Witaj w Ilustrowanym Przewodniku po długiej pamięci krótkotrwałej (LSTM) i Gated recurrent unit (gru). Jestem Michael i jestem inżynierem Uczenia Maszynowego w obszarze asystenta głosowego AI.
w tym poście zaczniemy od intuicji stojącej za LSTM i GRU. następnie wyjaśnię wewnętrzne mechanizmy, które pozwalają LSTM i GRU tak dobrze działać. Jeśli chcesz zrozumieć, co dzieje się pod maską tych dwóch sieci, to ten post jest dla ciebie.
Możesz również obejrzeć wersję wideo tego postu na youtube, jeśli wolisz.
Jeśli sekwencja jest wystarczająco długa, będą mieli trudności z przenoszeniem informacji z wcześniejszych kroków czasowych do późniejszych. Więc jeśli próbujesz przetworzyć akapit tekstu do przewidywania, RNN może pominąć ważne informacje od początku.
podczas propagacji pleców nawracające sieci neuronowe cierpią na problem zanikającego gradientu. Gradienty są wartościami używanymi do aktualizacji wag sieci neuronowych. Problem znikającego gradientu polega na tym, że gradient kurczy się, gdy z powrotem propaguje się w czasie. Jeśli wartość gradientu staje się bardzo mała, nie przyczynia się do zbytniego uczenia się.

więc w nawracających sieciach neuronowych warstwy, które otrzymują małą aktualizację gradientu przestają się uczyć. Są to zazwyczaj wcześniejsze warstwy. Ponieważ warstwy te się nie uczą, RNN mogą zapomnieć o tym, co widać w dłuższych sekwencjach, dzięki czemu mają pamięć krótkotrwałą. Jeśli chcesz dowiedzieć się więcej o mechanice nawracających sieci neuronowych w ogóle, możesz przeczytać mój poprzedni post tutaj.
LSTM i GRU jako rozwiązanie
LSTM i GRU jako rozwiązanie pamięci krótkotrwałej. Posiadają wewnętrzne mechanizmy zwane bramkami, które mogą regulować przepływ informacji.

bramki te mogą dowiedzieć się, które dane w sekwencji są ważne, aby je zachować lub wyrzucić. W ten sposób może przekazywać istotne informacje w długim łańcuchu sekwencji, aby przewidywać. Prawie wszystkie najnowocześniejsze wyniki oparte na nawracających sieciach neuronowych są osiągane za pomocą tych dwóch sieci. LSTM i GRU można znaleźć w rozpoznawaniu mowy, syntezie mowy i generowaniu tekstu. Możesz nawet użyć ich do generowania podpisów do filmów.
Ok, więc pod koniec tego postu powinieneś mieć solidne zrozumienie, dlaczego LSTM i GRU są dobre w przetwarzaniu długich sekwencji. Podchodzę do tego z intuicyjnymi wyjaśnieniami i ilustracjami i unikam jak największej ilości matematyki.
intuicja
ok, zacznijmy od eksperymentu myślowego. Załóżmy, że przeglądasz recenzje online, aby ustalić, czy chcesz kupić płatki Life (nie pytaj mnie dlaczego). Najpierw przeczytasz recenzję, a następnie ustalisz, czy ktoś uważał, że jest dobra, czy zła.

Kiedy czytasz recenzję, twój mózg podświadomie pamięta tylko ważne słowa kluczowe. Odbierasz słowa takie jak” niesamowite „i”doskonale zbilansowane śniadanie”. Nie dbasz zbytnio o słowa takie jak” to”,” dał”,” wszystko”,” powinien ” itp. Jeśli znajomy zapyta Cię następnego dnia, co powiedział przegląd, prawdopodobnie nie pamiętasz go słowo w słowo. Możesz jednak pamiętać główne punkty, takie jak „na pewno kupię ponownie”. Jeśli jesteś podobny do mnie, inne słowa znikną z pamięci.

i to jest w zasadzie to, co robi LSTM lub gru. Może nauczyć się przechowywać tylko istotne informacje, aby przewidywać i zapomnieć o nieistotnych danych. W tym przypadku słowa, które zapamiętałeś, sprawiły, że uznałeś, że to było dobre.
przegląd nawracających sieci neuronowych
aby zrozumieć, w jaki sposób LSTM lub GRU osiąga to, przejrzyjmy sieć neuronową nawracającą. RNN działa w ten sposób; pierwsze słowa są przekształcane w wektory czytelne maszynowo. Następnie RNN przetwarza sekwencję wektorów jeden po drugim.

podczas przetwarzania przekazuje poprzedni ukryty stan do następnego kroku sekwencji. Stan ukryty działa jak pamięć sieci neuronowych. Przechowuje informacje o poprzednich danych, które sieć widziała wcześniej.

przyjrzyjmy się komórce RNN, aby zobaczyć, jak obliczysz stan ukryty. Po pierwsze, stan wejściowy i poprzedni stan ukryty są łączone w celu utworzenia wektora. Ten wektor ma teraz informacje o bieżącym wejściu i poprzednich wejściach. Wektor przechodzi przez aktywację tanh, a wyjściem jest nowy stan ukryty, czyli pamięć sieci.

aktywacja tanh
aktywacja tanh służy do regulacji wartości przepływających przez sieć. Funkcja tanh zgniata wartości zawsze pomiędzy -1 i 1.

gdy wektory przepływają przez sieć neuronową, ulega ona wielu transformacjom z powodu różnych operacji matematycznych. Wyobraźmy sobie wartość, która jest nadal mnożona przez powiedzmy 3. Możesz zobaczyć, jak niektóre wartości mogą eksplodować i stać się astronomiczne, powodując, że inne wartości wydają się nieistotne.

funkcja tanh zapewnia, że wartości pozostają pomiędzy -1 i 1, regulując w ten sposób wyjście sieci neuronowej. Możesz zobaczyć, jak te same wartości z góry pozostają między granicami dozwolonymi przez funkcję tanh.

więc to jest RNN. Ma bardzo mało operacji wewnętrznych, ale działa całkiem dobrze, biorąc pod uwagę odpowiednie okoliczności (jak krótkie sekwencje). RNN wykorzystuje znacznie mniej zasobów obliczeniowych niż jego ewolucyjne warianty, LSTM i GRU.
LSTM
LSTM ma podobny przepływ sterowania jak rekurencyjna sieć neuronowa. Przetwarza on przekazywanie danych na informacje, ponieważ propaguje się do przodu. Różnice dotyczą operacji wewnątrz komórek LSTM.

operacje te są używane, aby umożliwić LSTM przechowywanie lub zapominanie informacji. Przyglądanie się tym operacjom może być trochę przytłaczające, więc omówimy to krok po kroku.
core Concept
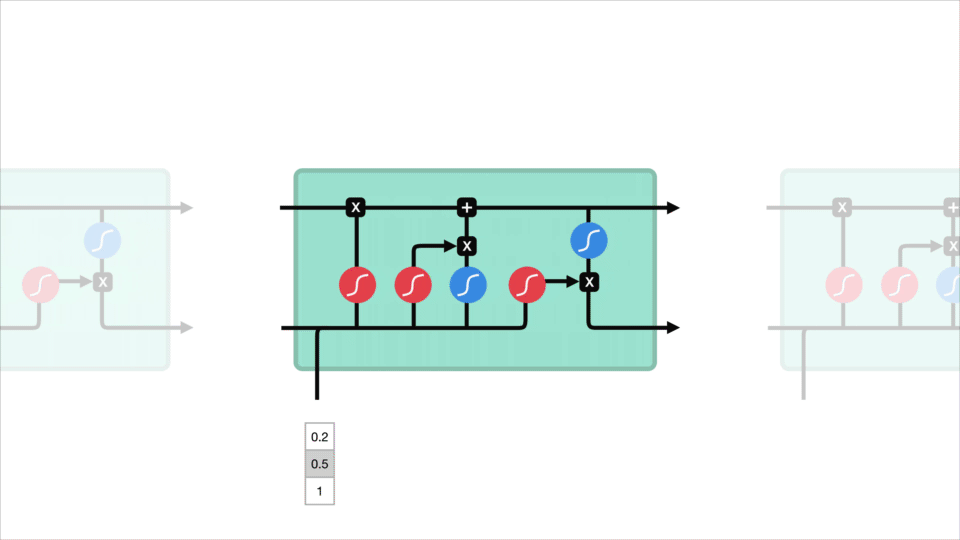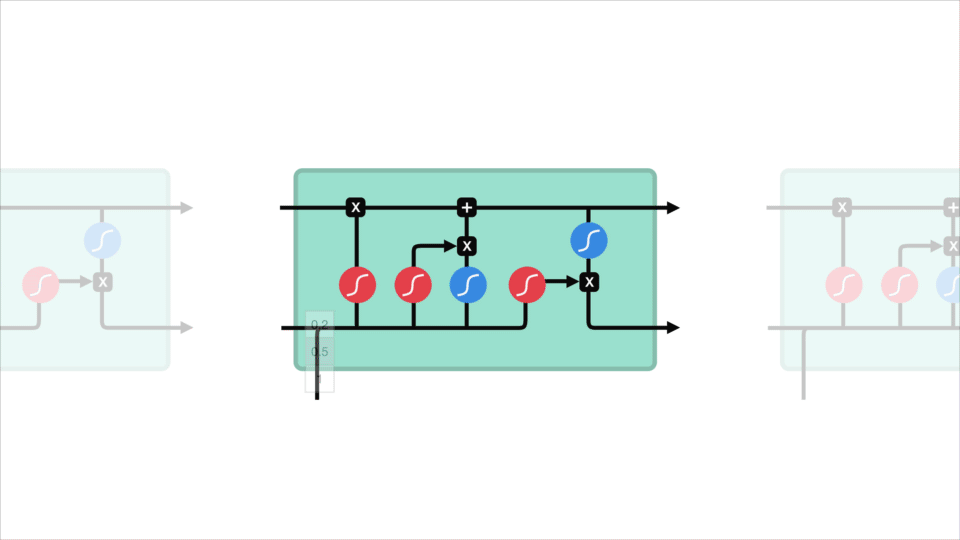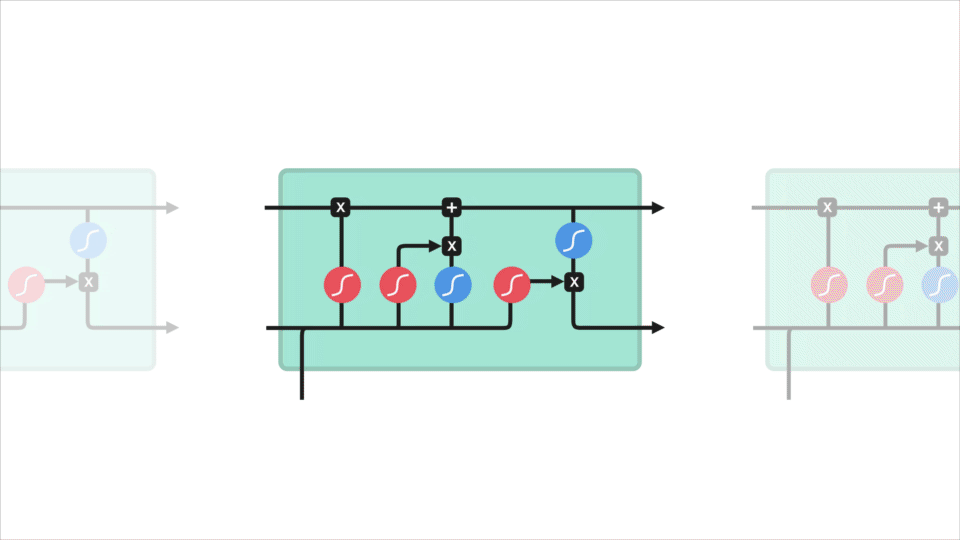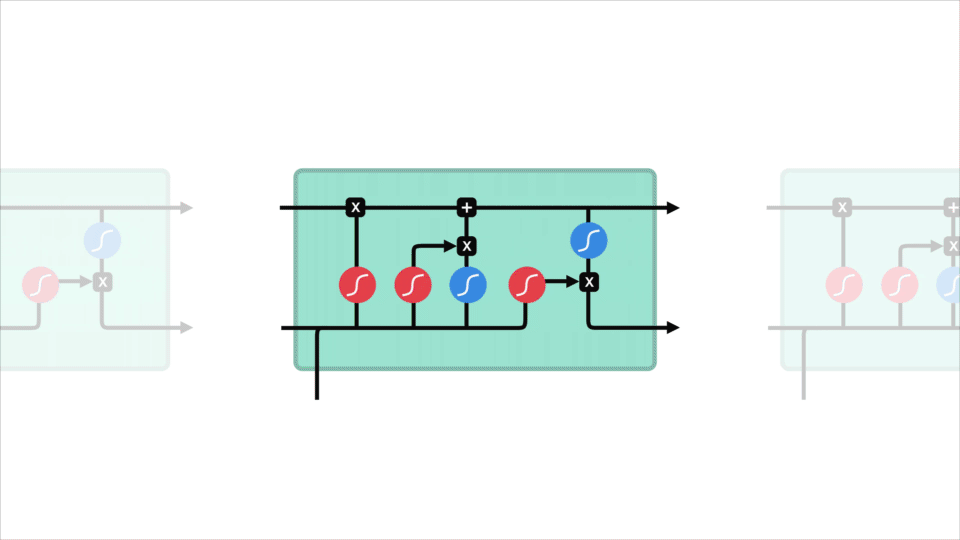
core concept LSTM to stan komórki, a to różne bramy. Stan komórki działa jak autostrada transportowa, która przekazuje względne informacje w całym łańcuchu sekwencji. Można o tym myśleć jako o” pamięci ” sieci. Teoretycznie stan komórki może przenosić istotne informacje podczas przetwarzania sekwencji. Tak więc nawet informacje z wcześniejszych kroków czasowych mogą sprawić, że będzie to droga do późniejszych kroków czasowych, zmniejszając skutki pamięci krótkotrwałej. Gdy stan komórki idzie w swoją podróż, informacje get są dodawane lub usuwane do stanu komórki przez Gatesa. Bramki to różne sieci neuronowe, które decydują, które informacje są dozwolone na temat stanu komórki. Gates może dowiedzieć się, jakie informacje są istotne, aby zachować lub zapomnieć podczas szkolenia.
Esica
Gates zawiera aktywacje esicy. Aktywacja esicy jest podobna do aktywacji tanh. Zamiast zgniatać wartości od -1 do 1, zgniatać wartości od 0 do 1. Pomocne jest aktualizowanie lub zapominanie danych, ponieważ każda liczba pomnożona przez 0 jest równa 0, co powoduje, że wartości znikają lub są „zapomniane”.”Każda liczba pomnożona przez 1 jest tą samą wartością, dlatego wartość pozostaje taka sama lub jest” zachowana.”Sieć może dowiedzieć się, które dane nie są ważne, dlatego można zapomnieć lub które dane są ważne, aby je zachować.

zagłębimy się nieco głębiej w to, co robią różne bramy, dobrze? Mamy więc trzy różne bramki, które regulują przepływ informacji w komórce LSTM. Brama zapomnienia, brama wejściowa i Brama wyjściowa.
Forget gate
najpierw mamy forget gate. Ta brama decyduje o tym, jakie informacje należy wyrzucić Lub zachować. Informacje z poprzedniego stanu ukrytego i informacje z bieżącego wejścia są przekazywane przez funkcję esicy. Wartości wychodzą z zakresu od 0 do 1. Im bliżej 0 oznacza zapomnieć, a im bliżej 1 oznacza zachować.

brama wejściowa
aby zaktualizować stan komórki, mamy bramę wejściową. Najpierw przekazujemy poprzedni stan ukryty i bieżące wejście do funkcji esicy. To decyduje, które wartości zostaną zaktualizowane, przekształcając wartości z zakresu od 0 do 1. 0 oznacza nieistotne, a 1 oznacza ważne. Przekazujesz również ukryty stan i bieżące wejście do funkcji tanh, aby zgnieść wartości między -1 i 1, aby pomóc regulować sieć. Następnie mnożysz wyjście tanh przez wyjście esicy. Wyjście esicy zadecyduje, które informacje są ważne, aby zachować z wyjścia tanh.

stan komórki
teraz powinniśmy mieć wystarczająco dużo informacji, aby obliczyć stan komórki. Po pierwsze, stan komórki zostaje pomnożony przez wektor forget. Ma to możliwość upuszczenia wartości w stanie komórki, jeśli zostanie pomnożona przez wartości bliskie 0. Następnie pobieramy dane wyjściowe z bramki wejściowej i wykonujemy punktowe dodawanie, które aktualizuje stan komórki do nowych wartości, które sieć neuronowa uzna za istotne. To daje nam nowy stan komórki.

bramka wyjściowa
ostatnia bramka wyjściowa. Bramka wyjściowa decyduje o tym, jaki powinien być następny ukryty stan. Pamiętaj, że stan ukryty zawiera informacje o poprzednich wejściach. Stan ukryty jest również używany do przewidywania. Najpierw przekazujemy poprzedni stan ukryty i bieżące wejście do funkcji esicy. Następnie przekazujemy nowo zmodyfikowany stan komórki do funkcji tanh. Mnożymy wyjście tanh przez wyjście esicy, aby zdecydować, jakie informacje powinien zawierać ukryty stan. Wyjście jest stanem ukrytym. Nowy stan komórki i nowy ukryty są następnie przenoszone do następnego kroku czasowego.

aby przejrzeć, bramka forget decyduje o tym, co należy zachować przed wcześniejszymi krokami. Bramka wejściowa decyduje o tym, jakie informacje należy dodać z bieżącego kroku. Bramka wyjściowa określa, jaki powinien być następny ukryty stan.
Demo kodu
dla tych z Was, którzy rozumieją lepiej poprzez obejrzenie kodu, oto przykład użycia pseudo kodu Pythona.

1. Po pierwsze, poprzedni stan ukryty i bieżące wejście zostają skonkatenowane. Nazwiemy to połączeniem.
2. Połącz get ’ s doprowadzone do warstwy forget. Ta warstwa usuwa nieistotne dane.
4. Warstwa kandydująca jest tworzona za pomocą combine. Kandydat posiada możliwe wartości do dodania do stanu komórki.
3. Połącz również get ’ s doprowadzone do warstwy wejściowej. Ta warstwa decyduje o tym, jakie dane z kandydata należy dodać do nowego stanu komórki.
5. Po obliczeniu warstwy zapomnienia, warstwy kandydującej i warstwy wejściowej, stan komórki jest obliczany przy użyciu tych wektorów i poprzedniego stanu komórki.
6. Wynik jest następnie obliczany.
7. Pomnożenie wyniku i nowego stanu komórki daje nam nowy stan ukryty.
To jest to! Przepływ sterowania w sieci LSTM to kilka operacji tensorowych i pętla for. Możesz używać Stanów ukrytych do przewidywania. Łącząc wszystkie te mechanizmy, LSTM może wybrać, które informacje są istotne do zapamiętania lub zapomnienia podczas przetwarzania sekwencji.
GRU
więc teraz wiemy, jak działa LSTM, przyjrzyjmy się krótko GRU. GRU jest nowszą generacją nawracających sieci neuronowych i jest bardzo podobny do LSTM. GRU pozbyła się stanu komórki i użyła stanu ukrytego do przesyłania informacji. Posiada również tylko dwie bramy, bramę resetowania i bramę aktualizacji.

update Gate
brama aktualizacji działa podobnie do bramy forget I INPUT LSTM. Decyduje, jakie informacje wyrzucić i jakie nowe informacje dodać.
Reset bramy
Brama reset jest inna brama jest używany do decydowania, jak wiele informacji przeszłości zapomnieć.
A to GRU. GRU ma mniej operacji tensorowych; w związku z tym, są one trochę szybciej trenować następnie LSTM. nie ma jasnego zwycięzcy, który z nich jest lepszy. Badacze i inżynierowie zwykle próbują ustalić, który z nich działa lepiej dla ich przypadku użycia.
więc to jest to
podsumowując, RNN są dobre do przetwarzania danych sekwencji do przewidywania, ale cierpi na pamięć krótkotrwałą. LSTM i GRU zostały stworzone jako metoda łagodzenia pamięci krótkotrwałej za pomocą mechanizmów zwanych gates. Gates to po prostu sieci neuronowe, które regulują przepływ informacji przepływających przez łańcuch sekwencji. LSTM i GRU są używane w najnowocześniejszych aplikacjach deep learning, takich jak rozpoznawanie mowy, synteza mowy, rozumienie języka naturalnego itp.
Jeśli jesteś zainteresowany pójściem głębiej, oto linki do fantastycznych zasobów, które mogą dać ci inną perspektywę w zrozumieniu LSTM i GRU. ten post był mocno zainspirowany nimi.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/