czym jest uczenie się przez wzmacnianie?
Uczenie Się wzmacniające jest definiowane jako metoda uczenia maszynowego, która dotyczy sposobu, w jaki agenci oprogramowania powinni podejmować działania w środowisku. Uczenie się przez wzmocnienie jest częścią metody uczenia głębokiego, która pomaga zmaksymalizować część skumulowanej nagrody.
ta metoda uczenia się sieci neuronowych pomaga nauczyć się, jak osiągnąć złożony cel lub zmaksymalizować określony wymiar na wielu etapach.
w samouczku uczenia się przez wzmacnianie dowiesz się:
- czym jest uczenie się przez wzmacnianie?
- ważne terminy używane w metodzie uczenia się głębokiego zbrojenia
- Jak działa Uczenie Się zbrojenia?
- algorytmy uczenia zbrojeniowego
- charakterystyka uczenia zbrojeniowego
- rodzaje uczenia zbrojeniowego
- modele uczenia zbrojeniowego
- Uczenie Się zbrojeniowe vs. uczenie nadzorowane
- zastosowania uczenia zbrojeniowego
- Dlaczego Warto korzystać z uczenia zbrojeniowego?
- kiedy nie stosować uczenia wzmacniającego?
- wyzwania uczenia się zbrojenia
ważne terminy używane w metodzie uczenia głębokiego zbrojenia
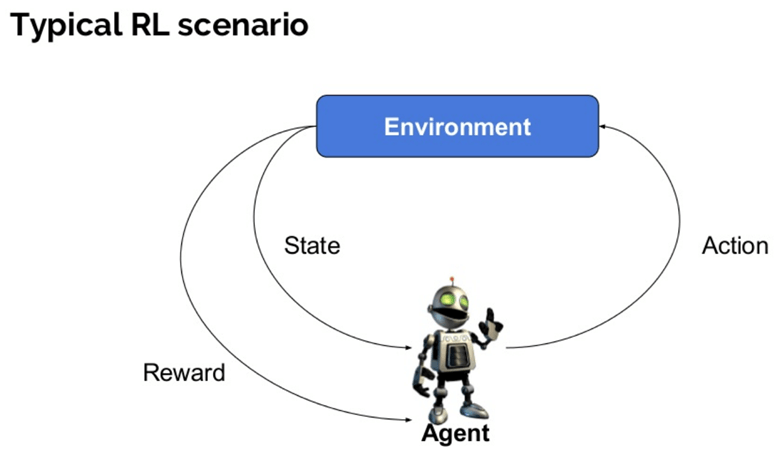
oto kilka ważnych terminów używanych w wzmacnianiu AI:
- Agent: jest to zakładany byt, który wykonuje działania w środowisku, aby uzyskać pewną nagrodę.
- środowisko (e): scenariusz, z którym musi zmierzyć się agent.
- Nagroda (R): Natychmiastowy zwrot udzielany agentowi, gdy wykonuje on określone działanie lub zadanie.
- State (S): State odnosi się do bieżącej sytuacji zwracanej przez środowisko.
- Polityka (?): Jest to strategia stosowana przez agenta do decydowania o następnej akcji w oparciu o obecny stan.
- wartość (V): oczekuje się długoterminowego zwrotu z rabatem, w porównaniu do krótkoterminowej nagrody.
- funkcja Value: określa wartość stanu, który jest całkowitą kwotą nagrody. Jest to agent, którego należy się spodziewać począwszy od tego stanu.
- Model środowiska: naśladuje zachowanie środowiska. Pomaga w wnioskowaniu, a także określa, jak zachowa się środowisko.
- metody oparte na modelach: jest to metoda rozwiązywania problemów uczenia wzmacniającego, która wykorzystuje metody oparte na modelach.
- wartość Q lub wartość akcji (Q): wartość Q jest bardzo podobna do wartości. Jedyną różnicą między nimi jest to, że przyjmuje dodatkowy parametr jako aktualną akcję.
jak działa uczenie się przez wzmacnianie?
zobaczmy prosty przykład, który pomoże Ci zilustrować mechanizm uczenia się wzmacniającego.
zastanów się nad scenariuszem uczenia nowych sztuczek swojego kota
- ponieważ kot nie rozumie angielskiego ani żadnego innego ludzkiego języka, nie możemy jej bezpośrednio powiedzieć, co ma robić. Zamiast tego stosujemy inną strategię.
- naśladujemy sytuację, a kot próbuje reagować na wiele różnych sposobów. Jeśli odpowiedź kota jest pożądana, damy jej rybę.
- teraz, gdy kot jest narażony na taką samą sytuację, kot wykonuje podobną akcję z jeszcze większym entuzjazmem w oczekiwaniu na otrzymanie większej nagrody (pożywienia).
- to jak uczenie się, że kot czerpie z” co robić ” z pozytywnych doświadczeń.
- w tym samym czasie kot uczy się również, czego nie robić w obliczu negatywnych doświadczeń.
Wyjaśnienie przykładu:
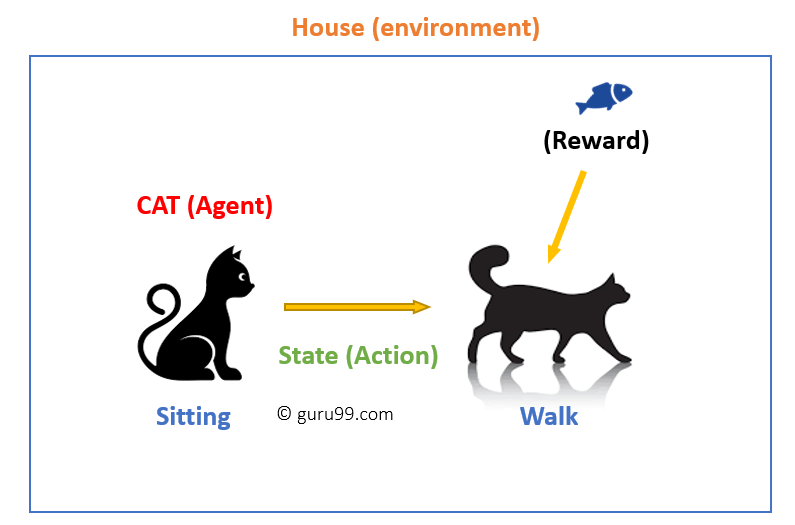
w tym przypadku
- twój kot jest agentem narażonym na działanie środowiska. W tym przypadku jest to twój dom. Przykładem stanu może być twój kot siedzący, a Ty używasz określonego słowa dla kota chodzić.
- nasz agent reaguje wykonując Przejście akcji z jednego „stanu” do innego „stanu.”
- na przykład twój kot przechodzi od siedzenia do chodzenia.
- reakcja agenta jest działaniem, a polityka jest metodą wyboru działania danego stanu w oczekiwaniu lepszych wyników.
- Po przejściu mogą otrzymać nagrodę lub karę w zamian.
algorytmy uczenia zbrojenia
istnieją trzy podejścia do implementacji algorytmu uczenia zbrojenia.
Value-Based:
w metodzie uczenia wzmacniającego opartej na wartościach powinieneś spróbować zmaksymalizować funkcję wartości V(s). W tej metodzie agent spodziewa się długoterminowego powrotu obecnych stanów w ramach polityki ?.
policy-based:
w metodzie RL opartej na zasadach próbujesz wymyślić taką politykę, aby działanie wykonywane w każdym stanie pomogło ci uzyskać maksymalną nagrodę w przyszłości.
dwa rodzaje metod opartych na Polityce to:
- deterministyczne: dla każdego państwa to samo działanie jest wytwarzane przez politykę ?.
- stochastyczny: każde działanie ma pewne prawdopodobieństwo, które określa następujące równanie.Polityka stochastyczna:
n{a\s) = P\A, = a\S, =S]
:
w tej metodzie uczenia się wzmocnienia musisz stworzyć wirtualny model dla każdego środowiska. Agent uczy się działać w tym konkretnym środowisku.
charakterystyka uczenia się zbrojenia
oto ważne cechy uczenia się zbrojenia
- nie ma nadzorcy, tylko liczba rzeczywista lub sygnał nagrody
- sekwencyjne podejmowanie decyzji
- czas odgrywa kluczową rolę w problemach zbrojenia
- informacje zwrotne są zawsze opóźnione, a nie natychmiastowe
- działania agenta określają kolejne dane, które otrzymuje
rodzaje uczenia się zbrojenia
dwa rodzaje metod uczenia się wzmacniającego to:
pozytywne:
jest zdefiniowany jako zdarzenie, które występuje z powodu określonego zachowania. Zwiększa siłę i częstotliwość zachowania oraz wpływa pozytywnie na działanie podejmowane przez agenta.
Ten rodzaj wzmocnienia pomaga zmaksymalizować wydajność i utrzymać zmiany przez dłuższy czas. Jednak zbyt duże wzmocnienie może prowadzić do nadmiernej optymalizacji stanu, co może mieć wpływ na wyniki.
negatywne:
wzmocnienie negatywne jest zdefiniowane jako wzmocnienie zachowania, które występuje z powodu negatywnego stanu, który powinien był zatrzymać lub uniknąć. Pomaga określić minimalną wydajność. Jednak wadą tej metody jest to, że zapewnia wystarczającą ilość, aby spełnić minimalne zachowanie.
modele uczenia się zbrojenia
istnieją dwa ważne modele uczenia się w uczeniu się zbrojenia:
- proces decyzyjny Markowa
- Q uczenie się
proces decyzyjny Markowa
następujące parametry są używane do uzyskania rozwiązania:
- zestaw działań – a
- zestaw Stanów-S
- Nagroda – R
- Polityka – n
- wartość – V
matematyczne podejście do mapowania rozwiązania w uczeniu wzmacniającym jest recon jako proces decyzyjny Markowa lub (MDP).
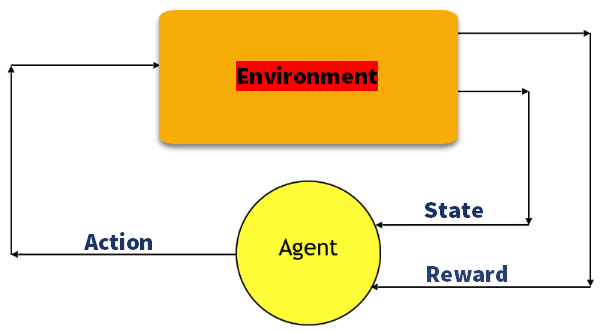
Q-Learning
q learning jest opartą na wartościach metodą dostarczania informacji w celu poinformowania, które działanie powinien podjąć agent.
przyjrzyjmy się tej metodzie na poniższym przykładzie:
- w budynku znajduje się pięć pomieszczeń połączonych drzwiami.
- każdy pokój ma numery od 0 do 4
- na zewnątrz budynku może być jedna duża powierzchnia zewnętrzna (5)
- Drzwi nr 1 i 4 prowadzą do budynku z pokoju 5
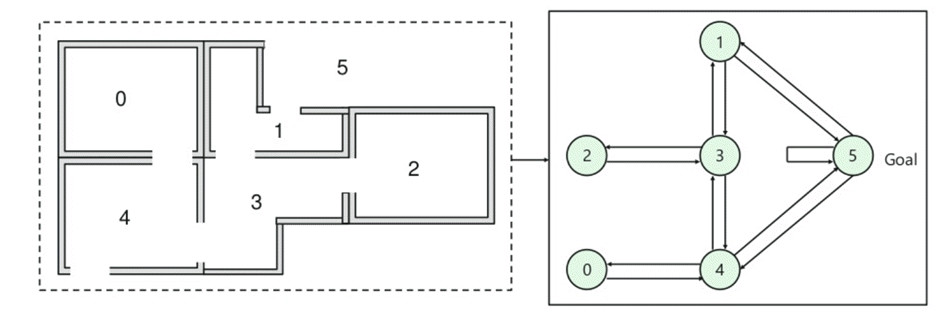
następnie należy przypisać wartość nagrody do każdego z drzwi:
- drzwi, które prowadzą bezpośrednio do celu, mają nagrodę 100
- drzwi, które nie są bezpośrednio połączone z docelowym pokojem, dają zero nagrody
- ponieważ drzwi są dwukierunkowe, a do każdego pokoju przypisane są dwie strzałki
- każda strzałka na powyższym obrazku zawiera natychmiastową wartość nagrody
Wyjaśnienie:
na tym obrazku możesz zobaczyć, że pokój reprezentuje stan
ruch agenta z jednego pokoju do drugiego reprezentuje akcję
na poniższym obrazku, stan jest opisany jako węzeł, podczas gdy strzałki pokazują akcję.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Nadzorowane uczenie się
| parametry | uczenie się przez wzmocnienie | nadzorowane Uczenie Się |
| styl decyzji | uczenie się przez wzmocnienie pomaga podejmować decyzje kolejno. | w tej metodzie podejmowana jest decyzja na wejściu podanym na początku. |
| działa na | działa na interakcji z otoczeniem. | działa na przykładach lub podanych przykładowych danych. |
| zależność od decyzji | w metodzie RL decyzja uczenia się jest zależna. Dlatego powinieneś dać etykiety wszystkim zależnym decyzjom. | nadzorował uczenie się decyzji, które są niezależne od siebie, więc etykiety są podane dla każdej decyzji. |
| najlepiej nadaje się | wspiera i działa lepiej w AI, gdzie interakcja z ludźmi jest powszechna. | jest najczęściej obsługiwany za pomocą interaktywnego systemu oprogramowania lub aplikacji. |
| przykład | gra w szachy | rozpoznawanie obiektów |
zastosowania uczenia zbrojeniowego
oto zastosowania uczenia zbrojeniowego:
- Robotyka dla automatyki przemysłowej.
- planowanie strategii biznesowej
- Uczenie maszynowe i przetwarzanie danych
- pomaga tworzyć systemy szkoleniowe, które zapewniają niestandardowe instrukcje i materiały zgodnie z wymaganiami uczniów.
- sterowanie samolotem i sterowanie ruchem robota
dlaczego warto korzystać z uczenia wzmacniającego?
oto główne powody, dla których warto skorzystać z uczenia przez wzmacnianie:
- pomaga Ci znaleźć, która sytuacja wymaga działania
- pomaga Ci odkryć, która akcja przynosi najwyższą nagrodę w dłuższym okresie.
- Uczenie Się wzmacniające zapewnia również agentowi uczącemu funkcję nagrody.
- pozwala również znaleźć najlepszą metodę uzyskiwania dużych nagród.
kiedy nie stosować uczenia wzmacniającego?
nie można zastosować modelu uczenia się wzmacniającego. Oto kilka warunków, w których nie należy używać modelu uczenia zbrojeniowego.
- gdy masz wystarczająco dużo danych, aby rozwiązać problem za pomocą nadzorowanej metody uczenia się
- musisz pamiętać, że uczenie się wzmacniające jest ciężkie i czasochłonne. w szczególności, gdy przestrzeń działania jest duża.
wyzwania związane z uczeniem się zbrojenia
oto główne wyzwania, z którymi będziesz musiał się zmierzyć podczas zdobywania zbrojenia:
- projektowanie funkcji/nagród, które powinny być bardzo zaangażowane
- parametry mogą wpływać na szybkość uczenia się.
- realistyczne środowiska mogą mieć częściową obserwowalność.
- zbyt duże wzmocnienie może prowadzić do przeciążenia stanów, które mogą zmniejszyć wyniki.
- realistyczne środowiska mogą być niestacjonarne.
podsumowanie:
- uczenie się przez wzmocnienie jest metodą uczenia maszynowego
- pomaga odkryć, które działanie przynosi najwyższą nagrodę w dłuższym okresie.
- trzy metody uczenia się wzmacniającego to: 1) Value-based 2) Policy-based and Model based learning.
- Agent, State, Reward, Environment, Value function Model of the environment, Model based methods, are some important terms using in RL learning method
- przykład uczenia się wzmacniającego to twój kot jest agentem wystawionym na działanie środowiska.
- największą cechą tej metody jest to, że nie ma nadzorcy, tylko liczba rzeczywista lub sygnał nagrody
- dwa rodzaje uczenia się wzmacniającego to 1) Pozytywne 2) negatywne
- dwa powszechnie stosowane modele uczenia to 1) Proces decyzyjny Markova 2) uczenie Q
- metoda uczenia wzmacniającego działa na interakcję z otoczeniem, podczas gdy metoda uczenia nadzorowanego działa na danych przykładowych lub przykładzie.
- metody uczenia się aplikacji lub wzmocnienia są: Robotyka do automatyki przemysłowej i planowania strategii biznesowych
- nie należy stosować tej metody, gdy posiadamy wystarczającą ilość danych do rozwiązania problemu
- największym wyzwaniem tej metody jest to, że parametry mogą wpływać na szybkość uczenia się