informacje o wersji: Kod tej strony został przetestowany w Stata 12 .
regresja Poissona służy do modelowania zmiennych liczących.
Uwaga: celem tej strony jest pokazanie, jak korzystać z różnych poleceń analizy danych. Nie obejmuje on wszystkich aspektów procesu badawczego, od którego oczekuje się przeprowadzenia badań. W szczególności nie obejmuje on czyszczenia i sprawdzania danych, weryfikacji założeń, diagnostyki modelu ani potencjalnych analiz następczych.
przykłady regresji Poissona
przykład 1. Liczba osób zabitych przez muły lub kopnięcia konne w armii pruskiej w ciągu roku.Ladislaus Bortkiewicz zebrał dane z 20 tomów preussischen Statistik. Dane te zostały zebrane na 10 korpus armii pruskiej pod koniec 1800 roku w ciągu 20 lat.
przykład 2. Liczba osób stojących przed Tobą w spożywczaku. Predyktory mogą obejmować liczbę przedmiotów oferowanych obecnie w specjalnej obniżonej cenie i to, czy specjalne wydarzenie (np. wakacje, duże wydarzenie sportowe) jest trzy lub mniej dni.
przykład 3. Liczba nagród zdobytych przez uczniów w jednym liceum. Predyktory liczby zdobytych nagród obejmują rodzaj programu, w którym student został zapisany (np. zawodowe, ogólne lub akademickie) i wynik na końcowym egzaminie z matematyki.
Opis danych
w celu zilustrowania wykonaliśmy symulację zestawu danych, na przykład 3 powyżej. W tym przykładzie num_awards jest zmienną wyników i wskazuje liczbę nagród zdobytych przez uczniów w szkole średniej w ciągu roku, matematyka jest ciągłą zmienną predyktorową i reprezentuje wyniki uczniów na egzaminie końcowym z matematyki, a prog jest kategoryczną zmienną predyktorową z trzema poziomami wskazującymi rodzaj programu, do którego uczniowie zostali zapisani.
zacznijmy od załadowania danych i przyjrzenia się statystykom opisowym.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
każda zmienna ma 200 ważnych obserwacji, a ich rozkład wydaje się całkiem rozsądny. W tym konkretnym przypadku średnia bezwarunkowa i wariancja naszej zmiennej wynikowej nie różnią się zbytnio.
kontynuujmy opis zmiennych w tym zbiorze danych. Poniższa tabela pokazuje średnią liczbę nagród według rodzaju programu i wydaje się sugerować, że typ programu jest dobrym kandydatem do przewidywania liczby nagród, naszej zmiennej wyników, ponieważ średnia wartość wyniku wydaje się różnić w zależności od prog.
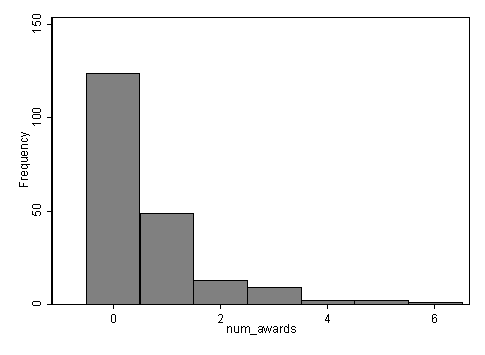
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
metody analizy, które możesz rozważyć
poniżej znajduje się lista niektórych metod analizy, które możesz napotkać. Niektóre z wymienionych metod są całkiem rozsądne, podczas gdy inne wypadły z łask lub mają ograniczenia.
- regresja Poissona – regresja Poissona jest często używana do modelowania danych liczbowych. Regresja Poissona ma wiele rozszerzeń przydatnych dla modeli zliczania.
- ujemna regresja dwumianowa-ujemna regresja dwumianowa może być używana do nadrozdzielonych danych liczbowych, to znaczy, gdy wariancja warunkowa przekracza średnią warunkową. Można ją uznać za uogólnienie regresji Poissona, ponieważ ma taką samą średnią strukturę jak regresja Poissona i ma dodatkowy parametr do modelowania nadmiernej dyspersji. Jeśli rozkład warunkowy zmiennej wynikowej jest nadmiernie rozproszony, przedziały ufności dla ujemnej dwumianregresji są prawdopodobnie węższe w porównaniu do tych z regresji Poissona.
- model regresji bez napompowania-modele bez napompowania próbują uwzględnić nadmiar zer. Innymi słowy, uważa się, że istnieją dwa rodzaje zer w danych, „prawdziwe zera” i „nadmiar zera”. Modele o zerowym napompowaniu szacują dwa równania jednocześnie, jeden dla modelu zliczania i jeden dla nadmiarowych zer.
- regresja OLS – zmienne wyniku liczenia są czasami przekształcane logiem i analizowane za pomocą regresji OLS. Z tym podejściem pojawia się wiele problemów, w tym utrata danych z powodu niezdefiniowanych wartości generowanych przez wzięcie loga zera (który jest niezdefiniowany) i stronnicze szacunki.
regresja Poissona
poniżej używamy polecenia Poissona do oszacowania modelu regresji Poissona. I. before prog wskazuje, że jest zmienną czynnikową (tj., zmienna kategoryczna), oraz że powinna ona być ujęta w modelu jako szereg zmiennych wskaźnikowych.
używamy opcji VCE(solidny) w celu uzyskania solidnych błędów standardowych dla szacunków parametrów zalecanych przez Cameron and Trivedi (2009) do kontroli łagodnego naruszenia podstawowych założeń.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
test chi-kwadrat o dwóch stopniach swobody wskazuje, że prog, wzięty razem, jest statystycznie znaczącym predyktorem num_awards.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
aby pomóc w ocenie dopasowania modelu, można użyć polecenia estat gof do uzyskania testu dobroci dopasowania chi-kwadrat. Nie jest to test współczynników modelu (który widzieliśmy w nagłówku informacji), ale test formy Modelu: Czy formularz modelu Poissona pasuje do naszych danych?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
wnioskujemy, że model pasuje w miarę dobrze, ponieważ test dobroci dopasowania chi-kwadrat nie jest statystycznie istotny. Gdyby badanie było istotne statystycznie, oznaczałoby to, że dane nie pasują do modelu. W takiej sytuacji możemy spróbować ustalić, czy nie ma pominiętych zmiennych predyktorowych, czy nasze założenie liniowości utrzymuje się i / lub czy występuje problem nadmiernej dyspersji.
czasami możemy chcieć przedstawić wyniki regresji jako współczynniki incydentów, możemy użyć opcji IRR. Te wartości IRR są równe naszym współczynnikom z wyjścia powyżej wykładnika.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
powyższe wyjście wskazuje, że liczba incydentów dla 2.prog jest 2,96 razy większy niż wskaźnik incydentów dla grupy odniesienia (1.prog). Podobnie wskaźnik incydentów dla 3.prog jest 1,45-krotnością wskaźnika incydentów dla grupy referencyjnej utrzymującej pozostałe zmienne na stałym poziomie. Procentowa zmiana wskaźnika incydentów num_awards jest wzrostem o 7% dla każdego przyrostu jednostek w matematyce.
przypomnij sobie formę naszego równania modelowego:
log(num_awards) = B1(prog=2) + b2(prog=3) + B3
oznacza to:
num_awards = exp(Intercept + b1(prog=2) + B2(prog=3)+ b3math) = exp(Intercept) * exp(B1(prog=2)) * exp(b2(prog=3)) * exp(b3math)
współczynniki mają efekt addytywny w skali log(y), a IRR ma efekt mnożnikowy w skali y.
aby uzyskać dodatkowe informacje na temat różnych wskaźników, w których można przedstawić wyniki, oraz interpretacji takich, zobacz Modele regresji dla zmiennych zależnych kategorycznie za pomocą Stata, drugie wydanie J. Scott Long i Jeremy Freese (2006).
aby lepiej zrozumieć model, możemy użyć polecenia margins. Poniżej używamy polecenia margins, aby obliczyć przewidywane liczby na każdym poziomie Prog, trzymając wszystkie inne zmienne (w tym przykładzie, math) w modelu na ich średnich wartościach.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
na powyższym wyjściu widzimy, że przewidywana liczba zdarzeń dla poziomu 1 prog wynosi około .21, trzymając matematykę na swoim poziomie. Przewidywana liczba zdarzeń dla poziomu 2 prog jest wyższa na .62, a przewidywana liczba zdarzeń dla poziomu 3 prog wynosi ok .31. Należy zauważyć, że przewidywana liczba poziomu 2 prog jest (.6249446/.211411) = 2,96 razy więcej niż przewidywana liczba dla poziomu 1 prog. To pasuje do tego, co widzieliśmy w tabeli wyników IRR.
poniżej uzyskamy przewidywane liczby dla wartości matematyki w zakresie od 35 do 75 W krokach co 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
powyższa tabela pokazuje, że przy obserwowanych wartościach progowych i matematycznych 35 dla wszystkich obserwacji średnia przewidywana liczba (lub średnia liczba nagród) wynosi ok .13; gdy matematyka = 75, średnia przewidywana liczba wynosi około 2,17. Jeśli porównamy przewidywane liczby w matematyce = 35 i matematyce = 45, możemy zobaczyć, że stosunek jest (.2644714/.1311326) = 2.017. To odpowiada IRR 1.0727 dla zmiany jednostki 10: 1.0727^10 = 2.017.
napisane przez użytkownika polecenie fitstat (jak również polecenia estat Stata) może być użyte do uzyskania dodatkowych informacji, które mogą być pomocne, jeśli chcesz porównać modele. Możesz wpisać search fitstat, aby pobrać ten program (zobacz Jak mogę użyć polecenia wyszukiwania do wyszukiwania programów i uzyskać dodatkową pomoc? więcej informacji na temat korzystania z wyszukiwarki).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
możesz wykreślić przewidywaną liczbę zdarzeń za pomocą poniższych poleceń. Wykres wskazuje, że najwięcej nagród jest przewidywanych dla osób w programie akademickim (prog = 2), zwłaszcza jeśli student ma wysoki wynik matematyczny. Najniższa liczba przewidywanych nagród jest dla tych studentów w programie ogólnym (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
rzeczy do rozważenia
- jeśli wydaje się, że naddyspersja jest problemem, powinniśmy najpierw sprawdź, czy nasz model jest odpowiednio określony, np. pominięte zmienne i formularze funkcyjne. Na przykład, jeśli pominiemy zmienną prognostyczną progin w powyższym przykładzie, nasz model wydaje się mieć problem z nadmierną dyspersją. Innymi słowy, niewłaściwie określony model może stanowić objaw, taki jak problem nadmiernej dyspersji.
- zakładając, że model jest poprawnie określony, możesz sprawdzić foroverdispersion. Istnieje kilka sposobów, aby to zrobić, w tym test współczynnika prawdopodobieństwa nad-dyspersji parametru Alfa poprzez uruchomienie tego samego modelu regresji przy użyciu ujemnego rozkładu dwumianowego (nbreg).
- częstą przyczyną nadmiernej dyspersji jest nadmiar zer, które z kolei są generowane przez dodatkowy proces generowania danych. W tej sytuacji należy rozważyć model zerowy.
- Jeśli proces generowania danych nie pozwala na dowolne 0s (takie jak liczba dni spędzonych w szpitalu), wtedy model obcięty zerem może być bardziej odpowiedni.
- dane liczbowe często mają zmienną ekspozycji, która wskazuje, ile razy zdarzenie mogło się wydarzyć. Zmienna ta powinna zostać włączona do modelu Poissona przy użyciu opcji exp ().
- zmienna wynikowa w regresji Poissona nie może mieć liczb ujemnych, a ekspozycja nie może mieć 0s.
- w Stata model Poissona można oszacować za pomocą polecenia glm z łączem dziennika i rodziną Poissona.
- będziesz musiał użyć polecenia glm, aby uzyskać pozostałości, aby sprawdzić inne założenia modelu Poissona (zobacz Cameron and Trivedi (1998) i Dupont (2002), aby uzyskać więcej informacji).
- istnieje wiele różnych miar pseudo-R-kwadrat. Wszystkie próbują dostarczyć informacji podobnych do tych dostarczonych przez R-kwadrat w regresji OLS, mimo że żaden z nich nie może być interpretowany dokładnie tak, jak R-kwadrat w regresji OLS jest interpretowany. Aby omówić różne pseudo-r-kwadraty, zobacz Long and Freese (2006) LUB naszą stronę FAQ czym są pseudo-r-kwadraty?.
- regresję Poissona szacuje się za pomocą oszacowania maksymalnego prawdopodobieństwa. Zwykle wymaga dużego rozmiaru próbki.
Zobacz również
- Adnotowane wyjście dla polecenia Poisson
- stata FAQ: Jak mogę użyć countfit przy wyborze modelu zliczania?
- stata online manual
- poisson
- stata FAQs
- jak są obliczane standardowe błędy i przedziały ufności dla wskaźników częstości występowania (IRR) przez Poissona i nbreg?
- Cameron, A. C. and Trivedi, P. K. (2009). Mikroekonometria Za Pomocą Stata. College Station, TX: stata Press.
- Cameron, A. C. and Trivedi, P. K. (1998). Analiza regresji danych liczbowych. New York: Cambridge Press.
- Cameron, A. C. Advances in Count Data Regression Talk for the Applied Statistics Workshop, 28 marca 2009.http://cameron.econ.ucdavis.edu/racd/count.html .
- Dupont, W. D. (2002). Modelowanie statystyczne dla naukowców biomedycznych: proste wprowadzenie do analizy złożonych danych. New York: Cambridge Press.
- Long, J. S. (1997). Modele regresji dla zmiennych kategorycznych i ograniczonych zależnych.Thousand Oaks, CA: Sage Publications.
- Long, J. S. and Freese, J. (2006). Regression Models for Categorical Dependent Variables Using Stata, Second Edition. College Station, TX: stata Press.