nie można łatwo użyć zmiennych kategorycznych jako predyktorów w regresji liniowej: trzeba je podzielić na zmienne dychotomiczne znane jako zmienne obojętne.
idealnym sposobem na ich utworzenie jest nasze narzędzie dummy variables. Jeśli nie chcesz używać tego narzędzia, ten samouczek pokazuje właściwy sposób, aby to zrobić ręcznie.
- przykład i – Dowolna zmienna numeryczna
- przykład II – zmienna numeryczna z sąsiednimi liczbami całkowitymi
- przykład III – zmienna łańcuchowa z konwersją
- przykład IV – zmienna łańcuchowa bez konwersji
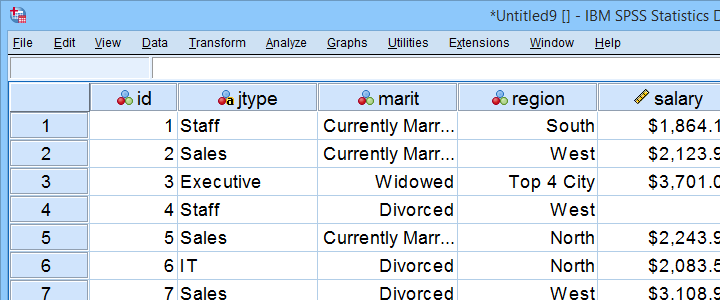
przykładowy plik danych
Ten samouczek używa pięciolinii.sav na całej linii. Część tego pliku danych jest pokazana poniżej.
przykład i – Dowolna zmienna numeryczna
najpierw stwórzmy zmienne obojętne dla marit, skrót od stanu cywilnego. Naszym pierwszym krokiem jest uruchomienie podstawowej tabeli częstotliwości zczęstotliwościami marit.Poniższa tabela przedstawia tabelę wynikową.
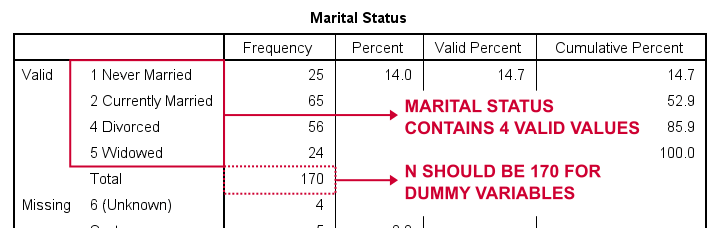
czyli jak podzielić Stan Cywilny na zmienne obojętne? Po pierwsze, zawsze pomijamy jedną kategorię, kategorię referencyjną. Możesz wybrać dowolną kategorię jako kategorię referencyjną.
więc dla tego przykładu wybieramy 5 (owdowiały). Oznacza to, że utworzymy 3 obojętne zmienne reprezentujące kategorie 1, 2 i 4 (zauważ, że 3 nie występuje w tej zmiennej).
poniższa składnia pokazuje jak utworzyć i oznaczyć nasze 3 zmienne. Sprawdźmy to.
Oblicz marit_1 = (marit = 1).
Oblicz marit_2 = (marit = 2).
Oblicz marit_4 = (marit = 4).
*Apply variable labels to dummy variables.
zmienne etykiety
marit_1 'stan cywilny = nigdy nie ożenił się’
marit_2 'stan cywilny = obecnie żonaty’
marit_4 'stan cywilny = Rozwiedziony’.
*szybkie sprawdzenie pierwszej zmiennej atrapy
częstotliwości marit_1.
wyniki
Po pierwsze, zauważ, że stworzyliśmy 3 ładnie oznaczone zmienne obojętne w naszym aktywnym zbiorze danych.
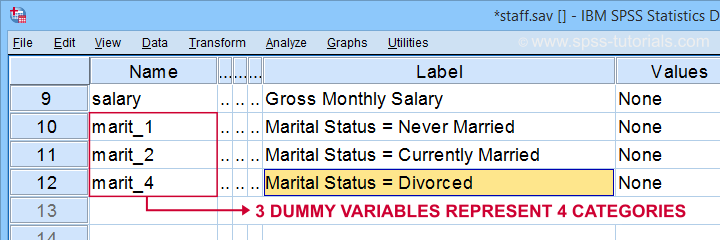
poniższa tabela pokazuje rozkład częstotliwości dla naszej pierwszej dummy zmiennej.

zauważ, że nasza zmienna obojętna posiada 3 różne wartości:
- respondenci, których stan cywilny nie jest „nigdy żonaty” wynik 0;
- respondenci, których stan cywilny nie jest „nigdy żonaty” wynik 1;
- respondenci, których stan cywilny jest wartością brakującą (a zatem nieznaną) mają systemową wartość brakującą.
możemy teraz dokładniej sprawdzić wyniki, uruchamiając crostabs marit przez marit_1 do marit_4.W ten sposób tworzy się 3 tabele awaryjne, z których pierwsza jest pokazana poniżej.
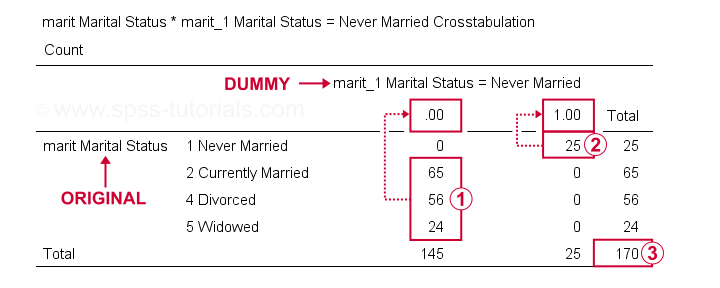
na naszej zmiennej obojętnej, respondenci mający inne statusy małżeńskie niż „nigdy nie ożenił się” wszystkie wynik 0;
respondenci mający inne statusy małżeńskie niż „nigdy nie ożenił się” wszystkie wynik 0; respondenci, którzy „nigdy nie pobrali się” wszystkie wynik 1;
respondenci, którzy „nigdy nie pobrali się” wszystkie wynik 1; mamy wielkość próby N = 170 (ta tabela zawiera tylko respondentów bez brakujących wartości w żadnej ze zmiennych).
mamy wielkość próby N = 170 (ta tabela zawiera tylko respondentów bez brakujących wartości w żadnej ze zmiennych).
Opcjonalnie, ostateczna-bardzo dokładna-kontrola jest porównanie wyników ANOVA dla pierwotnej zmiennej do wyników regresji za pomocą naszych zmiennych obojętnych. Poniższa składnia właśnie to robi, używając miesięcznego wynagrodzenia jako zmiennej zależnej.
regresja
/pensja zależna
/metoda wprowadź marit_1 do marit_4.
* Minimal ANOVA using original variable.
jednodniowe wynagrodzenie Marit.
zauważ, że obie analizy dają identyczne tabele ANOVA. W przyszłym samouczku omówimy bardziej szczegółowo regresję zmiennych ANOVA kontra dummy.
przykład II – zmienna numeryczna z sąsiednimi liczbami całkowitymi
utworzymy teraz atrapy zmiennych dla regionu. Ponownie zaczynamy od sprawdzenia minimalnej tabeli częstotliwości, którą utworzymy przez runningfrequencies region.Wynika to z poniższej tabeli.
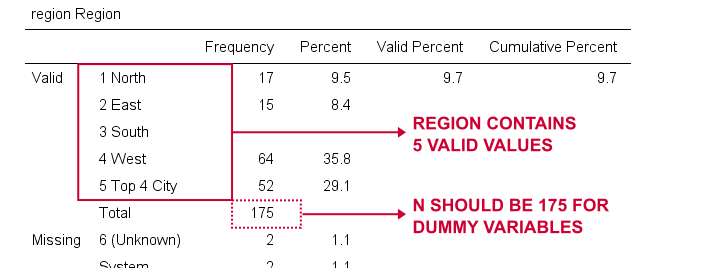
wybierzemy 1 („North”) jako kategorię odniesienia. W związku z tym stworzymy zmienne obojętne dla kategorii od 2 do 5. Ponieważ są to sąsiadujące liczby całkowite, możemy przyspieszyć to, używając DO REPEAT, jak pokazano poniżej.
powtórz #vals = 2 to 5 / #vars = region_2 to region_5.
przekoduj region (#vals = 1) (lo thru hi = 0) Na #vars.
Zakończ powtarzanie wydruku.
*Zastosuj etykiety zmiennych do nowych zmiennych.
etykiety zmienne
region_2 „Region = Wschód”
region_3 „Region = Południe”
region_4 „Region = Zachód”
region_5 „Region = Top 4 Miasto”.
*szybkie sprawdzenie.
crosstabs region by region_2 to region_5 .
dokładna kontrola wynikowych tabel potwierdza, że wszystkie wyniki są poprawne.
przykład III – zmienna łańcuchowa z konwersją
Niestety, nasze pierwsze 2 metody nie działają dla zmiennych łańcuchowych, takich jak jtype-skrót od „job type”). Najprostszym rozwiązaniem jest przekształcenie go w zmienną numeryczną, jak omówiono w SPSS Konwertuj ciąg znaków na zmienną numeryczną. Poniższa składnia używa AUTORECODE, aby wykonać zadanie.
autorecode jtype
/into njtype.
* Sprawdź wynik.
częstotliwości njtype.
*Ustaw brakujące wartości.
brakujące wartości njtype (1,2).
* ponownie sprawdź wynik.
częstotliwości njtype.
Result

ponieważ njtype-skrót od „numeric Job type”- jest zmienną numeryczną, możemy teraz użyć metody i lub metody II do rozbicia jej na dummy zmienne.
przykład IV – zmienna łańcuchowa bez konwersji
Konwersja zmiennych łańcuchowych na liczbowe jest łatwym do wytworzenia dla nich obojętnych zmiennych. Bez tej konwersji Proces jest uciążliwy, ponieważ SPSS nie obsługuje poprawnie brakujących wartości dla zmiennych łańcuchowych. Jednak, składnia poniżej dostaje zadanie wykonane poprawnie.
częstotliwości jtype.
* Chance’ (Unknown) 'na’NA’.
recode jtype ('(Unknown) ’ = 'NA’).
*Ustawia brakujące wartości użytkownika.
brakujące wartości jtype ( ” , „NA”).
* Reinspect frequencies.
częstotliwości jtype.
*Tworzenie zmiennych obojętnych dla zmiennej łańcuchowej.
if(not missing(jtype)) jtype_1 = (jtype = 'IT’).
if(not missing(jtype)) jtype_2 = (Jtype = 'Management’).
if(not missing(jtype)) jtype_3 = (jtype = 'Sales’).
if(not missing(jtype)) jtype_4 = (jtype = 'Staff’).
*Apply variable labels to dummy variables.
variable labels
jtype_1 'job type = IT’
jtype_2 'job type = Management’
jtype_3 'job type = Sales’
jtype_4 'job type = Staff’.
* Sprawdź wyniki.
crosstabs jtype by jtype_1 to jtype_4.
Uwagi końcowe
Tworzenie obojętnych zmiennych dla zmiennych numerycznych można wykonać szybko i łatwo. Ustawienie odpowiednich etykiet zmiennych wymaga jednak zawsze trochę pracy. Zmienne łańcuchowe wymagają dodatkowych kroków, ale są również wykonalne.
jednak najprostszą opcją jest nasze narzędzie SPSS Create Dummy Variables, ponieważ doskonale dba o wszystko.