Aktiveringsfunktioner är den viktigaste delen av alla neurala nätverk i djupinlärning. I djupinlärning är mycket komplicerade uppgifter bildklassificering, språkomvandling, objektdetektering etc. som behövs för att adressera med hjälp av neurala nätverk och aktiveringsfunktion. Så utan det är dessa uppgifter extremt komplexa att hantera.
i nötskalet är ett neuralt nätverk en mycket potent teknik i maskininlärning som i grunden imiterar hur en hjärna förstår, hur? Hjärnan tar emot stimuli, som inmatning, från miljön, bearbetar den och producerar sedan utmatningen i enlighet därmed.
introduktion
neurala nätverksaktiveringsfunktioner är i allmänhet den viktigaste komponenten i djupinlärning, de används i grunden för att bestämma produktionen av djupinlärningsmodeller, dess noggrannhet och prestandaeffektivitet hos träningsmodellen som kan designa eller dela upp ett stort neuralt nätverk.
Aktiveringsfunktioner har lämnat betydande effekter på neurala nätverks förmåga att konvergera och konvergenshastighet, vill du inte hur? Låt oss fortsätta med en introduktion till aktiveringsfunktionen, typer av aktiveringsfunktioner & deras betydelse och begränsningar genom denna blogg.
vad är aktiveringsfunktionen?
aktiveringsfunktionen definierar utgången från ingången eller uppsättningen ingångar eller i andra termer definierar nod för utgången från nod som ges i ingångar. De bestämmer sig i princip för att inaktivera neuroner eller aktivera dem för att få önskad utgång. Det utför också en olinjär transformation på ingången för att få bättre resultat på ett komplext neuralt nätverk.
aktiveringsfunktionen hjälper också till att normalisera utgången från alla ingångar i intervallet mellan 1 och -1. Aktiveringsfunktionen måste vara effektiv och det bör minska beräkningstiden eftersom det neurala nätverket ibland utbildas på miljontals datapunkter.
aktiveringsfunktionen bestämmer i princip i något neuralt nätverk att given inmatning eller mottagande av information är relevant eller det är irrelevant. Låt oss ta ett exempel för att bättre förstå vad som är en neuron och hur aktiveringsfunktionen begränsar utgångsvärdet till en viss gräns.
neuronen är i grunden ett vägt medelvärde av ingången, då denna summa passeras genom en aktiveringsfunktion för att få en utgång.
Y = 0=(vikt*input + bias)
Här kan Y vara vad som helst för en neuron mellan intervallet-oändlighet till +oändlighet. Så vi måste binda vår produktion för att få önskad förutsägelse eller generaliserade resultat.
Y = aktiveringsfunktion (kg (vikter*input + bias))
så skickar vi den neuronen till aktiveringsfunktionen till bundna utgångsvärden.
Varför behöver vi Aktiveringsfunktioner?
utan aktiveringsfunktion skulle vikt och förspänning bara ha en linjär transformation, eller neuralt nätverk är bara en linjär regressionsmodell, en linjär ekvation är polynom av en grad som bara är enkel att lösa men begränsad när det gäller förmåga att lösa komplexa problem eller högre grad polynom.
men motsatt till det, tillägg av aktiveringsfunktion till neurala nätverk utför den icke-linjära omvandlingen till inmatning och gör den kapabel att lösa komplexa problem som språköversättningar och bildklassificeringar.
utöver det är Aktiveringsfunktioner differentierbara på grund av vilka de enkelt kan implementera ryggförökningar, optimerad strategi när de utför backpropagationer för att mäta gradientförlustfunktioner i neurala nätverk.
typer av Aktiveringsfunktioner
de mest kända aktiveringsfunktionerna anges nedan,
-
binärt steg
-
linjär
-
ReLU
-
LeakyReLU
-
Sigmoid
-
Tanh
-
softmax
1. Binär steg aktiveringsfunktion
denna aktiveringsfunktion mycket grundläggande och det kommer att tänka på varje gång om vi försöker bunden utgång. Det är i grunden en tröskelbas klassificerare, i detta bestämmer vi något tröskelvärde för att bestämma utdata som neuron ska aktiveras eller avaktiveras.
f(x) = 1 Om x > 0 annat 0 om x < 0
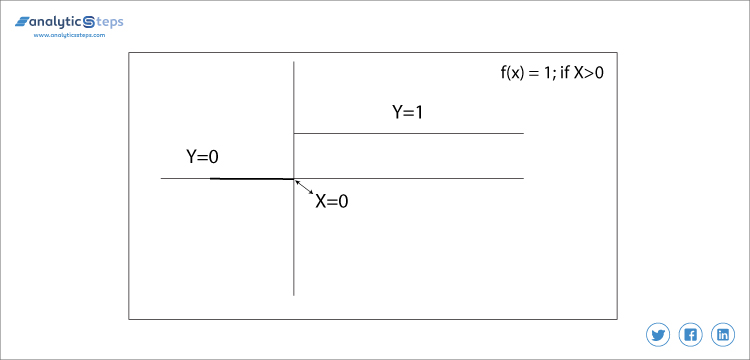
binär stegfunktion
i detta bestämmer vi tröskelvärdet till 0. Det är mycket enkelt och användbart att klassificera binära problem eller klassificerare.
2. Linjär aktiveringsfunktion
det är en enkel rak linjeaktiveringsfunktion där vår funktion är direkt proportionell mot den viktade summan av neuroner eller inmatning. Linjära aktiveringsfunktioner är bättre för att ge ett brett spektrum av aktiveringar och en linje med en positiv lutning kan öka avfyrningshastigheten när ingångshastigheten ökar.
i binär, antingen en neuron skjuter eller inte. Om du vet gradient nedstigning i djupt lärande skulle du märka att i denna funktion derivat är konstant.
Y = mZ
där derivat med avseende på Z är konstant m. meningsgradienten är också konstant och det har inget att göra med Z. I detta, om ändringarna i backpropagation kommer att vara konstanta och inte beroende av Z så kommer det inte att vara bra för lärande.
i detta är vårt andra lager utgången från en linjär funktion av tidigare lageringång. Vänta en minut, vad har vi lärt oss i detta att om vi jämför våra alla lager och tar bort alla lager utom det första och sista så kan vi bara få en utgång som är en linjär funktion av det första lagret.
3. Relu (Rectified Linear unit) Activation function
Rectified linear unit eller ReLU är den mest använda aktiveringsfunktionen just nu som sträcker sig från 0 till oändlighet, alla negativa värden omvandlas till noll, och denna omvandlingsfrekvens är så snabb att varken den kan mappa eller passa in i data korrekt vilket skapar ett problem, men där det finns ett problem finns det en lösning.
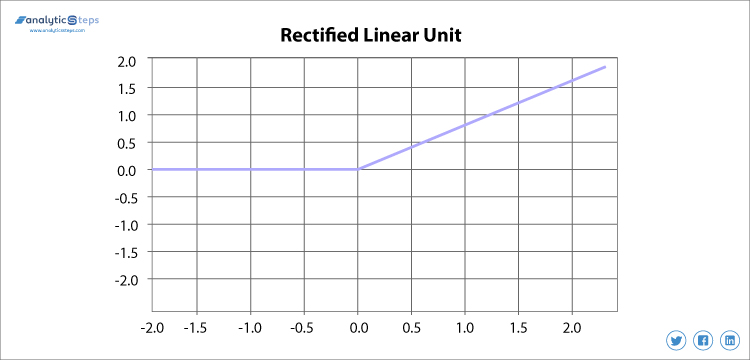
rektifierad linjär enhetsaktiveringsfunktion
vi använder läckande Relu-funktion istället för ReLU för att undvika detta olämpliga, i läckande Relu-intervall utökas vilket förbättrar prestanda.
läckande Relu-aktiveringsfunktion
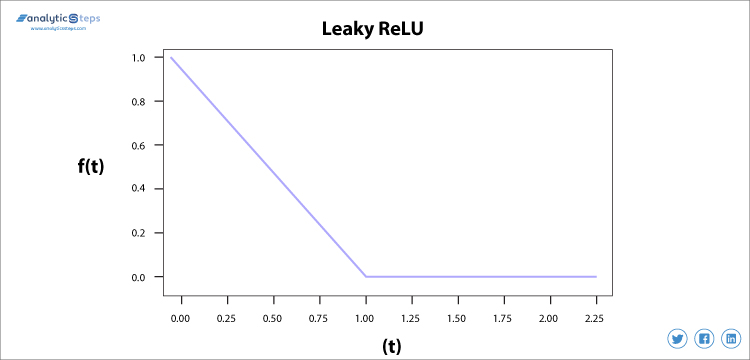
Leaky Relu aktiveringsfunktion
vi behövde den Leaky Relu aktiveringsfunktionen för att lösa problemet ”döende Relu”, som diskuteras i ReLU, observerar vi att alla negativa ingångsvärden blir noll mycket snabbt och i fallet med Leaky Relu gör vi inte alla negativa ingångar till noll utan till ett värde nära noll som löser huvudproblemet med Relu-aktiveringsfunktionen.
Sigmoidaktiveringsfunktion
sigmoidaktiveringsfunktionen används mest eftersom den gör sin uppgift med stor effektivitet, det är i grunden en probabilistisk inställning till beslutsfattande och varierar mellan 0 och 1, Så när vi måste fatta ett beslut eller förutsäga en utgång använder vi denna aktiveringsfunktion på grund av att intervallet är det minsta, därför skulle förutsägelsen vara mer exakt.
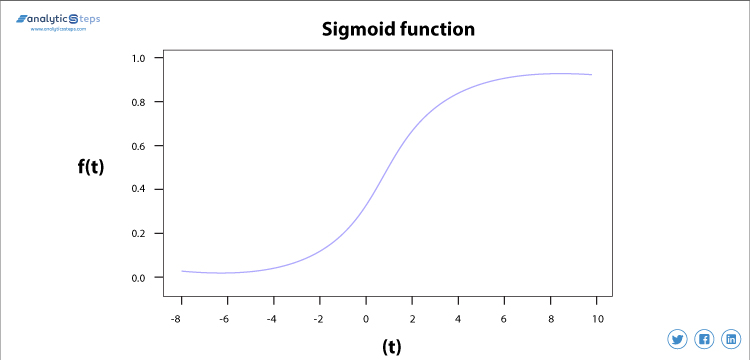
Sigmoidaktiveringsfunktion
ekvationen för sigmoidfunktionen är
f(x) = 1/(1+e(-x) )
Sigmoidfunktionen orsakar ett problem som huvudsakligen kallas försvinnande gradientproblem som uppstår eftersom vi konverterar stor ingång mellan intervallet 0 till 1 och därför blir deras derivat mycket mindre vilket inte ger tillfredsställande utgång. För att lösa detta problem används en annan aktiveringsfunktion som ReLU där vi inte har ett litet derivatproblem.
hyperbolisk Tangentaktiveringsfunktion(Tanh)
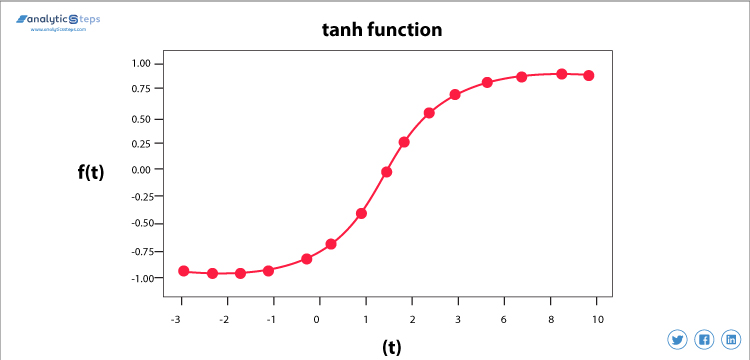
Tanh aktiveringsfunktion
denna aktiveringsfunktion är något bättre än sigmoidfunktionen, som sigmoidfunktionen används den också för att förutsäga eller skilja mellan två klasser men den kartlägger den negativa inmatningen endast i negativ kvantitet och varierar mellan -1 till 1.
Softmax aktiveringsfunktion
Softmax används huvudsakligen vid det sista lagret i.e utgångslager för att fatta samma beslut som sigmoidaktiveringsarbeten, softmax ger i princip värde till ingångsvariabeln beroende på deras vikt och summan av dessa vikter är så småningom en.
Softmax på binär klassificering
för binär klassificering, både sigmoid, liksom softmax, är lika lättillgänglig men i händelse av flera klass klassificeringsproblem använder vi i allmänhet softmax och cross-entropi tillsammans med det.
slutsats
aktiveringsfunktionerna är de signifikanta funktioner som utför en icke-linjär transformation till ingången och gör det skickligt att förstå och utföra mer komplexa uppgifter. Vi har diskuterat 7 majorly använda aktiveringsfunktioner med deras begränsning (om någon), dessa aktiveringsfunktioner används för samma ändamål men under olika förhållanden.