Last Updated on February 17, 2021
prediction from a machine learning perspective is a single point that HYS the uncertainty of that prediction.
interwały predykcyjne zapewniają sposób kwantyfikacji i komunikowania niepewności w prognozie. Różnią się one od przedziałów ufności, które zamiast tego dążą do ilościowego określenia niepewności w parametrze populacji, takim jak średnia lub odchylenie standardowe. Przedziały predykcji opisują niepewność dla pojedynczego konkretnego wyniku.
w tym samouczku odkryjesz przedział przewidywania i jak go obliczyć dla prostego modelu regresji liniowej.
Po ukończeniu tego kursu dowiesz się:
- , że przedział predykcji określa niepewność prognozy pojedynczego punktu.
- że przedziały predykcji mogą być szacowane analitycznie dla prostych modeli, ale są trudniejsze dla nieliniowych modeli uczenia maszynowego.
- Jak obliczyć przedział predykcji dla prostego modelu regresji liniowej.
Rozpocznij swój projekt dzięki mojej nowej statystyce książki do uczenia maszynowego, w tym samouczkom krok po kroku i plikom kodu źródłowego Pythona dla wszystkich przykładów.
zaczynajmy.
- Zaktualizowano czerwiec/2019: Poprawiono poziom istotności jako ułamek odchyleń standardowych.
- Zaktualizowano kwiecień / 2020: Poprawiono literówkę na wykresie przedziału przewidywania.

Prediction Intervals for Machine Learning
Photo by Jim Bendon, some rights reserved.
opis samouczka
Ten samouczek jest podzielony na 5 części; są to:
- co jest nie tak z oszacowaniem punktu?
- co to jest przedział przewidywania?
- Jak obliczyć przedział predykcji
- przedział predykcji dla regresji liniowej
- działający przykład
potrzebujesz pomocy ze statystykami do uczenia maszynowego?
weź mój darmowy 7-dniowy crash course e-mail teraz (z przykładowym kodem).
Kliknij, aby się zapisać, a także otrzymać darmową wersję ebooka kursu w formacie PDF.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.predict(X)
|
gdzie yhat jest szacunkowym wynikiem lub prognozą wykonaną przez wytrenowany model dla danych wejściowych X.
jest to przewidywanie punktowe.
z definicji jest to oszacowanie lub przybliżenie i zawiera pewną niepewność.
niepewność wynika z błędów w samym modelu i szumu w danych wejściowych. Model jest przybliżeniem zależności między zmiennymi wejściowymi i wyjściowymi.
biorąc pod uwagę proces używany do wyboru i dostrojenia modelu, będzie to najlepsze przybliżenie wykonane z dostępnych informacji, ale nadal będzie popełniać błędy. Dane z tej dziedziny w naturalny sposób zaciemniają podstawową i nieznaną relację między zmiennymi wejściowymi i wyjściowymi. To sprawi, że dopasowanie modelu będzie wyzwaniem, a także będzie wyzwaniem dla modelu dopasowania do przewidywania.
biorąc pod uwagę te dwa główne źródła błędów, ich przewidywanie punktowe z modelu predykcyjnego jest niewystarczające do opisania prawdziwej niepewności prognozy.
Co To jest przedział przewidywania?
przedział predykcji jest kwantyfikacją niepewności na prognozie.
zapewnia probabilistyczną górną i dolną granicę oszacowania zmiennej wynikowej.
przedział przewidywania dla pojedynczej przyszłej obserwacji to przedział, który z określonym stopniem ufności będzie zawierał przyszłą losowo wybraną obserwację z rozkładu.
— Strona 27, interwały statystyczne: Przewodnik dla praktyków i badaczy, 2017.
przedziały predykcji są najczęściej używane podczas tworzenia prognoz lub prognoz z modelem regresji, w którym przewidywana jest ilość.
przykład prezentacji przedziału predykcji jest następujący:
biorąc pod uwagę predykcję ” y „pod uwagę „x”, istnieje 95% prawdopodobieństwo, że zakres ” A ” do ” b ” obejmuje prawdziwy wynik.
przedział przewidywania otacza przewidywania wykonane przez model i mam nadzieję, że obejmuje zakres prawdziwego wyniku.
poniższy diagram pomaga wizualnie zrozumieć związek między przewidywaniem, interwałem przewidywania i faktycznym wynikiem.
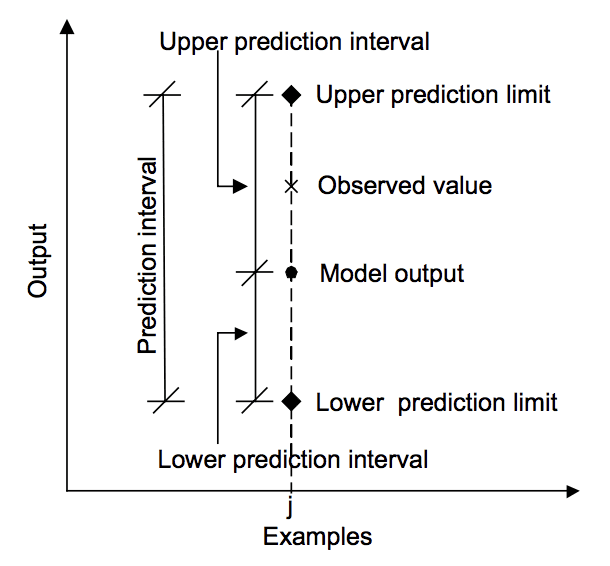
zależność między przewidywaniem, wartością rzeczywistą a przedziałem przewidywania.
zaczerpnięte z „Machine learning approaches for estimation of prediction interval for the model output”, 2006.
przedział predykcji różni się od przedziału ufności.
przedział ufności określa ilościowo niepewność oszacowanej zmiennej populacyjnej, takiej jak średnia lub odchylenie standardowe. Podczas gdy przedział predykcji określa ilościowo niepewność na pojedynczej obserwacji oszacowanej z populacji.
w modelowaniu predykcyjnym przedział ufności może być użyty do określenia niepewności szacowanej umiejętności modelu, podczas gdy przedział predykcyjny może być użyty do określenia niepewności pojedynczej prognozy.
przedział predykcji jest często większy niż przedział ufności, ponieważ musi brać pod uwagę przedział ufności i wariancję zmiennej wyjściowej.
przedziały predykcji będą zawsze szersze niż przedziały ufności , ponieważ uwzględniają niepewność związaną z e, nieredukowalnym błędem.
— strona 103, An Introduction to Statistical Learning: with Applications in R, 2013.
Jak obliczyć przedział predykcji
przedział predykcji jest obliczany jako pewna kombinacja szacowanej wariancji modelu i wariancji zmiennej wynikowej.
przedziały predykcji są łatwe do opisania, ale trudne do obliczenia w praktyce.
w prostych przypadkach, takich jak regresja liniowa, możemy bezpośrednio oszacować przedział predykcji.
w przypadku algorytmów regresji nieliniowej, takich jak sztuczne sieci neuronowe, jest to o wiele trudniejsze i wymaga wyboru i wdrożenia Specjalistycznych Technik. Można użyć ogólnych technik, takich jak metoda resamplingu bootstrap, ale obliczenia są kosztowne.
artykuł „A Comprehensive Review of Neural Network-based Prediction Intervals and New Advances” zawiera stosunkowo niedawne badania interwałów predykcyjnych dla modeli nieliniowych w kontekście sieci neuronowych. Poniższa lista podsumowuje niektóre metody, które mogą być wykorzystane do przewidywania niepewności dla nieliniowych modeli uczenia maszynowego:
- metoda Delta, z dziedziny regresji nieliniowej.
- metoda bayesowska, z bayesowskiego modelowania i statystyki.
- metoda estymacji średniej wariancji, z wykorzystaniem statystyk szacunkowych.
- metoda Bootstrap, wykorzystująca resampling danych i rozwijająca zespół modeli.
obliczenie przedziału predykcyjnego możemy wykonać na przykładzie w następnej sekcji.
przedział predykcji dla regresji liniowej
regresja liniowa jest modelem, który opisuje liniową kombinację wejść do obliczania zmiennych wyjściowych.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
nie znamy prawdziwych wartości współczynników B0 i b1. Nie znamy również rzeczywistych parametrów populacji, takich jak średnia i odchylenie standardowe dla x lub y. wszystkie te elementy muszą być oszacowane, co wprowadza niepewność do stosowania modelu w celu przewidywania.
możemy przyjąć pewne założenia, takie jak rozkłady X i y, a błędy predykcji dokonane przez model, zwane pozostałościami, są Gaussowe.
przedział predykcji wokół yhat można obliczyć w następujący sposób:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
nie znamy się w praktyce. Możemy obliczyć bezstronne oszacowanie przewidywanego odchylenia standardowego w następujący sposób (zaczerpnięte z metod uczenia maszynowego do szacowania przedziału predykcji dla wyjścia modelu):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
Worked Example
Sprawmy, aby przypadek regresji liniowej przewidywania interwałów był konkretny za pomocą worked example.
najpierw zdefiniujmy prosty zestaw danych o dwóch zmiennych, gdzie zmienna wyjściowa (y) zależy od zmiennej wejściowej (x) z pewnym szumem Gaussa.
poniższy przykład definiuje zestaw danych, którego będziemy używać w tym przykładzie.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# generować zmienne
z import numpy oznacza
z import numpy std
from numpy.random import randn
from numpy.random import seed
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# summarize
print(’x: mean=%.3f stdv=%.3f’ % (mean(x), std(x)))
print(’y: mean=%.3f stdv=%.3f’ % (mean(y), std(y)))
# plot
pyplot.scatter(x, y)
pyplot.show()
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
następnie tworzony jest wykres zbioru danych.
możemy zobaczyć wyraźną zależność liniową między zmiennymi z rozłożeniem punktów podkreślających szum lub błąd losowy w relacji.
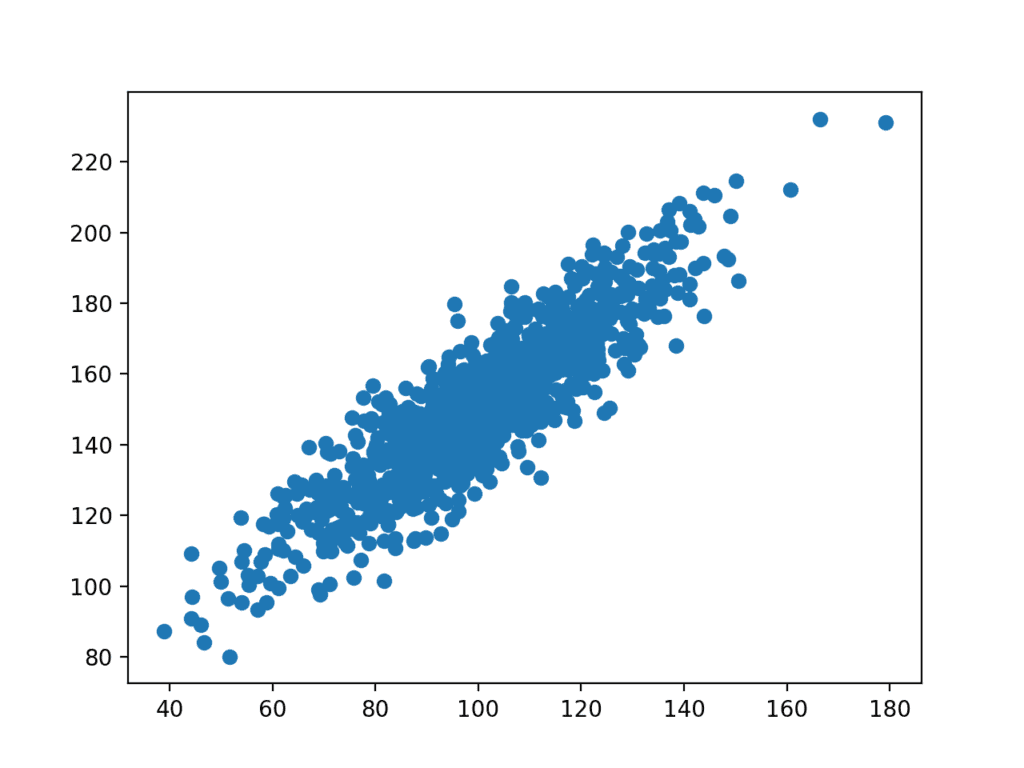
Wykres punktowy zmiennych powiązanych
następnie możemy opracować prostą regresję liniową, która biorąc pod uwagę zmienną wejściową x, przewidzi zmienną y. Możemy użyć funkcji Linregress () SciPy, aby dopasować model i zwrócić współczynniki b0 i b1 dla modelu.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# prosty model regresji nieliniowej
od numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(’b0=%.3f, b1=%.3f’ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r’)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
B0=1.011, B1=49.117spółczynniki są następnie używane z wejściami z zestawu danych do predykcji. Wynikowe dane wejściowe i przewidywane wartości y są wykreślane jako linia na wykresie punktowym dla zbioru danych.
wyraźnie widać, że model nauczył się podstawowej relacji w zbiorze danych. 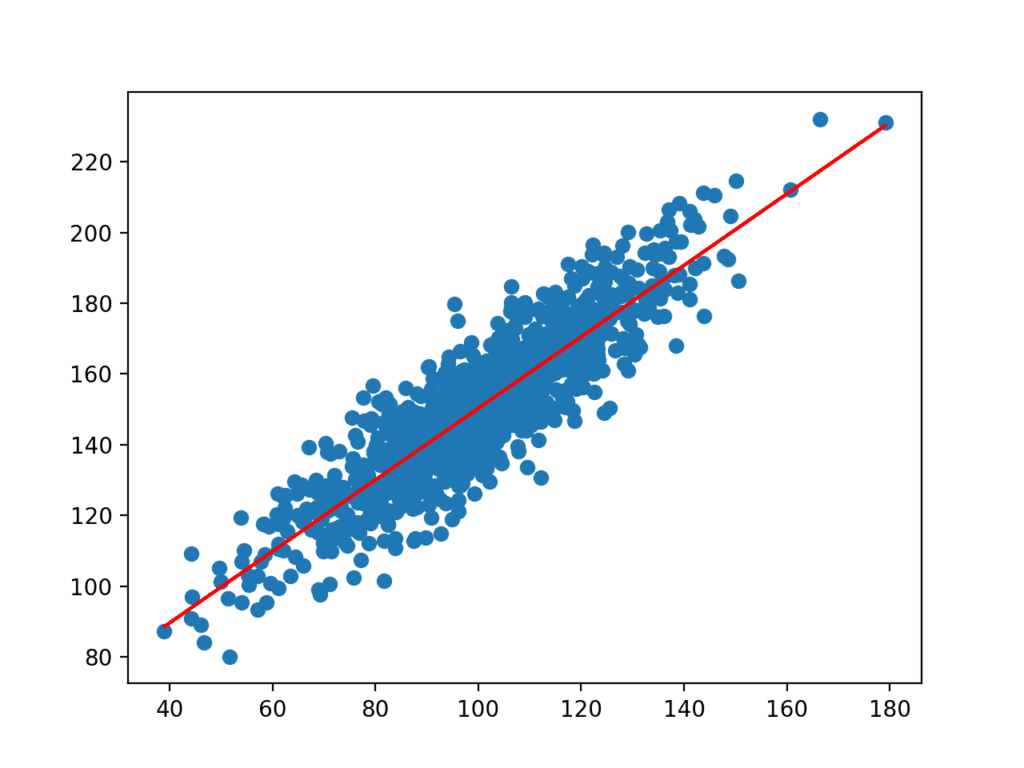
Wykres punktowy zbioru danych z linią dla prostego modelu regresji liniowej jesteśmy teraz gotowi do przewidywania za pomocą naszego prostego modelu regresji liniowej i dodania przedziału predykcji. dopasujemy model jak wcześniej. Tym razem weźmiemy jedną próbkę ze zbioru danych, aby zademonstrować przedział przewidywania. Użyjemy danych wejściowych do wykonania prognozy, obliczymy przedział przewidywania dla prognozy i porównamy prognozę i przedział ze znaną wartością oczekiwaną. najpierw zdefiniujmy wartości wejściowe, przewidywania i oczekiwane.
Dalej możemy ocenić standardową krzywiznę w kierunku prognozowania.
We can calculate this directly using the NumPy arrays as follows:
Next, we can calculate the prediction interval for our chosen input:
We will use the significance level of 95%, which is 1.96 standard deviations. Once the interval is calculated, we can summarize the bounds on the prediction to the user.
We can tie all of this together. The complete example is listed below.
uruchomienie przykładu Szacuje odchylenie standardowe yhat, a następnie oblicza przedział predykcji. po obliczeniu przedział predykcji jest przedstawiany użytkownikowi dla danej zmiennej wejściowej. Ponieważ wymyśliliśmy ten przykład, znamy prawdziwy wynik, który również pokazujemy. Widzimy, że w tym przypadku przedział przewidywania 95% pokrywa rzeczywistą wartość oczekiwaną.
tworzony jest również wykres pokazujący surowy zbiór danych jako wykres punktowy, przewidywania dla zbioru danych jako czerwoną linię, a przewidywania i przedział przewidywania jako czarną kropkę i linię odpowiednio. 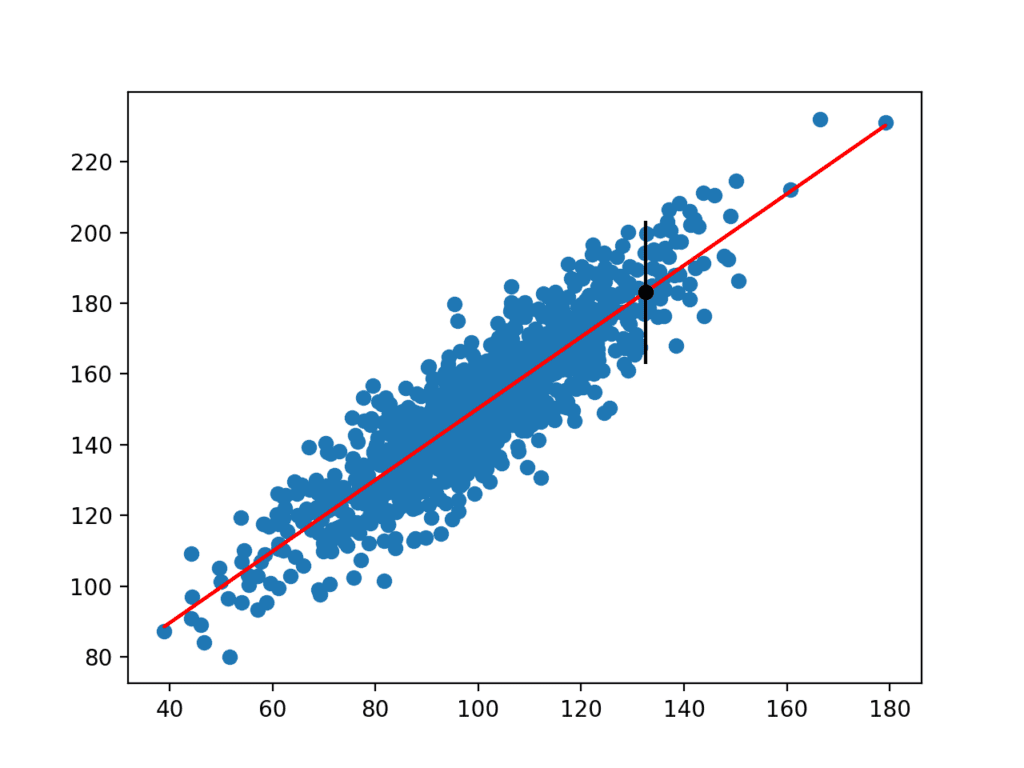
Wykres punktowy zbioru danych z Modelem liniowym i przedziałem predykcji rozszerzeniaTa sekcja zawiera kilka pomysłów na rozszerzenie samouczka, które możesz chcieć zbadać.
Jeśli zbadasz którekolwiek z tych rozszerzeń, chciałbym wiedzieć. Czytaj dalejTa sekcja zawiera więcej zasobów na ten temat, jeśli chcesz zagłębić się w ten temat. posty
Książki
referaty
API
Artykuły
podsumowaniew tym samouczku odkryłeś przedział predykcji i jak go obliczyć dla prostego modelu regresji liniowej. w szczególności nauczyłeś się:
masz pytania? Zdobądź statystyki dla uczenia maszynowego!
rozwijają robocze zrozumienie statystyki…pisząc wiersze kodu w Pythonie Dowiedz się, jak w moim nowym ebooku: zapewnia samouczki do samodzielnej nauki na takie tematy jak: dowiedz się, jak przekształcić dane w wiedzęTylko Wyniki. Zobacz co jest w środku Tweet Udostępnij Udostępnij
|
