VMware High Availability (HA) to narzędzie, które eliminuje potrzebę stosowania dedykowanego sprzętu i oprogramowania rezerwowego w środowisku zwirtualizowanym. VMware HA jest często używany do poprawy niezawodności, skrócenia przestojów w środowiskach wirtualnych i poprawy odzyskiwania po awarii/ciągłości działania.
Ten fragment rozdziału z egzaminu Vcp4: VMware Certified Professional, 2nd Edition by Elias Khnaser bada najlepsze praktyki VMware HA.
VMware High Availability zajmuje się przede wszystkim awarią hosta ESX / ESXi i tym, co dzieje się z maszynami wirtualnymi (vm) działającymi na tym hoście. HA może również monitorować i ponownie uruchamiać maszynę wirtualną, sprawdzając, czy narzędzia VMware nadal działają. Gdy host ESX / ESXi z jakiegokolwiek powodu zawiedzie, wszystkie uruchomione maszyny wirtualne również zawodzą. VMware HA zapewnia, że maszyny wirtualne z uszkodzonego hosta mogą być ponownie uruchamiane na innych hostach ESX/ESXi.
Wiele osób błędnie myli VMware HA z tolerancją błędów. VMware HA nie jest odporny na błędy, ponieważ jeśli host ulegnie awarii, maszyny wirtualne na nim również ulegną awarii. HA zajmuje się tylko restartem tych maszyn wirtualnych na innych hostach ESX/ESXi z wystarczającą ilością zasobów. Z drugiej strony odporność na awarie zapewnia nieprzerwany dostęp do zasobów w przypadku awarii hosta.
 kliknij na zdjęcie okładki książki powyżej
kliknij na zdjęcie okładki książki powyżej Aby pobrać cały rozdział
na temat backupu i wysokiej dostępności.
VMware ha utrzymuje kanał komunikacji ze wszystkimi innymi hostami ESX / ESXi, które są członkami tego samego klastra, używając heartbeat, który wysyła co 1 sekundę w vSphere 4.0 lub co 10 sekund w vSphere 4.1 domyślnie. Gdy serwer ESX nie uderzy w bicie serca, inne hosty czekają 15 sekund, aż inny host ponownie zareaguje. Po 15 sekundach klaster inicjuje restart maszyn wirtualnych na zawodzącym hoście ESX / ESXi na pozostałych hostach ESX / ESXi w klastrze. VMware HA stale monitoruje również hosty ESX / ESXi należące do klastra i zapewnia, że zasoby są zawsze dostępne w celu spełnienia wymagań w przypadku awarii hosta.
monitorowanie awarii maszyny Wirtualnej
monitorowanie awarii maszyny Wirtualnej jest technologią domyślnie wyłączoną. Jego funkcją jest monitorowanie maszyn wirtualnych,które pyta co 20 sekund za pomocą tętna. Robi to za pomocą narzędzi VMware, które są zainstalowane wewnątrz maszyny wirtualnej. Gdy maszyna wirtualna nie trafia w serce, VMware HA uznaje tę maszynę za nieudaną i próbuje ją zresetować. Pomyśl o monitorowaniu awarii maszyn wirtualnych jako o wysokiej dostępności maszyn wirtualnych.
monitorowanie awarii maszyny Wirtualnej może wykryć, czy maszyna wirtualna została ręcznie wyłączona, zawieszona lub migrowana, a tym samym nie próbuje jej ponownie uruchomić.
wymagania wstępne konfiguracji VMware HA
HA wymaga następujących wymagań wstępnych konfiguracji, zanim będzie działać poprawnie:
- vCenter: ponieważ VMware HA jest funkcją klasy korporacyjnej, wymaga vCenter, zanim będzie można go włączyć.
- rozdzielczość DNS: wszystkie hosty ESX / ESXi należące do klastra HA muszą być w stanie rozwiązywać się nawzajem za pomocą DNS.
- dostęp do współdzielonej pamięci masowej: wszystkie hosty w klastrze HA muszą mieć dostęp i widoczność do tej samej współdzielonej pamięci masowej; w przeciwnym razie nie mieliby dostępu do maszyn wirtualnych.
- dostęp do tej samej sieci: Wszystkie hosty ESX / ESXi muszą mieć te same sieci skonfigurowane na wszystkich hostach, tak aby po ponownym uruchomieniu maszyny wirtualnej na dowolnym Hostie miała ona ponownie dostęp do właściwej sieci.
redundancja konsoli serwisowej
Zalecana Praktyka nakazuje redundancję konsoli serwisowej (SC). VMware HA skarży się i wyświetla ostrzeżenie, jeśli wykryje, że konsola usług jest skonfigurowana na vswitchu z tylko jednym vmnic. Jak pokazano na rysunku 1, możesz skonfigurować redundancję konsoli serwisowej na jeden z dwóch sposobów:
- utwórz dwie grupy portów konsoli serwisowej, każda na innym przełączniku vSwitch.
- przypisanie dwóch fizycznych kart interfejsu sieciowego (nic) w postaci zespołu NIC do konsoli serwisowej vSwitch.
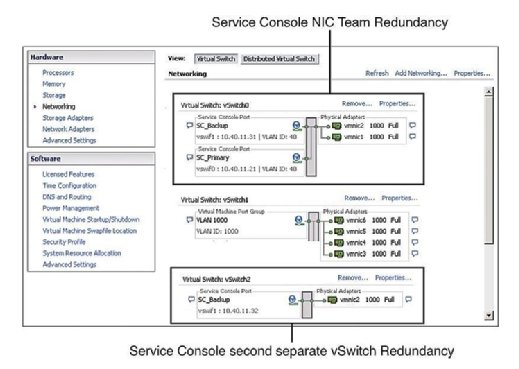
w obu przypadkach należy skonfigurować cały stos IP z adresem IP, podsiecią i bramą. Przełączniki vSwitch konsoli serwisowej są używane do bicia serca i synchronizacji stanu i używają następujących portów:
- przychodzący port TCP 8042
- przychodzący port UDP 8045
- wychodzący port TCP 2050
- wychodzący port UDP 2250
- przychodzący port TCP 8042-8045
- przychodzący port UDP 8042-8045
- wychodzący port TCP 2050-2250
- wychodzący port UDP 2050-2250
brak konfiguracji redundancji SC powoduje wyświetlenie komunikatu ostrzegawczego po włączeniu ha. Tak więc, aby uniknąć wyświetlania tego komunikatu o błędzie i stosować się do najlepszych praktyk, skonfiguruj SC jako redundantny.
planowanie pracy awaryjnej hosta
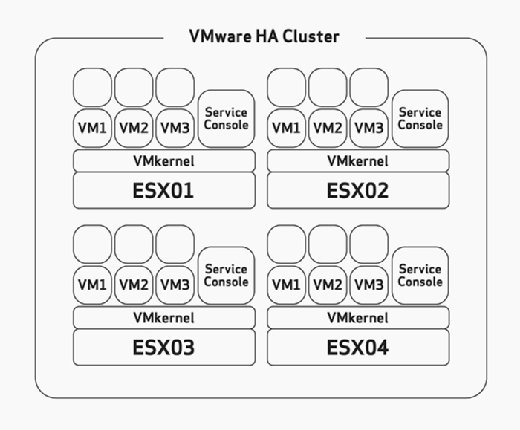
podczas konfigurowania HA należy ręcznie skonfigurować maksymalną tolerancję awarii hosta. Jest to zadanie, które należy starannie rozważyć podczas doboru sprzętu i fazy planowania wdrożenia. Zakłada to, że zbudowałeś hosty ESX/ESXi z wystarczającą ilością zasobów, aby uruchomić więcej maszyn wirtualnych niż planowano, aby móc pomieścić HA. Na przykład, na rysunku 2, zauważ, że klaster HA ma cztery hosty ESX i że wszystkie cztery hosty mają wystarczającą pojemność, aby uruchomić co najmniej trzy kolejne maszyny wirtualne. Ponieważ wszystkie są już uruchomione trzy maszyny wirtualne, oznacza to, że ten klaster może sobie pozwolić na utratę dwóch hostów ESX/ESXi, ponieważ pozostałe dwa hosty ESX/ESXi mogą zasilać sześć nieudanych maszyn wirtualnych bez problemu, jeśli wystąpi awaria.
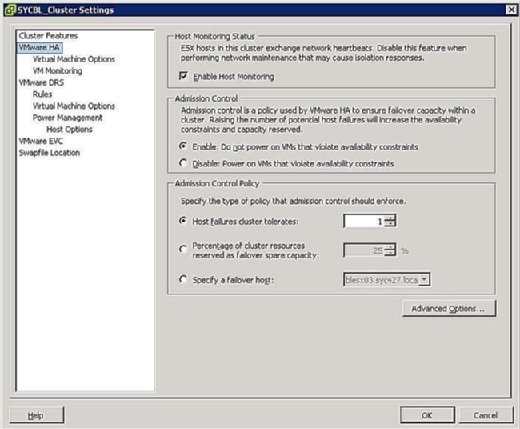
podczas fazy konfiguracji klastra HA wyświetlany jest ekran podobny do tego pokazanego na rysunku 3, który monituje o zdefiniowanie dwóch konfiguracji dla całego klastra w następujący sposób:
- Status monitorowania hosta:
- Włącz monitorowanie hosta: to ustawienie pozwala kontrolować, czy klaster HA powinien monitorować hosty dla bicia serca. Jest to sposób klastra na określenie, czy host jest nadal aktywny. W niektórych przypadkach, gdy uruchamiasz zadania konserwacyjne na hostach ESX / ESXi, może być pożądane wyłączenie tej opcji, aby uniknąć izolowania hosta.
- Kontrola dostępu:
- Enable: nie włączaj maszyn wirtualnych naruszających ograniczenia dostępności: Zaznaczenie tej opcji oznacza, że jeśli nie ma dostępnych zasobów, aby zaspokoić potrzeby maszyny Wirtualnej, nie należy jej włączać.
- Wyłącz: włączaj maszyny wirtualne, które naruszają ograniczenia dostępności: wybranie tej opcji oznacza, że powinieneś włączyć maszynę wirtualną, nawet jeśli musisz przełożyć zasoby.
- zasady kontroli wstępu:
- klaster toleruje błędy hosta: to ustawienie pozwala skonfigurować liczbę błędów hosta, które chcesz tolerować. Dozwolone Ustawienia to od 1 do 4.
- procent zasobów klastra zarezerwowanych jako wolne moce przełączania awaryjnego: Zaznaczenie tej opcji oznacza, że rezerwujesz pewien procent całkowitych zasobów klastra w zapasie do przełączania awaryjnego. W klastrze czterech hostów rezerwacja 25% oznacza, że odkładasz pełnego hosta do przełączania awaryjnego. Jeśli chcesz odłożyć mniej, możesz zamiast tego wybrać 10% zasobów klastra.
- Określ host przełączania awaryjnego: wybranie tej opcji oznacza wybranie konkretnego hosta jako host przełączania awaryjnego w klastrze. Może tak być, jeśli masz zapasowy host lub konkretny host, który ma znacznie więcej zasobów obliczeniowych i pamięci.
izolacja hosta
zjawisko sieciowe znane jako split-brain występuje, gdy host ESX/ESXi przestał odbierać bicie serca od reszty klastra. Bicie serca jest pytane o każdą sekundę w vSphere 4.0 lub 10 sekund w vSphere 4.1. Jeśli odpowiedź nie zostanie odebrana, klaster uważa, że host ESX/ESXi nie powiódł się. W takim przypadku host ESX/ESXi utracił łączność sieciową w interfejsie zarządzania. Host może nadal działać, a Maszyny wirtualne mogą nawet nie zostać naruszone, biorąc pod uwagę, że mogą używać innego interfejsu sieciowego, który nie został naruszony. Jednak vSphere musi podjąć działania, gdy tak się stanie, ponieważ uważa, że host zawiódł. W tym celu powstała odpowiedź izolacji hosta. Reakcja izolacji hosta jest sposobem ha na radzenie sobie z hostem ESX / ESXi, który utracił połączenie sieciowe.
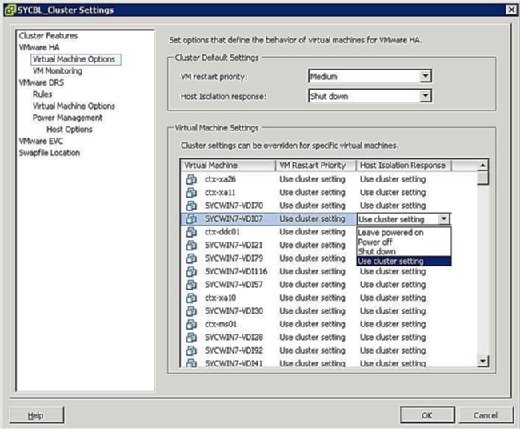
możesz kontrolować, co stanie się z maszynami wirtualnymi w przypadku izolacji hosta. Aby przejść do ekranu odpowiedzi na izolację maszyny wirtualnej, kliknij prawym przyciskiem myszy dany klaster i kliknij Edytuj ustawienia. Następnie możesz kliknąć Opcje maszyny Wirtualnej pod banerem VMware HA w lewym okienku. Możesz kontrolować opcje w klastrze, odpowiednio ustawiając opcję odpowiedzi izolacji hosta. Jest to stosowane do wszystkich maszyn wirtualnych na dotkniętym hoście. Mając to na uwadze, zawsze można nadpisać ustawienia klastra, definiując inną odpowiedź na poziomie maszyny wirtualnej.
jak pokazano na rysunku 4, opcje odpowiedzi na izolację są następujące:
- Leave Powered On: jak sugeruje etykieta, to ustawienie oznacza, że w przypadku izolacji hosta maszyna wirtualna pozostaje włączona.
- Power Off: to ustawienie definiuje, że w przypadku izolacji maszyna wirtualna jest wyłączona. To jest mocne wyłączenie zasilania.
- Shut down: To ustawienie definiuje, że w przypadku izolacji maszyna wirtualna jest wyłączana z wdziękiem za pomocą narzędzi VMware. Jeśli to zadanie nie zostanie zakończone pomyślnie w ciągu pięciu minut, natychmiast zostanie wykonane wyłączenie zasilania. Jeśli narzędzie VMware Tools nie jest zainstalowane, następuje wyłączenie zasilania.
- Użyj ustawienia klastra: to ustawienie przenosi zadanie do Ustawienia klastra zdefiniowanego w oknie pokazanym wcześniej na rysunku 4.
w przypadku izolacji nie musi to oznaczać, że host jest wyłączony. Ponieważ maszyny wirtualne mogą być skonfigurowane z różnymi fizycznymi kartami sieciowymi i podłączone do różnych sieci, mogą nadal działać poprawnie; dlatego należy wziąć to pod uwagę przy ustawianiu priorytetu izolacji. Gdy host jest izolowany, oznacza to po prostu, że jego konsola usługowa nie może komunikować się z resztą hostów ESX/ESXi w klastrze.
priorytet odzyskiwania maszyny Wirtualnej
Jeśli twój klaster HA nie będzie w stanie pomieścić wszystkich maszyn wirtualnych w przypadku awarii, masz możliwość priorytetyzacji na maszynach wirtualnych. Priorytety określają, które Maszyny wirtualne są najpierw uruchamiane ponownie, a które nie są tak ważne w przypadku sytuacji awaryjnej. Opcje te są konfigurowane na tym samym ekranie, co reakcja izolacji opisana w poprzedniej sekcji. Możesz skonfigurować ustawienia dla klastra, które będą stosowane do wszystkich maszyn wirtualnych na danym hoście, lub nadpisać ustawienia klastra, konfigurując nadpisanie na poziomie maszyny wirtualnej.
możesz ustawić priorytet restartu maszyny wirtualnej na jeden z następujących:
- High: Maszyny o wysokim priorytecie są uruchamiane ponownie jako pierwsze.
- Medium: jest to ustawienie domyślne.
- Low: maszyny wirtualne o niskim priorytecie są uruchamiane ponownie jako ostatnie.
- Użyj ustawienia klastra: maszyny wirtualne są uruchamiane ponownie na podstawie ustawienia zdefiniowanego na poziomie klastra zdefiniowanego w oknie pokazanym na rysunku poniżej.
- wyłączone: maszyna wirtualna nie włącza się.
priorytet powinien być ustawiony na podstawie ważności maszyn wirtualnych. Innymi słowy, możesz chcieć ponownie uruchomić kontrolery domeny, a nie ponownie uruchamiać Serwery druku. Maszyny wirtualne o wyższym priorytecie są uruchamiane ponownie jako pierwsze. Maszyny wirtualne, które mogą tolerować pozostały wyłączony w przypadku awarii, powinny być skonfigurowane tak, aby pozostały wyłączony, aby oszczędzać zasoby.
klastrowanie MSCS
głównym celem klastra jest zapewnienie, że krytyczne systemy pozostają online za wszelką cenę i przez cały czas. Podobnie jak maszyny fizyczne, które mogą być klastrowane, maszyny wirtualne mogą być również klastrowane za pomocą ESX przy użyciu trzech różnych scenariuszy:
- Cluster-in-a-box: w tym scenariuszu wszystkie maszyny wirtualne, które są częścią klastra, znajdują się na tym samym hoście ESX/ESXi. Jak można się domyślić, natychmiast tworzy to pojedynczy punkt awarii: host ESX/ESXi. Jeśli chodzi o współdzieloną pamięć masową, można użyć dysków wirtualnych jako współdzielonej pamięci masowej w tym scenariuszu lub można użyć Raw Device Mapping (RDM) w trybie zgodności wirtualnej.
- Cluster-across-boxes: w tym scenariuszu węzły klastra (maszyny wirtualne należące do klastra) znajdują się na wielu hostach ESX/ESXi, dzięki czemu każdy z węzłów tworzących klaster może uzyskać dostęp do tej samej pamięci masowej, tak że jeśli jedna maszyna wirtualna zawiedzie, druga może nadal działać i uzyskać dostęp do tych samych danych. Ten scenariusz tworzy idealne środowisko klastra, eliminując pojedynczy punkt awarii. Współdzielona pamięć masowa jest warunkiem koniecznym i musi znajdować się na Fibre Channel SAN. Dysk RDM należy również używać w trybie zgodności fizycznej lub wirtualnej, ponieważ dyski wirtualne nie są obsługiwaną konfiguracją współdzielonej pamięci masowej. Dzięki temu każdy z węzłów tworzących klaster może uzyskać dostęp do tej samej pamięci masowej, dzięki czemu w przypadku awarii jednej maszyny wirtualnej druga może nadal działać i uzyskiwać dostęp do tych samych danych.
- Klaster fizyczno-wirtualny: W tym scenariuszu jeden członek klastra jest maszyną wirtualną, podczas gdy drugi członek jest maszyną fizyczną. Współdzielona pamięć masowa jest warunkiem wstępnym w tym scenariuszu i musi być skonfigurowana jako RDM w trybie zgodności fizycznej.
za każdym razem, gdy projektujesz rozwiązanie klastrowe, musisz rozwiązać problem współdzielonej pamięci masowej, która umożliwiałaby wielu hostom lub maszynom wirtualnym dostęp do tych samych danych. vSphere oferuje kilka metod, za pomocą których można udostępnić współdzieloną pamięć masową w następujący sposób:
- dyski wirtualne: Dysk wirtualny może być używany jako współdzielony obszar pamięci tylko wtedy, gdy wykonujesz klastrowanie w polu-innymi słowy, tylko wtedy, gdy obie maszyny wirtualne znajdują się na tym samym hoście ESX/ESXi.
- RDM w trybie zgodności fizycznej: ten tryb umożliwia podłączenie fizycznej jednostki LUN bezpośrednio do maszyny Wirtualnej lub fizycznej. Tryb ten uniemożliwia korzystanie z funkcji takich jak migawki i jest idealnie stosowany, gdy jeden członek klastra jest maszyną fizyczną, podczas gdy drugi jest maszyną wirtualną.
- RDM w trybie zgodności wirtualnej: ten tryb umożliwia podłączenie fizycznej jednostki LUN bezpośrednio do maszyny Wirtualnej lub fizycznej. Ten tryb zapewnia wszystkie zalety dysków wirtualnych działających na VMFS, w tym migawki i zaawansowane blokowanie plików. Dysk jest dostępny za pośrednictwem hipernadzorcy i jest idealny do konfigurowania scenariusza klastra między skrzynkami, w którym należy zapewnić obu maszynom wirtualnym dostęp do współdzielonej pamięci masowej.
w momencie pisania tego tekstu jedyną usługą klastrowania obsługiwaną przez VMware jest Microsoft Clustering Services (MSCS). Możesz zapoznać się z białą księgą VMware ” Konfiguracja klastra pracy awaryjnej i usługi klastra Microsoft.”
VMware Fault Tolerance
VMware Fault Tolerance (FT) to kolejna forma klastrowania maszyn wirtualnych opracowana przez VMware dla systemów wymagających ekstremalnego czasu pracy. Jedną z najbardziej atrakcyjnych cech FT jest łatwość konfiguracji. FT to po prostu pole wyboru, które można włączyć. W porównaniu do tradycyjnego klastrowania, które wymaga określonych konfiguracji, aw niektórych przypadkach okablowania, FT jest prosty, ale potężny.
Jak to działa?
podczas ochrony maszyn wirtualnych za pomocą funkcji FT, tworzona jest druga maszyna wirtualna w kroku blokady chronionej maszyny, pierwszej maszyny wirtualnej. FT działa poprzez jednoczesne pisanie do pierwszej maszyny wirtualnej i drugiej maszyny Wirtualnej w tym samym czasie. Każde zadanie jest napisane dwa razy. Jeśli klikniesz menu Start na pierwszej maszynie wirtualnej, zostanie również kliknięte menu Start na drugiej maszynie wirtualnej. Moc FT to jego zdolność do synchronizacji obu maszyn wirtualnych.
Jeśli z jakiegokolwiek powodu chroniona maszyna wirtualna powinna zostać wyłączona, wtórna maszyna wirtualna natychmiast zajmuje jej miejsce, przejmując jej tożsamość i adres IP, kontynuując bez przerwy obsługę użytkowników. Nowo promowana chroniona maszyna wirtualna tworzy dla siebie dodatkową maszynę na innym hoście, a cykl uruchamia się ponownie.
aby wyjaśnić, zobaczmy przykład. Jeśli chcesz chronić serwer Exchange, możesz włączyć FT. Jeśli z jakiegokolwiek powodu host ESX/ESXi, który jest nośnikiem chronionej maszyny wirtualnej, zawiedzie, druga maszyna wirtualna uruchamia się i przejmuje swoje obowiązki bez przerwy w działaniu.
poniższa tabela przedstawia różne technologie wysokiej dostępności i klastrowania, do których masz dostęp za pomocą vSphere, i podkreśla ograniczenia każdej z nich.

wymagania dotyczące tolerancji na błędy
tolerancja błędów nie różni się od innych funkcji przedsiębiorstwa tym, że wymaga spełnienia pewnych warunków wstępnych, zanim technologia będzie mogła funkcjonować prawidłowo i skutecznie. Wymagania te są przedstawione na poniższej liście i podzielone na różne kategorie, które wymagają określonych minimalnych wymagań:
- wymagania hosta:
- procesor kompatybilny z FT. Więcej informacji można znaleźć w tym artykule VMware KB.
- wirtualizacja sprzętowa musi być włączona w BIOSie.
- Taktowanie procesora hosta musi mieścić się w granicach 400 MHz od siebie.
- wymagania maszyn wirtualnych:
- maszyny wirtualne muszą znajdować się na obsługiwanej współdzielonej pamięci masowej (FC, iSCSI i NFS).
- muszą uruchamiać obsługiwany system operacyjny.
- muszą być przechowywane w VMDK lub wirtualnym RDM.
- nie mogą mieć słabo aprowizowanego VMDK i muszą używać wirtualnego dysku Eagerzeroedthick.
- nie mogą mieć skonfigurowanego więcej niż jednego vCPU.
- wymagania klastra:
- wszystkie hosty ESX / ESXi muszą być tej samej wersji i na tym samym poziomie poprawek.
- wszystkie hosty ESX / ESXi muszą mieć dostęp do magazynów danych i sieci maszyn wirtualnych.
- VMware HA musi być włączone w klastrze.
- każdy host musi mieć skonfigurowaną kartę logowania vMotion i FT.
- sprawdzanie certyfikatu hosta również musi być włączone.
maszyny wirtualne
maszyny wirtualne
maszyny wirtualne
maszyny wirtualne
jest wysoce wskazane, aby oprócz sprawdzania zgodności procesora z FT, sprawdzić zgodność marki i modelu serwera z FT z listą zgodności sprzętu VMware (HCL).
chociaż FT jest świetnym rozwiązaniem do klastrowania, ważne jest, aby pamiętać, że ma również pewne ograniczenia. Na przykład Maszyny wirtualne FT nie mogą być snapshotowane i nie mogą być przechowywane w vMotioned. W rzeczywistości te maszyny wirtualne zostaną automatycznie oznaczone jako wyłączone DRS i nie będą uczestniczyć w żadnym dynamicznym równoważeniu obciążenia zasobów.
Jak włączyć FT
włączenie FT nie jest trudne, ale wymaga skonfigurowania kilku różnych ustawień. Następujące ustawienia muszą być poprawnie skonfigurowane, aby FT działało:
- Włącz sprawdzanie certyfikatu hosta: Aby włączyć to ustawienie, Zaloguj się na serwerze vCenter i kliknij Administracja z menu plik i kliknij Ustawienia serwera vCenter. W lewym okienku kliknij Ustawienia SSL i zaznacz pole vCenter wymaga zweryfikowanych certyfikatów SSL hosta.
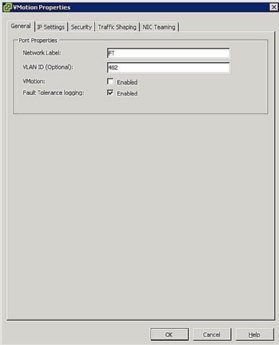
Rysunek 5. Ustawienia grupy portów - Konfiguracja sieci hosta: Konfiguracja sieciowa dla FT jest łatwa i przebiega zgodnie z tymi samymi krokami i procedurami co vMotion, z tym wyjątkiem, że zamiast sprawdzać pole vMotion, sprawdź pole rejestrowania tolerancji błędów, jak pokazano na rysunku 5.
- Włączanie i wyłączanie FT: po spełnieniu poprzednich wymagań możesz teraz włączać i wyłączać FT dla maszyn wirtualnych. Ten proces jest również prosty: znajdź maszynę wirtualną, którą chcesz chronić, kliknij ją prawym przyciskiem myszy i wybierz tolerancja błędów>Włącz tolerancję błędów.
chociaż FT jest technologią klastrowania pierwszej generacji, działa imponująco dobrze i upraszcza skomplikowane tradycyjne metody budowania, konfigurowania i utrzymywania klastrów. FT jest imponującą technologią z punktu widzenia czasu pracy i płynnego przełączania awaryjnego.