w zakresie od 1 do -1. Funkcja aktywacji musi być wydajna i powinna skrócić czas obliczeń, ponieważ sieć neuronowa czasami szkoli się na milionach punktów danych.
funkcja aktywacji w zasadzie decyduje w każdej sieci neuronowej, że dane wejściowe lub odbierane informacje są istotne lub nieistotne. Weźmy przykład, aby lepiej zrozumieć, czym jest neuron i jak funkcja aktywacji ogranicza wartość wyjściową do pewnego limitu.
neuron jest w zasadzie średnią ważoną danych wejściowych, następnie ta suma jest przekazywana przez funkcję aktywacji, aby uzyskać dane wyjściowe.
Y = ∑ (wagi*wejście + bias)
tutaj Y może być wszystkim dla neuronu między zakresem-nieskończoność do +nieskończoność. Musimy więc powiązać nasze wyniki, aby uzyskać pożądane przewidywania lub uogólnione wyniki.
y = funkcja aktywacji (weights (wagi*wejście + bias))
przekazujemy ten neuron do funkcji aktywacji do powiązanych wartości wyjściowych.
po co nam funkcje aktywacyjne?
bez funkcji aktywacji, waga i bias miałyby tylko przekształcenie liniowe, lub sieć neuronowa jest tylko modelem regresji liniowej, równanie liniowe jest wielomianem tylko jednego stopnia, który jest prosty do rozwiązania, ale ograniczony pod względem zdolności do rozwiązywania złożonych problemów lub wielomianów wyższego stopnia.
ale w przeciwieństwie do tego, dodanie funkcji aktywacji do sieci neuronowej powoduje nieliniową transformację do wejścia i czyni ją zdolną do rozwiązywania złożonych problemów, takich jak Tłumaczenia języka i klasyfikacje obrazów.
oprócz tego, funkcje aktywacyjne są zróżnicowane, dzięki czemu mogą łatwo implementować propagacje zwrotne, zoptymalizowaną strategię podczas wykonywania backpropagacji w celu pomiaru funkcji utraty gradientu w sieciach neuronowych.
rodzaje funkcji aktywacyjnych
poniżej podano najbardziej znane funkcje aktywacyjne,
-
krok binarny
-
liniowy
-
ReLU
-
LeakyReLU
-
Sigmoid
-
Tanh
-
SoftMax
1. Funkcja aktywacji kroku binarnego
Ta funkcja aktywacji jest bardzo podstawowa i przychodzi do głowy za każdym razem, gdy próbujemy powiązać wyjście. Zasadniczo jest to klasyfikator bazy progowej, w tym decydujemy o wartości progowej, aby zdecydować, że neuron powinien zostać aktywowany lub dezaktywowany.
f(x) = 1 if x > 0 else 0 if X < 0
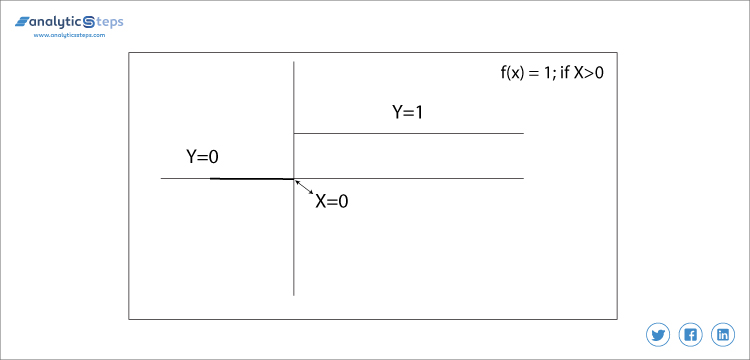
funkcja kroku binarnego
w tym przypadku ustalamy wartość progową na 0. Bardzo proste i użyteczne jest klasyfikowanie problemów binarnych lub klasyfikatora.
2. Funkcja aktywacji liniowej
jest to prosta funkcja aktywacji liniowej, w której nasza funkcja jest wprost proporcjonalna do ważonej sumy neuronów lub danych wejściowych. Funkcje aktywacji liniowej są lepsze w dawaniu szerokiego zakresu aktywacji, a linia o dodatnim nachyleniu może zwiększać szybkość odpalania wraz ze wzrostem szybkości wejściowej.
w trybie binarnym, albo neuron odpala, albo nie. Jeśli znasz nachylenie gradientowe w uczeniu głębokim, zauważysz, że w tej funkcji pochodna jest stała.
Y = mZ
gdzie pochodna względem Z jest stała m. gradient znaczeniowy jest również stały i nie ma nic wspólnego z Z. w tym przypadku, jeśli zmiany wprowadzone w backpropagacji będą stałe i nie będą zależne od Z, więc nie będzie to dobre do nauki.
w tym, nasza druga warstwa jest wyjściem funkcji liniowej poprzednich warstw wejściowych. Chwileczkę, czego się w tym nauczyliśmy, że jeśli porównamy nasze wszystkie warstwy i usuniemy wszystkie warstwy z wyjątkiem pierwszej i ostatniej, to również możemy uzyskać tylko wynik, który jest funkcją liniową pierwszej warstwy.
3. Funkcja aktywacji Relu (Rectified Linear unit)
rektyfikowana jednostka liniowa lub ReLU jest obecnie najczęściej używaną funkcją aktywacji, która waha się od 0 do nieskończoności, wszystkie ujemne wartości są konwertowane na zero, a ten współczynnik konwersji jest tak szybki, że ani nie może mapować, ani pasować do danych poprawnie, co stwarza problem, ale tam, gdzie istnieje problem, istnieje rozwiązanie.
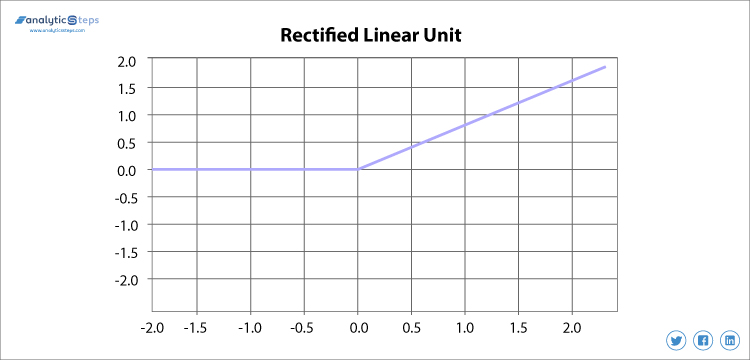
funkcja prostowania jednostek liniowych
używamy funkcji nieszczelnego ReLU zamiast ReLU, aby uniknąć tego braku, w nieszczelnym zakresie ReLU jest rozszerzony, co zwiększa wydajność.
funkcja aktywacji nieszczelnego ReLU
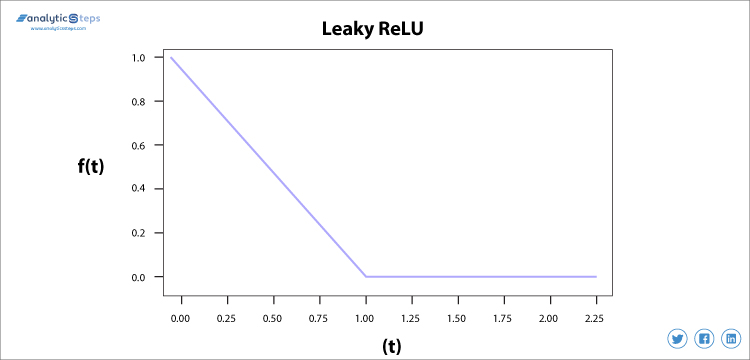
funkcja nieszczelnej aktywacji ReLU
potrzebowaliśmy funkcji nieszczelnej aktywacji ReLU, aby rozwiązać problem „umierającego ReLU”, jak omówiono w ReLU, obserwujemy, że wszystkie ujemne wartości wejściowe bardzo szybko zamieniają się w zero i w przypadku nieszczelnego ReLU nie ustawiamy wszystkich ujemnych wejść na zero, ale na wartość bliską zeru, która rozwiązuje główny problem funkcji aktywacji ReLU.
funkcja aktywacji esicy
funkcja aktywacji esicy jest używana głównie, ponieważ wykonuje swoje zadanie z dużą wydajnością, zasadniczo jest to probabilistyczne podejście do podejmowania decyzji i waha się między 0 a 1, więc kiedy musimy podjąć decyzję lub przewidzieć wyjście, używamy tej funkcji aktywacji ze względu na zakres jest minimalny, dlatego przewidywanie byłoby dokładniejsze.
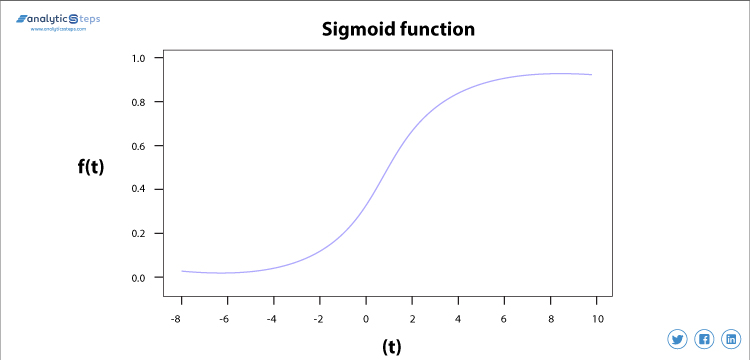
funkcja aktywacji esicy
równanie dla funkcji esicy to
f(x) = 1/(1+e(-x) )
funkcja esicy powoduje problem zwany głównie znikającym problemem gradientu, który występuje, ponieważ konwertujemy Duże dane wejściowe między zakresem od 0 do 1, a zatem ich pochodne stają się znacznie mniejsze, co nie daje zadowalającego wyniku. Do rozwiązania tego problemu używana jest inna funkcja aktywacyjna, np. ReLU, gdzie nie mamy małego problemu pochodnego.
funkcja aktywacji stycznej hiperbolicznej(Tanh)
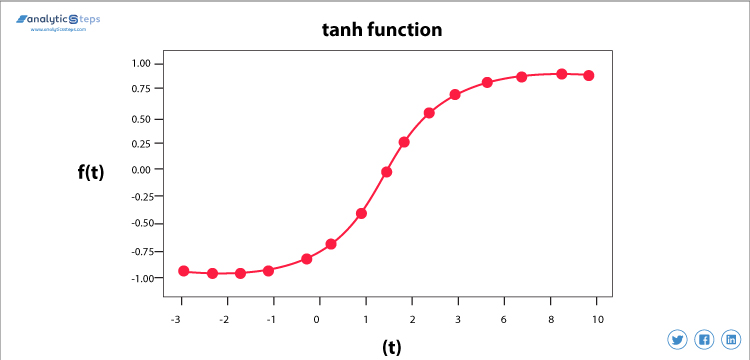
funkcja aktywacji Tanh
Ta funkcja aktywacji jest nieco lepsza niż funkcja esicy, podobnie jak funkcja esicy jest również używana do przewidywania lub rozróżniania dwóch klas, ale mapuje ujemne dane wejściowe tylko na ilość ujemną i waha się od -1 do 1.
funkcja aktywacji Softmax
Softmax jest używany głównie na ostatniej warstwie i.e warstwa wyjściowa do podejmowania decyzji tak samo jak działa aktywacja esicy, softmax zasadniczo daje wartość zmiennej wejściowej w zależności od ich wagi, a suma tych wag jest ostatecznie jedna.
Softmax o klasyfikacji binarnej
do klasyfikacji binarnej zarówno esica, jak i softmax są równie przystępne, ale w przypadku problemu z klasyfikacją wieloklasową zwykle używamy softmax i entropii krzyżowej wraz z nią.
wniosek
funkcje aktywacyjne to te istotne funkcje, które wykonują nieliniową transformację do wejścia i sprawiają, że jest biegły w zrozumieniu i wykonuje bardziej złożone zadania. Omówiliśmy 7 najczęściej używanych funkcji aktywacyjnych z ich ograniczeniem (jeśli istnieje), te funkcje aktywacyjne są używane do tego samego celu, ale w różnych warunkach.