by William W Wold
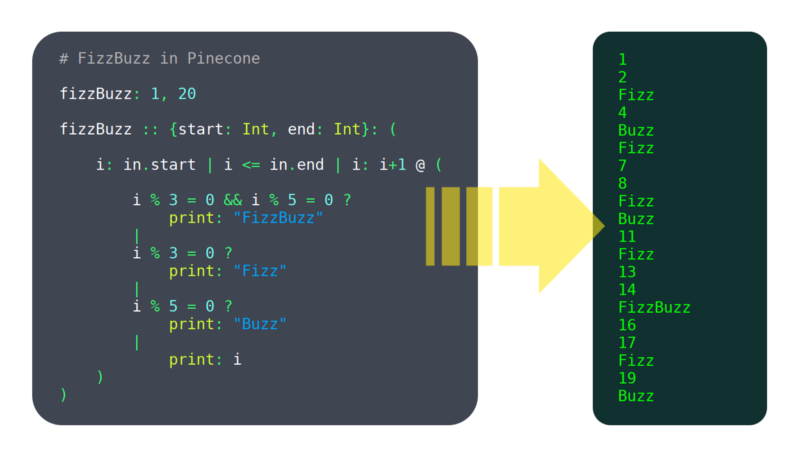
w ciągu ostatnich 6 miesięcy pracowałem nad językiem programowania o nazwie Pinecone. Nie nazwałbym go jeszcze dojrzałym, ale ma już wystarczająco dużo funkcji, aby być użytecznym, takich jak:
- zmienne
- funkcje
- struktury zdefiniowane przez użytkownika
Jeśli jesteś zainteresowany, sprawdź stronę docelową Pinecone lub jego repozytorium GitHub.
nie jestem ekspertem. Kiedy zaczynałem ten projekt, nie miałem pojęcia, co robię i nadal nie mam. brałem zerowe zajęcia z tworzenia języka, czytałem tylko trochę o tym w Internecie i nie zastosowałem się do wielu rad, które otrzymałem.
a jednak stworzyłem zupełnie nowy język. I to działa. Więc muszę robić coś dobrze.
w tym poście zanurkuję pod maską i pokażę Ci, jak Pinecone (i inne języki programowania) zmienia kod źródłowy w magię.
wspomnę też o niektórych kompromisach, które podjąłem i o tym, dlaczego podjąłem decyzje, które podjąłem.
nie jest to bynajmniej kompletny samouczek na temat pisania języka programowania, ale jest to dobry punkt wyjścia, jeśli jesteś ciekawy rozwoju języka.
rozpoczęcie pracy
„nie mam absolutnie pojęcia, od czego w ogóle zacząć” to coś, co często słyszę, gdy mówię innym programistom, że piszę język. W przypadku, gdy jest to twoja reakcja, przejdę teraz przez kilka początkowych decyzji, które są podejmowane i kroki, które są podejmowane podczas uruchamiania każdego nowego języka.
skompilowany i zinterpretowany
istnieją dwa główne typy języków: skompilowany i zinterpretowany:
- kompilator domyśla się wszystkiego, co zrobi program, zamienia go w „kod maszynowy” (format, który komputer może uruchomić bardzo szybko), a następnie zapisuje go do późniejszego wykonania.
- interpreter przechodzi przez kod źródłowy linia po linii, sprawdzając, co robi w trakcie.
technicznie każdy język może być skompilowany lub zinterpretowany, ale jeden lub drugi zwykle ma więcej sensu dla konkretnego języka. Ogólnie interpretacja jest bardziej elastyczna, podczas gdy kompilacja ma większą wydajność. Ale to tylko zarysowanie powierzchni bardzo złożonego tematu.
bardzo cenię sobie wydajność i zauważyłem brak języków programowania, które są zarówno wydajne, jak i zorientowane na prostotę, więc wybrałem compiled for Pinecone.
To była ważna decyzja, którą należy podjąć na początku, ponieważ ma ona wpływ na wiele decyzji dotyczących projektowania języka (na przykład statyczne pisanie jest dużą korzyścią dla języków skompilowanych, ale nie tyle dla języków interpretowanych).
pomimo faktu, że Pinecone został zaprojektowany z myślą o kompilacji, ma w pełni funkcjonalny interpreter, który był jedynym sposobem na uruchomienie go przez jakiś czas. Istnieje wiele powodów, które wyjaśnię później.
wybór języka
wiem, że to trochę meta, ale język programowania sam w sobie jest programem i dlatego trzeba go napisać w jakimś języku. Wybrałem C++ ze względu na jego wydajność i duży zestaw funkcji. Poza tym lubię pracować w C++.
Jeśli piszesz język interpretowany, ma to sens, aby napisać go w skompilowanym (jak C, C++ lub Swift), ponieważ wydajność utracona w języku twojego tłumacza i tłumacza, który interpretuje twojego tłumacza, będzie się łączyć.
jeśli planujesz kompilację, wolniejszy język (jak Python lub JavaScript) jest bardziej akceptowalny. Czas kompilacji może być zły, ale moim zdaniem nie jest to aż tak wielka sprawa, jak zły czas uruchamiania.
projektowanie wysokiego poziomu
język programowania jest ogólnie skonstruowany jako potok. Oznacza to, że ma kilka etapów. Każdy etap ma dane sformatowane w określony, dobrze zdefiniowany sposób. Posiada również funkcje do przekształcania danych z każdego etapu do następnego.
pierwszy etap to łańcuch zawierający cały plik źródłowy. Ostatnim etapem jest coś, co można uruchomić. Wszystko to stanie się jasne, gdy krok po kroku przejdziemy przez rurociąg Pinecone.
Lexing

pierwszym krokiem w większości języków programowania jest lexing lub tokenizacja. „Lex” jest skrótem od analizy leksykalnej, bardzo wymyślne słowo do dzielenia kilku tekstów na tokeny. Słowo „tokenizer” ma o wiele więcej sensu, ale „lexer” jest tak zabawny, że i tak go używam.
tokeny
token jest małą jednostką języka. Token może być zmienną lub nazwą funkcji (AKA identyfikatorem), operatorem lub numerem.
zadanie Lexera
lexer ma przyjąć łańcuch zawierający cały plik z kodem źródłowym i wypluć listę zawierającą każdy token.
przyszłe etapy potoku nie będą odwoływać się do oryginalnego kodu źródłowego, więc lexer musi wygenerować wszystkie potrzebne informacje. Powodem tego stosunkowo ścisłego formatu potoku jest to, że lexer może wykonywać takie zadania, jak usuwanie komentarzy lub wykrywanie, czy coś jest liczbą lub identyfikatorem. Chcesz trzymać tę logikę zamkniętą wewnątrz lexera, tak abyś nie musiał myśleć o tych regułach podczas pisania reszty języka, a więc możesz zmieniać tego typu składnię w jednym miejscu.
Flex
w dniu, w którym zacząłem język, pierwszą rzeczą, którą napisałem, był prosty lexer. Wkrótce potem zacząłem uczyć się o narzędziach, które rzekomo ułatwiałyby lexing i mniej buggy.
dominującym tego typu narzędziem jest Flex, program generujący lexery. Dajesz mu plik, który ma specjalną składnię opisującą gramatykę języka. Z tego generuje program C, który usuwa ciąg znaków i wytwarza pożądane wyjście.
moja decyzja
zdecydowałem się na utrzymanie na razie lexera, który napisałem. W końcu nie widziałem znaczących korzyści z używania Flex – a, przynajmniej nie na tyle, aby uzasadnić dodawanie zależności i komplikowanie procesu budowania.
mój lexer ma tylko kilkaset linijek i rzadko sprawia mi kłopoty. Rolowanie własnego lexera daje mi również większą elastyczność, na przykład możliwość dodawania operatora do języka bez edytowania wielu plików.
parsowanie

drugim etapem potoku jest parser. Parser zamienia listę tokenów w drzewo węzłów. Drzewo używane do przechowywania tego typu danych jest znane jako abstrakcyjne drzewo składniowe lub AST. Przynajmniej w Pinecone, AST nie ma żadnych informacji o typach lub które identyfikatory są które. Jest to po prostu strukturyzowane tokeny.
obowiązki parsera
parser dodaje strukturę do uporządkowanej listy tokenów, które wytwarza lexer. Aby zatrzymać niejasności, parser musi wziąć pod uwagę nawiasy i kolejność operacji. Samo parsowanie operatorów nie jest zbyt trudne, ale w miarę dodawania kolejnych konstrukcji językowych, parsowanie może stać się bardzo złożone.
Bison
ponownie zapadła decyzja o uruchomieniu biblioteki stron trzecich. Dominującą biblioteką parsingową jest Bison. Bizon działa jak Flex. Piszesz plik w niestandardowym formacie, który przechowuje informacje gramatyczne, a następnie Bison używa go do wygenerowania programu C, który zrobi twoje parsowanie. Nie wybrałem żubra.
dlaczego Custom jest lepszy
W przypadku lexera decyzja o użyciu własnego kodu była dość oczywista. Lexer jest tak trywialnym programem, że nie pisanie własnego czułem się prawie tak głupi, jak nie pisanie własnego „lewostronnego”.
z parserem to inna sprawa. Mój Parser Pinecone ma obecnie 750 linii i napisałem trzy z nich, ponieważ pierwsze dwa były śmieciami.
początkowo podjąłem decyzję z wielu powodów i chociaż nie poszło to całkowicie gładko, większość z nich jest prawdziwa. Najważniejsze z nich są następujące:
- Minimalizuj przełączanie kontekstu w przepływie pracy: przełączanie kontekstu między C++ i Pinecone jest wystarczająco złe bez wrzucania gramatyki Bison gramatyka
- Keep build simple: za każdym razem, gdy zmienia się Gramatyka, Bison musi być uruchomiony przed kompilacją. Może to być zautomatyzowane, ale staje się bólem podczas przełączania między systemami budowania.
- Lubię budować fajne gówno: nie zrobiłem Pinecone, bo myślałem, że będzie łatwo, więc po co miałbym delegować główną rolę, skoro mogę to zrobić sam? Niestandardowy parser może nie być trywialny, ale jest całkowicie wykonalny.
na początku nie byłem do końca pewien, czy podążam realną ścieżką, ale zaufało mi to, co Walter Bright (programista wczesnej wersji C++ i twórca języka D) miał do powiedzenia na ten temat:
„nieco bardziej kontrowersyjny, nie traciłbym czasu na generatory lexera lub parsera i inne tak zwane Kompilatory kompilatorów.”To strata czasu. Pisanie lexera i parsera to niewielki procent zadania pisania kompilatora. Korzystanie z generatora zajmie mniej więcej tyle czasu, co pisanie jednego ręcznie, i będzie się wiązało z generatorem (co ma znaczenie przy przenoszeniu kompilatora na nową platformę). Generatory mają też niefortunną reputację emitowania kiepskich komunikatów o błędach.”
drzewo akcji
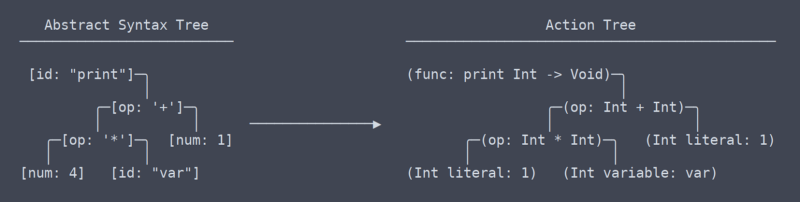
opuściliśmy obszar pojęć powszechnych, uniwersalnych, a przynajmniej Nie wiem jakie są warunki. Z mojego zrozumienia, to, co nazywam „drzewem akcji”, jest najbardziej zbliżone do ir LLVM (pośredniej reprezentacji).
istnieje subtelna, ale bardzo znacząca różnica między drzewem akcji a abstrakcyjnym drzewem składni. Zajęło mi sporo czasu, aby dowiedzieć się, że nawet powinna być różnica między nimi (co przyczyniło się do potrzeby przepisywania parsera).
drzewo akcji vs AST
mówiąc prościej, drzewo akcji jest AST z kontekstem. Tym kontekstem jest informacja, np. jaki typ zwraca funkcja, lub że dwa miejsca, w których używana jest zmienna, w rzeczywistości używają tej samej zmiennej. Ponieważ musi zrozumieć i zapamiętać cały ten kontekst, kod generujący drzewo akcji potrzebuje wielu tabel wyszukiwania przestrzeni nazw i innych rzeczy.
uruchamianie drzewa akcji
gdy mamy już drzewo akcji, uruchamianie kodu jest łatwe. Każdy węzeł akcji ma funkcję 'execute’, która pobiera dane wejściowe, robi to, co powinna (w tym ewentualnie wywołuje Poddziałanie) i zwraca dane wyjściowe. To jest tłumacz w akcji.
opcje kompilacji
” ale czekaj!”Słyszę, jak mówisz,” czy Pinecone nie powinno być skompilowane?”Tak, jest. Ale kompilowanie jest trudniejsze niż interpretacja. Istnieje kilka możliwych podejść.
Zbuduj własny kompilator
na początku brzmiało to dla mnie jak dobry pomysł. Uwielbiam robić rzeczy sama, i od dawna szukam wymówki, żeby być dobrym w montażu.
Niestety pisanie przenośnego kompilatora nie jest tak proste jak pisanie kodu maszynowego dla każdego elementu języka. Ze względu na liczbę architektur i systemów operacyjnych, pisanie kompilatora wieloplatformowego jest niepraktyczne dla każdej osoby.
nawet zespoły stojące za Swift, Rust i Clang nie chcą zajmować się tym wszystkim na własną rękę, więc zamiast tego wszyscy używają…
LLVM
LLVM jest zbiorem narzędzi kompilatora. Jest to w zasadzie biblioteka, która zamieni twój język w skompilowany plik wykonywalny. Wydawało się, że to idealny wybór, więc wskoczyłem do środka. Niestety nie sprawdziłam jak głęboka jest woda i od razu utonęłam.
LLVM, choć nie assembly language hard, jest gigantyczną, złożoną biblioteką hard. Nie jest to niemożliwe do użycia, i mają dobre samouczki, ale zdałem sobie sprawę, że będę musiał trochę praktyki, zanim będę gotowy do pełnego wdrożenia kompilatora Pinecone z nim.
Transpiling
chciałem jakiegoś skompilowanego Pinecone i chciałem go szybko, więc zwróciłem się do jednej metody, którą wiedziałem, że mogę zrobić pracę: transpiling.
napisałem Pinecone do transpilera C++ i dodałem możliwość automatycznej kompilacji źródła wyjściowego z GCC. Obecnie działa to dla prawie wszystkich programów Pinecone (chociaż istnieje kilka przypadków, które go łamią). Nie jest to rozwiązanie szczególnie przenośne lub skalowalne, ale działa na razie.
przyszłość
zakładając, że nadal będę rozwijać Pinecone, prędzej czy później otrzyma wsparcie kompilacji LLVM. Podejrzewam, że nie ma znaczenia, ile nad tym pracuję, transpiler nigdy nie będzie całkowicie stabilny, a korzyści z LLVM są liczne. To tylko kwestia tego, kiedy będę miał czas na zrobienie przykładowych projektów w LLVM i opanowanie ich.
do tego czasu interpreter jest świetny dla trywialnych programów, a transpilacja C++ działa dla większości rzeczy, które wymagają większej wydajności.
podsumowanie
mam nadzieję, że sprawiłem, że języki programowania są dla ciebie trochę mniej tajemnicze. Jeśli chcesz zrobić jeden sam, Gorąco polecam. Istnieje mnóstwo szczegółów implementacji, aby dowiedzieć się, ale zarys tutaj powinien wystarczyć, aby rozpocząć.
oto moja rada na dobry początek (pamiętajcie, nie bardzo wiem co robię, więc przyjmijcie to z przymrużeniem oka):
- w razie wątpliwości zapraszam. Języki interpretowane są na ogół łatwiejsze w projektowaniu, budowaniu i uczeniu się. Nie zniechęcam Cię do pisania skompilowanego, jeśli wiesz, że chcesz to zrobić, ale jeśli jesteś na płocie, to ja bym poszedł.
- jeśli chodzi o lexery i parsery, rób co chcesz. Istnieją uzasadnione argumenty za i przeciw pisaniu własnych. W końcu, jeśli przemyślisz swój projekt i wdrożysz wszystko w sensowny sposób, nie ma to znaczenia.
- Ucz się z rurociągu, z którym skończyłem. Wiele prób i błędów poszło w projektowaniu rurociągu, który mam teraz. Próbowałem wyeliminować ASTs, ASTs, które zamieniają się w drzewa działań na miejscu, i inne straszne pomysły. Ten rurociąg działa, więc nie zmieniaj go, chyba że masz naprawdę dobry pomysł.
- Jeśli nie masz czasu lub motywacji, aby zaimplementować złożony język ogólnego przeznaczenia, spróbuj zaimplementować ezoteryczny język, taki jak Brainfuck. Te tłumacze mogą być tak krótkie, jak kilkaset linijek.
niewiele żałuję, jeśli chodzi o rozwój Pinecone. Po drodze dokonałem wielu złych wyborów, ale przepisałem większość kodu dotkniętego takimi błędami.
w tej chwili Pinecone jest na tyle dobry, że dobrze funkcjonuje i można go łatwo poprawić. Pisanie Pinecone było dla mnie niezwykle edukacyjnym i przyjemnym doświadczeniem, a to dopiero początek.