Vad är Förstärkningsinlärning?
Reinforcement Learning definieras som en Maskininlärningsmetod som handlar om hur mjukvaruagenter ska vidta åtgärder i en miljö. Förstärkningsinlärning är en del av den djupa inlärningsmetoden som hjälper dig att maximera en del av den kumulativa belöningen.
denna neurala nätverksinlärningsmetod hjälper dig att lära dig att uppnå ett komplext mål eller maximera en specifik dimension över många steg.
i Reinforcement Learning tutorial Lär du dig:
- Vad är Reinforcement Learning?
- viktiga termer som används i Deep Reinforcement Learning method
- hur fungerar Reinforcement Learning?
- Förstärkningsinlärningsalgoritmer
- egenskaper för Förstärkningsinlärning
- typer av Förstärkningsinlärning
- inlärningsmodeller för förstärkning
- Förstärkningsinlärning vs. övervakat lärande
- tillämpningar av Förstärkningsinlärning
- Varför använda Förstärkningsinlärning?
- När ska man inte använda Förstärkningsinlärning?
- utmaningar av förstärkning lärande
viktiga termer som används i djup förstärkning inlärningsmetod
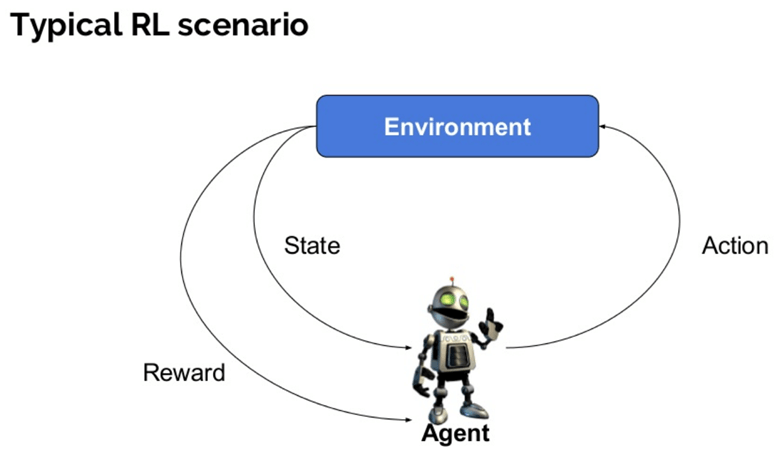
här är några viktiga termer som används i förstärkning AI:
- Agent: det är en antagen enhet som utför åtgärder i en miljö för att få lite belöning.
- miljö (e): ett scenario som en agent måste möta.
- belöning (R): En omedelbar återgång ges till en agent när han eller hon utför specifika åtgärder eller uppgift.
- stat (er): tillstånd hänvisar till den nuvarande situationen som returneras av miljön.
- Policy (?): Det är en strategi som gäller av agenten för att bestämma nästa åtgärd baserat på nuvarande tillstånd.
- värde (V): Det förväntas långsiktig avkastning med rabatt, jämfört med den kortsiktiga belöningen.
- Värdefunktion: den anger värdet på ett tillstånd som är den totala belöningen. Det är en agent som bör förväntas med början från den staten.
- Miljömodell: detta efterliknar miljöns beteende. Det hjälper dig att göra slutsatser som ska göras och också bestämma hur miljön ska bete sig.
- modellbaserade metoder: Det är en metod för att lösa förstärkningsinlärningsproblem som använder modellbaserade metoder.
- Q-värde eller åtgärdsvärde (Q): Q-värdet är ganska likt värdet. Den enda skillnaden mellan de två är att det tar en ytterligare parameter som en aktuell åtgärd.
hur fungerar Förstärkningsinlärning?
Låt oss se några enkla exempel som hjälper dig att illustrera förstärkningsinlärningsmekanismen.
Tänk på scenariot att lära ut nya knep till din katt
- eftersom cat inte förstår engelska eller något annat mänskligt språk kan vi inte berätta för henne direkt vad hon ska göra. Istället följer vi en annan strategi.
- vi efterliknar en situation, och katten försöker svara på många olika sätt. Om kattens svar är det önskade sättet, kommer vi att ge henne fisk.
- nu när katten utsätts för samma situation utför katten en liknande åtgärd med ännu mer entusiastiskt i väntan på att få mer belöning(mat).
- Det är som att lära sig att cat får från” vad man ska göra ” från positiva erfarenheter.
- samtidigt lär katten också vad som inte gör när man möter negativa upplevelser.
förklaring om exemplet:
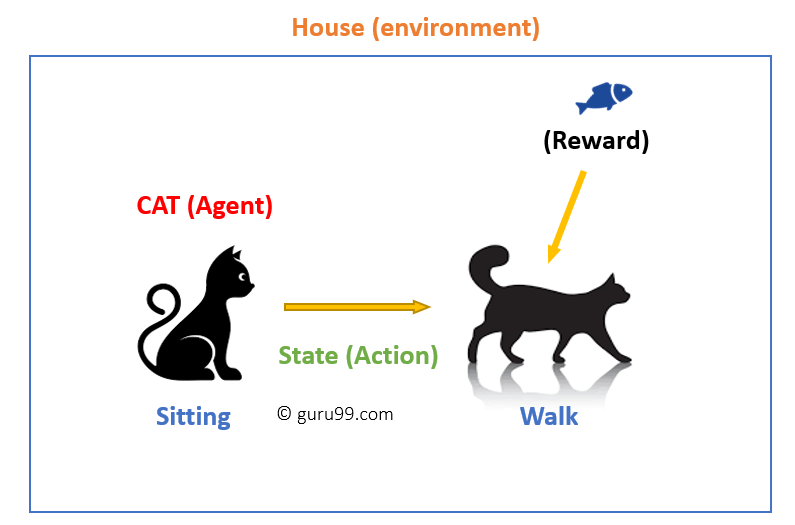
i detta fall
- din katt är en agent som utsätts för miljön. I det här fallet är det ditt hus. Ett exempel på ett tillstånd kan vara din katt sitter, och du använder ett specifikt ord för katt att gå.
- vår agent reagerar genom att utföra en åtgärdsövergång från ett ”tillstånd” till ett annat ”tillstånd.”
- till exempel går din katt från att sitta till att gå.
- reaktionen av ett medel är en åtgärd, och policyn är en metod för att välja en åtgärd som ges ett tillstånd i väntan på bättre resultat.
- efter övergången kan de få en belöning eller straff i gengäld.
Förstärkningsinlärningsalgoritmer
det finns tre metoder för att implementera en Förstärkningsinlärningsalgoritm.
värdebaserad:
i en värdebaserad Förstärkningsinlärningsmetod bör du försöka maximera en värdefunktion V (s). I den här metoden förväntar sig agenten en långsiktig avkastning av de nuvarande staterna enligt politiken ?.
policybaserad:
i en policybaserad rl-metod försöker du komma med en sådan policy att åtgärden som utförs i varje stat hjälper dig att få maximal belöning i framtiden.
två typer av policybaserade metoder är:
- deterministisk: för varje stat produceras samma åtgärd av policyn ?.
- stokastisk: varje åtgärd har en viss sannolikhet, som bestäms av följande ekvation.Stokastisk Policy:
n{a\s) = P\A, = a\S, =S]
modellbaserad:
i denna Förstärkningsinlärningsmetod måste du skapa en virtuell modell för varje miljö. Agenten lär sig att utföra i den specifika miljön.
egenskaper för Förstärkningsinlärning
här är viktiga egenskaper för förstärkningsinlärning
- Det finns ingen handledare, bara ett reellt tal eller belöningssignal
- sekventiellt beslutsfattande
- tid spelar en avgörande roll i Förstärkningsproblem
- Feedback är alltid försenad, inte momentan
- agentens åtgärder bestämmer de efterföljande data som den tar emot
typer av Förstärkningsinlärning
två typer av förstärkningsinlärningsmetoder är:
positiv:
det definieras som en händelse som uppstår på grund av specifikt beteende. Det ökar styrkan och frekvensen av beteendet och påverkar positivt på den åtgärd som agenten vidtar.
denna typ av förstärkning hjälper dig att maximera prestanda och upprätthålla förändring under en längre period. Men för mycket förstärkning kan leda till överoptimering av staten, vilket kan påverka resultaten.
negativ:
negativ förstärkning definieras som förstärkning av beteende som uppstår på grund av ett negativt tillstånd som borde ha stoppat eller undvikit. Det hjälper dig att definiera minsta prestanda. Nackdelen med denna metod är dock att den ger tillräckligt för att möta det minsta beteendet.
inlärningsmodeller av förstärkning
det finns två viktiga inlärningsmodeller i förstärkningsinlärning:
- Markov beslutsprocess
- Q lärande
Markov beslutsprocess
följande parametrar används för att få en lösning:
- uppsättning åtgärder – a
- uppsättning stater-S
- belöning – r
- Policy-n
- värde-V
den matematiska metoden för att kartlägga en lösning i förstärkningsinlärning är recon som en Markov beslutsprocess eller (MDP).
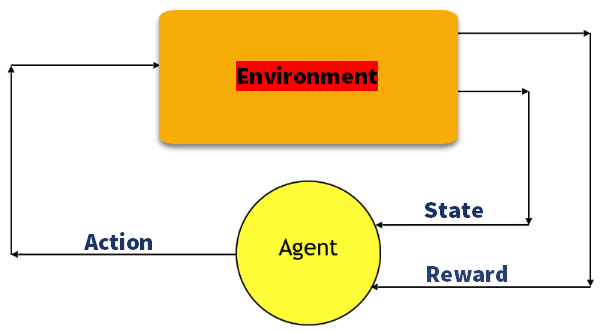
Q-Learning
Q learning är en värdebaserad metod för att tillhandahålla information för att informera vilken åtgärd en agent ska vidta.
låt oss förstå denna metod med följande exempel:
- Det finns fem rum i en byggnad som är anslutna med dörrar.
- varje rum är numrerat 0 till 4
- utsidan av byggnaden kan vara ett stort yttre område (5)
- dörrar nummer 1 och 4 leder in i byggnaden från rum 5
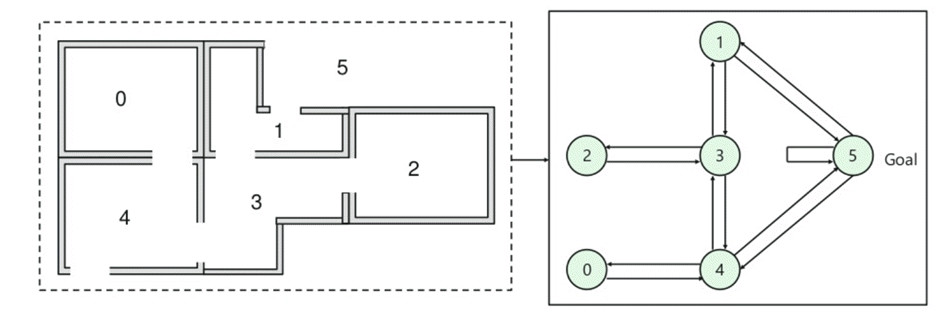
Därefter måste du associera ett belöningsvärde till varje dörr:
- dörrar som leder direkt till målet har en belöning på 100
- dörrar som inte är direkt anslutna till målrummet ger noll belöning
- eftersom dörrarna är tvåvägs och två pilar tilldelas för varje rum
- varje pil i bilden ovan innehåller ett omedelbart belöningsvärde
förklaring:
i den här bilden kan du se att rummet representerar ett tillstånd
agentens rörelse från ett rum till ett annat representerar en åtgärd
i den nedanstående bilden beskrivs ett tillstånd som en nod, medan pilarna visar åtgärden.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Övervakad inlärning
| parametrar | Förstärkningsinlärning | övervakad inlärning |
| Beslutsstil | förstärkningsinlärning hjälper dig att fatta dina beslut i följd. | i denna metod fattas ett beslut om inmatningen som ges i början. |
| fungerar på | fungerar på att interagera med miljön. | fungerar på exempel eller givna exempeldata. |
| beroende på beslut | i rl metod lärande beslut är beroende. Därför bör du ge etiketter till alla beroende beslut. | övervakade att lära sig de beslut som är oberoende av varandra, så etiketter ges för varje beslut. |
| bäst lämpad | stöder och fungerar bättre i AI, där mänsklig interaktion är utbredd. | det drivs mestadels med ett interaktivt mjukvarusystem eller applikationer. |
| exempel | schackspel | objektigenkänning |
tillämpningar av Förstärkningsinlärning
här är tillämpningar av Förstärkningsinlärning:
- robotik för industriell automation.
- affärsstrategi planering
- maskininlärning och databehandling
- Det hjälper dig att skapa utbildningssystem som ger anpassade instruktioner och material enligt kravet på studenter.
- flygplanskontroll och robotrörelsekontroll
varför använda Förstärkningsinlärning?
här är de främsta orsakerna till att använda Förstärkningsinlärning:
- Det hjälper dig att hitta vilken situation som behöver en åtgärd
- hjälper dig att upptäcka vilken åtgärd som ger den högsta belöningen under den längre perioden.
- Reinforcement Learning ger också inlärningsagenten en belöningsfunktion.
- Det gör det också möjligt att räkna ut den bästa metoden för att få stora belöningar.
När ska man inte använda Förstärkningsinlärning?
Du kan inte tillämpa förstärkningsinlärningsmodell är hela situationen. Här är några villkor när du inte ska använda reinforcement learning model.
- när du har tillräckligt med data för att lösa problemet med en övervakad inlärningsmetod
- måste du komma ihåg att Förstärkningsinlärning är datortungt och tidskrävande. särskilt när handlingsutrymmet är stort.
utmaningar för Förstärkningsinlärning
Här är de stora utmaningarna du kommer att möta när du tjänar förstärkning:
- funktion/belöningsdesign som borde vara mycket involverad
- parametrar kan påverka inlärningshastigheten.
- realistiska miljöer kan ha partiell observerbarhet.
- för mycket förstärkning kan leda till en överbelastning av tillstånd som kan minska resultaten.
- realistiska miljöer kan vara icke-stationära.
sammanfattning:
- Reinforcement Learning är en Maskininlärningsmetod
- hjälper dig att upptäcka vilken åtgärd som ger den högsta belöningen under den längre perioden.
- tre metoder för förstärkningsinlärning är 1) värdebaserad 2) policybaserad och modellbaserad inlärning.
- Agent, stat, belöning, miljö, Värdefunktionsmodell för miljön, modellbaserade metoder, är några viktiga termer som använder i rl-inlärningsmetod
- exemplet med förstärkningsinlärning är att din katt är en agent som utsätts för miljön.
- det största kännetecknet för denna metod är att det inte finns någon handledare, bara ett reellt tal eller belöningssignal
- två typer av förstärkningsinlärning är 1) positiv 2) negativ
- två allmänt använda inlärningsmodeller är 1) Markov beslutsprocess 2) Q-lärande
- Förstärkningsinlärningsmetod fungerar på att interagera med miljön, medan den övervakade inlärningsmetoden fungerar på givna provdata eller exempel.
- användnings-eller förstärkningsinlärningsmetoder är: Robotics för industriell automation och affärsstrategi planering
- Du bör inte använda den här metoden när du har tillräckligt med data för att lösa problemet
- den största utmaningen med denna metod är att parametrar kan påverka hastigheten på lärande