Hej och välkommen till en illustrerad Guide till långt korttidsminne (LSTM) och Gated recurrent units (gru). Jag är Michael, och jag är Maskininlärningsingenjör i ai-röstassistentutrymmet.
i det här inlägget börjar vi med intuitionen bakom LSTM: s och GRU: s. då ska jag förklara de interna mekanismerna som gör att LSTM: s och GRU: s kan fungera så bra. Om du vill förstå vad som händer under huven för dessa två nätverk, så är det här inlägget för dig.
Du kan också titta på videoversionen av det här inlägget på youtube om du föredrar det.
återkommande neurala nätverk lider av korttidsminne. Om en sekvens är tillräckligt lång kommer de att ha svårt att bära information från tidigare tidssteg till senare. Så om du försöker bearbeta ett stycke text för att göra förutsägelser kan RNN: s lämna viktig information från början.
under ryggutbredning lider återkommande neurala nätverk av det försvinnande gradientproblemet. Gradienter är värden som används för att uppdatera ett neuralt nätverk vikter. Det försvinnande gradientproblemet är när gradienten krymper när den sprids tillbaka genom tiden. Om ett gradientvärde blir extremt litet bidrar det inte till för mycket lärande.

så i återkommande neurala nätverk slutar lager som får en liten gradientuppdatering att lära sig. De är vanligtvis de tidigare lagren. Så eftersom dessa lager Inte lär sig kan RNN glömma vad det sett i längre sekvenser och därmed ha ett korttidsminne. Om du vill veta mer om mekaniken i återkommande neurala nätverk i allmänhet kan du läsa mitt tidigare inlägg här.
LSTM: s och GRU: s som en lösning
LSTM: s och GRU: s skapades som lösningen på korttidsminnet. De har interna mekanismer som kallas grindar som kan reglera informationsflödet.

dessa portar kan lära sig vilka data i en sekvens som är viktiga att behålla eller kasta bort. Genom att göra det kan den skicka relevant information ner i den långa kedjan av sekvenser för att göra förutsägelser. Nästan alla toppmoderna resultat baserade på återkommande neurala nätverk uppnås med dessa två nätverk. LSTM och GRU finns i taligenkänning, talsyntes och textgenerering. Du kan till och med använda dem för att skapa bildtexter för videor.
Ok, så i slutet av det här inlägget bör du ha en solid förståelse för varför LSTM och GRU är bra på att bearbeta långa sekvenser. Jag kommer att närma mig detta med intuitiva förklaringar och illustrationer och undvika så mycket matematik som möjligt.
Intuition
Ok, låt oss börja med ett tankeexperiment. Låt oss säga att du tittar på recensioner online för att avgöra om du vill köpa Life cereal (fråga mig inte varför). Du läser först recensionen och bestämmer sedan om någon tyckte att det var bra eller om det var dåligt.

När du läser recensionen kommer din hjärna omedvetet bara ihåg viktiga nyckelord. Du plockar upp ord som” fantastisk ”och”perfekt balanserad frukost”. Du bryr dig inte mycket om ord som ”detta”, ”gav”, ”allt”, ”borde”, etc. Om en vän frågar dig nästa dag vad översynen sa, skulle du förmodligen inte komma ihåg det ord för ord. Du kanske kommer ihåg de viktigaste punkterna men som ”kommer definitivt att köpa igen”. Om du är mycket som jag, kommer de andra orden att blekna bort från minnet.

och det är i huvudsak vad en LSTM eller gru gör. Det kan lära sig att bara behålla relevant information för att göra förutsägelser och glömma icke relevanta data. I det här fallet fick de ord du kom ihåg att du dömde att det var bra.
granskning av återkommande neurala nätverk
för att förstå hur LSTM eller GRU uppnår detta, låt oss granska det återkommande neurala nätverket. En RNN fungerar så här; första orden omvandlas till maskinläsbara vektorer. Sedan bearbetar RNN sekvensen av vektorer en efter en.

under bearbetningen passerar det tidigare dolda tillståndet till nästa steg i sekvensen. Det dolda tillståndet fungerar som neurala nätverksminne. Den innehåller information om tidigare data som nätverket har sett tidigare.

nästa gång steg
låt oss titta på en cell i RNN för att se hur du skulle beräkna det dolda tillståndet. Först kombineras ingången och det tidigare dolda tillståndet för att bilda en vektor. Den vektorn har nu information om aktuell ingång och tidigare ingångar. Vektorn går igenom tanh-aktiveringen, och utgången är det nya dolda tillståndet eller nätverkets minne.

tanh-aktivering
tanh-aktiveringen används för att reglera värdena som flyter genom nätverket. Tanh-funktionen squishes värden för att alltid vara mellan -1 och 1.

När vektorer strömmar genom ett neuralt nätverk genomgår det många omvandlingar på grund av olika matematiska operationer. Så föreställ dig ett värde som fortsätter att multipliceras med låt oss säga 3. Du kan se hur vissa värden kan explodera och bli astronomiska, vilket gör att andra värden verkar obetydliga.

vektortransformationer utan tanh
en tanh-funktion säkerställer att värdena stannar mellan -1 och 1, vilket reglerar utgången från det neurala nätverket. Du kan se hur samma värden ovanifrån förblir mellan gränserna som tillåts av tanh-funktionen.

så det är en RNN. Det har väldigt få operationer internt men fungerar ganska bra med rätt omständigheter (som korta sekvenser). RNN använder mycket mindre beräkningsresurser än de utvecklade varianterna, LSTM och GRU.
LSTM
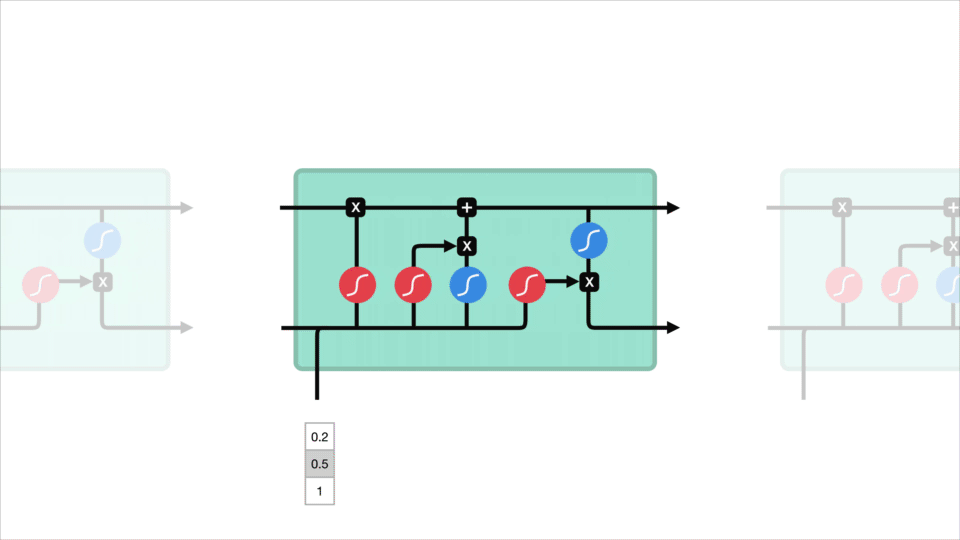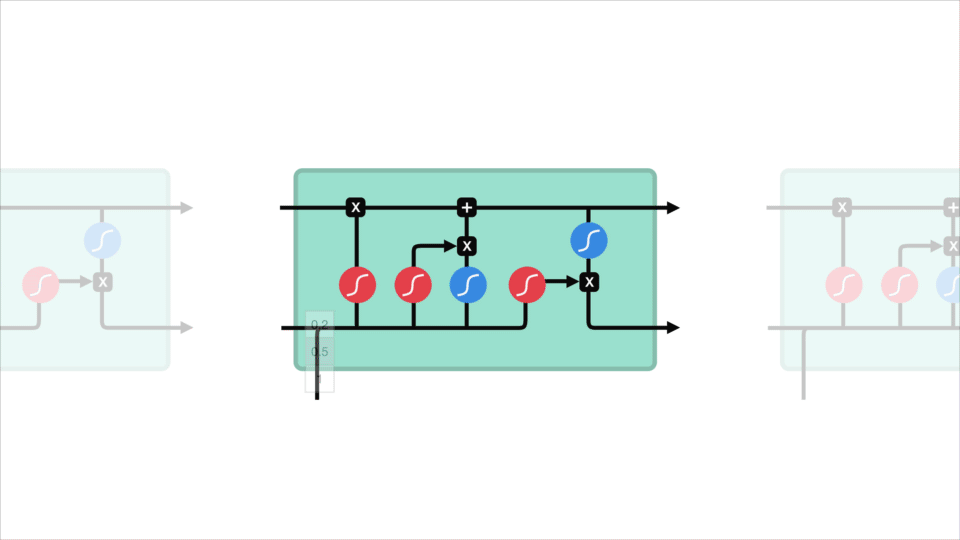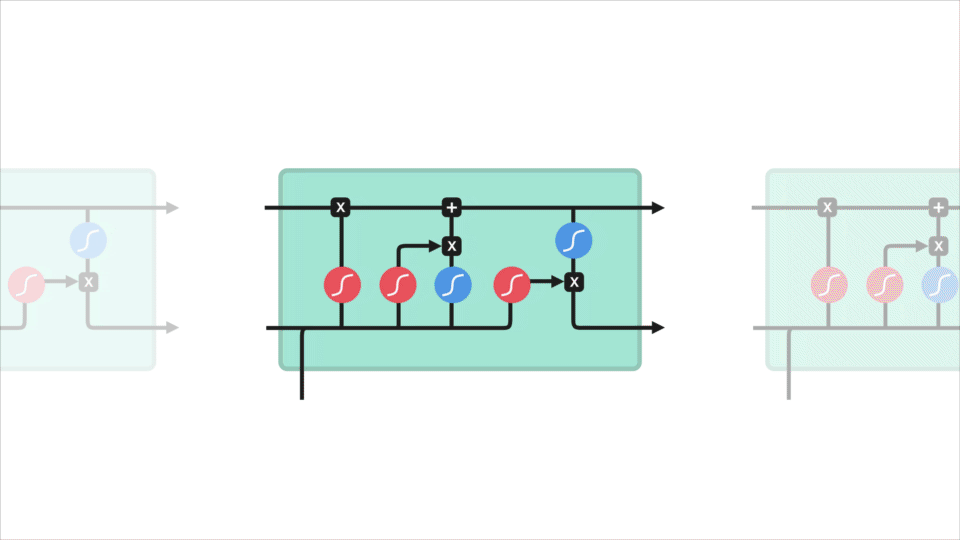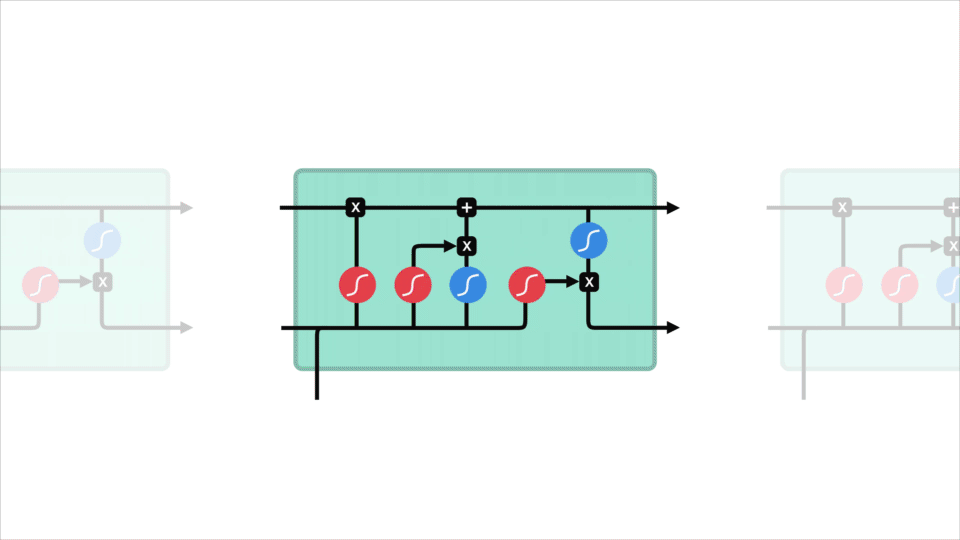
en LSTM har ett liknande kontrollflöde som ett återkommande neuralt nätverk. Den bearbetar data som överför information när den sprids framåt. Skillnaderna är operationerna inom LSTM: s celler.

LSTM Cell och It
dessa operationer används för att låta LSTM behålla eller glömma information. Att titta på dessa operationer kan bli lite överväldigande så vi går igenom detta steg för steg.
kärnkoncept
kärnkonceptet för LSTM är celltillståndet, och det är olika grindar. Celltillståndet fungerar som en transportväg som överför relativ information hela vägen ner i sekvenskedjan. Du kan tänka på det som” minnet ” i nätverket. Celltillståndet kan i teorin bära relevant information under hela behandlingen av sekvensen. Så även information från tidigare tidssteg kan göra det till senare tidssteg, vilket minskar effekterna av korttidsminnet. När celltillståndet går på sin resa, får information läggas till eller tas bort till celltillståndet via grindar. Portarna är olika neurala nätverk som bestämmer vilken information som är tillåten på celltillståndet. Portarna kan lära sig vilken information som är relevant att behålla eller glömma under träningen.
sigmoid
Gates innehåller sigmoidaktiveringar. En sigmoidaktivering liknar tanh-aktiveringen. Istället för att mosa värden mellan -1 och 1, Det mosar värden mellan 0 och 1. Det är bra att uppdatera eller glömma data eftersom ett tal som multipliceras med 0 är 0, vilket gör att värden försvinner eller blir ”glömda.”Vilket tal som helst multiplicerat med 1 är samma värde, därför är värdet detsamma eller” hålls.”Nätverket kan lära sig vilka data som inte är viktiga därför kan glömmas bort eller vilka data som är viktiga att behålla.

Sigmoid squishes värden för att vara mellan 0 och 1
låt oss gräva lite djupare i vad de olika grindarna gör, ska vi? Så vi har tre olika grindar som reglerar informationsflödet i en LSTM-cell. En glömma Grind, ingångsgrind och utgångsgrind.
glöm gate
först har vi glömma gate. Denna Grind bestämmer vilken information som ska kastas eller hållas. Information från det tidigare dolda tillståndet och information från den aktuella ingången passerar genom sigmoid-funktionen. Värden kommer ut mellan 0 och 1. Ju närmare 0 betyder att glömma, och ju närmare 1 betyder att hålla.

/ figcaption >
ingångsgrind
för att uppdatera celltillståndet har vi ingångsgrinden. Först passerar vi det tidigare dolda tillståndet och nuvarande ingången till en sigmoid-funktion. Det bestämmer vilka värden som ska uppdateras genom att omvandla värdena till mellan 0 och 1. 0 betyder inte viktigt, och 1 betyder viktigt. Du skickar också det dolda tillståndet och nuvarande ingången till tanh-funktionen för att klämma in värden mellan -1 och 1 för att hjälpa till att reglera nätverket. Sedan multiplicerar du tanh-utgången med sigmoid-utgången. Sigmoid-utgången bestämmer vilken information som är viktig att hålla från tanh-utgången.

celltillstånd
nu ska vi ha tillräckligt med information för att beräkna celltillståndet. Först blir celltillståndet punktvis multiplicerat med glömvektorn. Detta har en möjlighet att släppa värden i celltillståndet om det multipliceras med värden nära 0. Sedan tar vi utmatningen från ingångsporten och gör ett punktvis tillägg som uppdaterar celltillståndet till nya värden som det neurala nätverket finner relevant. Det ger oss vårt nya celltillstånd.

utgångsgrind
senast har vi utgångsgrinden. Utgångsporten bestämmer vad nästa dolda tillstånd ska vara. Kom ihåg att det dolda tillståndet innehåller information om tidigare ingångar. Det dolda tillståndet används också för förutsägelser. Först passerar vi det tidigare dolda tillståndet och den aktuella ingången till en sigmoid-funktion. Sedan skickar vi det nyligen modifierade celltillståndet till tanh-funktionen. Vi multiplicerar tanh-utgången med sigmoid-utgången för att bestämma vilken information det dolda tillståndet ska bära. Utgången är det dolda tillståndet. Det nya celltillståndet och det nya dolda överförs sedan till nästa steg.

för att granska bestämmer glömporten vad som är relevant att behålla från tidigare steg. Ingångsgrinden bestämmer vilken information som är relevant att lägga till från det aktuella steget. Utgångsporten bestämmer vad nästa dolda tillstånd ska vara.
Code Demo
för dig som förstår bättre genom att se koden, här är ett exempel med python pseudokod.

1. Först sammanfogas det tidigare dolda tillståndet och den aktuella ingången. Vi kallar det combine.
2. Kombinera get matas in i glömma lagret. Detta lager tar bort icke-relevanta data.
4. Ett kandidatlager skapas med hjälp av kombinera. Kandidaten har Möjliga värden att lägga till i celltillståndet.
3. Kombinera får också matas in i ingångsskiktet. Detta lager bestämmer vilka data från kandidaten som ska läggas till i det nya celltillståndet.
5. Efter beräkning av glömskiktet, kandidatskiktet och ingångsskiktet beräknas celltillståndet med hjälp av dessa vektorer och föregående celltillstånd.
6. Utgången beräknas sedan.
7. Punktvis multiplicera utgången och det nya celltillståndet ger oss det nya dolda tillståndet.
det är det! Styrflödet för ett LSTM-nätverk är några tensoroperationer och en för slinga. Du kan använda de dolda staterna för förutsägelser. Genom att kombinera alla dessa mekanismer kan en LSTM välja vilken information som är relevant att komma ihåg eller glömma under sekvensbearbetning.
GRU
så nu vet vi hur en LSTM fungerar, låt oss kortfattat titta på GRU. GRU är den nyare generationen av återkommande neurala nätverk och är ganska lik en LSTM. GRU blev av med celltillståndet och använde det dolda tillståndet för att överföra information. Den har också bara två grindar, en återställningsport och uppdateringsport.

uppdateringsgrind
uppdateringsgrinden fungerar på samma sätt som glöm-och ingångsgrinden för en LSTM. Den bestämmer vilken information som ska kastas och vilken ny information som ska läggas till.
Reset Gate
reset gate är en annan Grind används för att bestämma hur mycket tidigare information att glömma.
och det är en GRU. GRU ’ s har färre tensor-operationer; därför är de lite snabbare att träna sedan LSTM: s. det finns ingen klar vinnare vilken som är bättre. Forskare och ingenjörer försöker vanligtvis både bestämma vilken som fungerar bättre för deras användningsfall.
så det är det
för att sammanfatta detta är RNN: er bra för att bearbeta sekvensdata för förutsägelser men lider av korttidsminne. LSTM och GRU skapades som en metod för att mildra korttidsminnet med hjälp av mekanismer som kallas grindar. Gates är bara neurala nätverk som reglerar informationsflödet som strömmar genom sekvenskedjan. LSTM och GRU används i toppmoderna djupa inlärningsapplikationer som taligenkänning, talsyntes, naturlig språkförståelse etc.
Om du är intresserad av att gå djupare, här är länkar till några fantastiska resurser som kan ge dig ett annat perspektiv för att förstå LSTM: s och GRU: s. detta inlägg var starkt inspirerat av dem.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/