av William W Wold
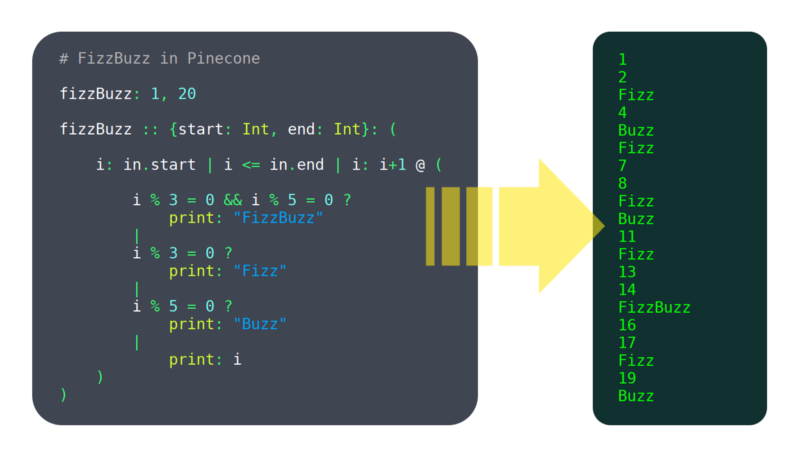
under de senaste 6 månaderna har jag arbetat med ett programmeringsspråk som heter Pinecone. Jag skulle inte kalla det moget ännu, men det har redan tillräckligt med funktioner som fungerar för att vara användbara, till exempel:
- variabler
- funktioner
- användardefinierade strukturer
om du är intresserad av det, kolla in pinecones målsida eller dess GitHub repo.
Jag är ingen expert. När jag startade det här projektet hade jag ingen aning om vad jag gjorde, och det gör jag fortfarande inte. jag har tagit nollkurser om språkskapande, läst bara lite om det online och följde inte mycket av de råd jag har fått.
och ändå gjorde jag fortfarande ett helt nytt språk. Och det fungerar. Så jag måste göra något rätt.
i det här inlägget ska jag dyka under huven och visa dig pipeline Pinecone (och andra programmeringsspråk) för att göra källkoden till magi.
Jag kommer också att beröra några av de avvägningar jag har gjort, och varför jag fattade de beslut jag gjorde.
det här är inte alls en komplett handledning om att skriva ett programmeringsspråk, men det är en bra utgångspunkt om du är nyfiken på språkutveckling.
komma igång
”Jag har absolut ingen aning om var jag ens skulle börja” är något jag hör mycket när jag berättar för andra utvecklare att jag skriver ett språk. Om det är din reaktion, ska jag nu gå igenom några inledande beslut som fattas och steg som tas när du startar något nytt språk.
kompilerad vs tolkad
det finns två huvudtyper av språk: kompilerad och tolkad:
- en kompilator räknar ut allt ett program kommer att göra, förvandlar det till ”maskinkod” (ett format som datorn kan köra riktigt snabbt) och sparar sedan det som ska köras senare.
- en tolk går igenom källkoden rad för rad och räknar ut vad den gör som den går.
tekniskt sett kan alla språk sammanställas eller tolkas, men det ena eller det andra brukar vara mer meningsfullt för ett visst språk. I allmänhet tenderar tolkning att vara mer flexibel, medan sammanställning tenderar att ha högre prestanda. Men det här är bara att skrapa ytan på ett mycket komplext ämne.
jag värdesätter prestanda, och jag såg brist på programmeringsspråk som är både högpresterande och enkelhetsorienterade, så jag gick med kompilerad för Pinecone.
detta var ett viktigt beslut att fatta tidigt, eftersom många språkdesignbeslut påverkas av det (till exempel är statisk typning en stor fördel för kompilerade språk, men inte så mycket för tolkade).
trots att Pinecone designades med kompilering i åtanke, har den en fullt fungerande tolk som var det enda sättet att köra det ett tag. Det finns ett antal skäl till detta, som jag kommer att förklara senare.
välja ett språk
Jag vet att det är lite meta, men ett programmeringsspråk är i sig ett program, och därför måste du skriva det på ett språk. Jag valde C++ på grund av dess prestanda och stora funktioner. Dessutom tycker jag faktiskt om att arbeta i C++.
om du skriver ett tolkat språk är det mycket meningsfullt att skriva det i en sammanställd (som C, C++ eller Swift) eftersom prestandan som förloras på tolkens språk och tolken som tolkar din tolk kommer att bli sammansatt.
om du planerar att kompilera är ett långsammare språk (som Python eller JavaScript) mer acceptabelt. Kompileringstiden kan vara dålig, men enligt min mening är det inte så stort som en dålig körtid.
Högnivådesign
ett programmeringsspråk är generellt strukturerat som en pipeline. Det vill säga det har flera steg. Varje steg har data formaterade på ett specifikt, väldefinierat sätt. Det har också funktioner för att omvandla data från varje steg till nästa.
det första steget är en sträng som innehåller hela inmatningskällfilen. Det sista steget är något som kan köras. Allt detta kommer att bli tydligt när vi går igenom Pinecone-rörledningen steg för steg.
Lexing

det första steget i de flesta programmeringsspråk är lexing eller tokenizing. ’Lex’ är kort för lexical analysis, ett mycket fint ord för att dela upp en massa text i tokens. Ordet ’tokenizer’ ger mycket mer mening, men’ lexer ’ är så roligt att säga att jag använder det ändå.
Tokens
en token är en liten enhet i ett språk. En token kan vara en variabel eller funktionsnamn (AKA en identifierare), en operatör eller ett nummer.
uppgift för Lexer
lexer ska ta in en sträng som innehåller en hel fil värd källkod och spotta ut en lista som innehåller varje token.
framtida stadier av rörledningen kommer inte att hänvisa till den ursprungliga källkoden, så lexer måste producera all information som behövs av dem. Anledningen till detta relativt strikta rörledningsformat är att lexer kan göra uppgifter som att ta bort kommentarer eller upptäcka om något är ett nummer eller en identifierare. Du vill hålla den logiken låst inuti lexern, båda så att du inte behöver tänka på dessa regler när du skriver resten av språket, och så kan du ändra denna typ av syntax på ett ställe.
Flex
dagen jag började språket var det första jag skrev en enkel lexer. Strax efter började jag lära mig om verktyg som förmodligen skulle göra lexing enklare och mindre buggy.
det dominerande verktyget är Flex, ett program som genererar lexers. Du ger den en fil som har en speciell syntax för att beskriva språkets grammatik. Från det genererar det ett C-program som leder en sträng och producerar önskad utgång.
mitt beslut
Jag valde att behålla lexer jag skrev för tillfället. Till slut såg jag inte betydande fördelar med att använda Flex, åtminstone inte tillräckligt för att motivera att lägga till ett beroende och komplicera byggprocessen.
min lexer är bara några hundra rader lång och ger mig sällan några problem. Att rulla min egen lexer ger mig också mer flexibilitet, till exempel möjligheten att lägga till en operatör på språket utan att redigera flera filer.
Parsing

det andra steget i rörledningen är parsern. Parsern förvandlar en lista med tokens till ett träd av noder. Ett träd som används för att lagra denna typ av data kallas ett abstrakt syntaxträd eller AST. Åtminstone i Pinecone har AST ingen information om typer eller vilka identifierare som är vilka. Det är helt enkelt strukturerade tokens.
Parser tullar
parsern lägger till struktur till den beställda listan över tokens som lexer producerar. För att stoppa tvetydigheter måste parsern ta hänsyn till parentes och ordningsföljd. Att bara analysera operatörer är inte särskilt svårt, men eftersom fler språkkonstruktioner läggs till kan parsning bli mycket komplex.
Bison
återigen var det ett beslut att göra med ett tredjepartsbibliotek. Det dominerande analysbiblioteket är Bison. Bison fungerar mycket som Flex. Du skriver en fil i ett anpassat format som lagrar grammatikinformationen, sedan använder Bison det för att generera ett C-program som gör din tolkning. Jag valde inte att använda Bison.
varför Anpassad är bättre
med lexer var beslutet att använda min egen kod ganska uppenbart. En lexer är en sådan trivial program som inte skriva min egen kändes nästan lika dumt som att inte skriva min egen ’vänster-pad’.
med parsern är det en annan sak. Min Pinecone parser är för närvarande 750 rader lång, och jag har skrivit tre av dem eftersom de två första var skräp.
jag fattade ursprungligen mitt beslut av ett antal skäl, och även om det inte har gått helt smidigt, håller de flesta av dem sanna. De viktigaste är följande:
- minimera kontextbyte i arbetsflöde: kontextväxling mellan C++ och Pinecone är illa nog utan att kasta in Bisons grammatik grammatik
- Håll Bygg enkelt: Varje gång grammatiken ändras måste Bison köras före byggnaden. Detta kan automatiseras men det blir en smärta när man växlar mellan byggsystem.
- jag gillar att bygga cool skit: jag gjorde inte Pinecone eftersom jag trodde att det skulle vara lätt, så varför skulle jag delegera en central roll när jag kunde göra det själv? En anpassad parser kanske inte är trivial, men den är helt genomförbar.
i början var jag inte helt säker på om jag gick ner på en livskraftig väg, men jag fick förtroende för vad Walter Bright (en utvecklare på en tidig version av C++ och skaparen av D-språket) hade att säga om ämnet:
”något mer kontroversiellt, jag skulle inte bry mig om att slösa tid med lexer-eller parsergeneratorer och andra så kallade” kompilatorkompilatorer.”De är slöseri med tid. Att skriva en lexer och parser är en liten andel av jobbet med att skriva en kompilator. Att använda en generator tar ungefär lika mycket tid som att skriva en för hand, och det kommer att gifta dig med generatorn (vilket är viktigt när du överför kompilatorn till en ny plattform). Och generatorer har också det olyckliga rykte att avge elaka felmeddelanden.”
Action Tree
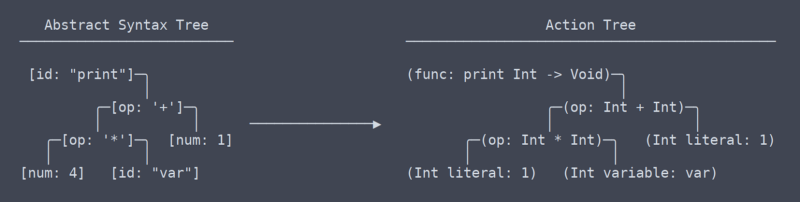
Vi har nu lämnat området med vanliga, universella termer, eller åtminstone vet jag inte vad villkoren är längre. Från min förståelse, vad jag kallar ’action tree’ är mest besläktad med LLVM: s IR (intermediate representation).
det finns en subtil men väldigt signifikant skillnad mellan åtgärdsträdet och det abstrakta syntaxträdet. Det tog mig ett tag att räkna ut att det ens skulle vara en skillnad mellan dem (vilket bidrog till behovet av omskrivningar av parsern).
Action Tree vs AST
enkelt uttryckt är åtgärdsträdet AST med sammanhang. Det sammanhanget är information som vilken typ en funktion returnerar, eller att två platser där en variabel används faktiskt använder samma variabel. Eftersom det måste räkna ut och komma ihåg allt detta sammanhang behöver koden som genererar åtgärdsträdet massor av namnrymdstabeller och andra thingamabobs.
kör Åtgärdsträdet
När vi har åtgärdsträdet är det enkelt att köra koden. Varje åtgärdsnod har en funktion ’execute’ som tar lite inmatning, gör vad åtgärden ska (inklusive eventuellt anropande underåtgärd) och returnerar åtgärdens utgång. Detta är tolken i aktion.
Kompileringsalternativ
” men vänta!”Jag hör dig säga,” är inte Pinecone tänkt att sammanställas?”Ja, det är det. Men att sammanställa är svårare än att tolka. Det finns några möjliga tillvägagångssätt.
Bygg min egen kompilator
det här lät som en bra ide för mig först. Jag älskar att göra saker själv, och jag har klåda för en ursäkt för att bli bra på montering.
tyvärr är det inte så lätt att skriva en bärbar kompilator som att skriva någon maskinkod för varje språkelement. På grund av antalet arkitekturer och operativsystem är det opraktiskt för varje individ att skriva en cross platform compiler backend.
även lagen bakom Swift, Rust och Clang vill inte bry sig om allt på egen hand, så istället använder de alla…
LLVM
LLVM är en samling kompilatorverktyg. Det är i grunden ett bibliotek som gör ditt språk till en kompilerad körbar binär. Det verkade som det perfekta valet, så jag hoppade rätt in. Tyvärr kollade jag inte hur djupt vattnet var och jag drunknade omedelbart.
LLVM, även om det inte är monteringsspråk hårt, är gigantiskt komplext bibliotek hårt. Det är inte omöjligt att använda, och de har bra handledning, men jag insåg att jag skulle behöva träna innan jag var redo att fullt ut implementera en Pinecone-kompilator med den.
Transpiling
Jag ville ha någon form av kompilerad Pinecone och jag ville ha det snabbt, så jag vände mig till en metod som jag visste att jag kunde göra arbete: transpiling.
jag skrev en Pinecone till C++ transpiler och lade till möjligheten att automatiskt kompilera utgångskällan med GCC. Detta fungerar för närvarande för nästan alla Pinecone-program (även om det finns några kantfall som bryter det). Det är inte en särskilt bärbar eller skalbar lösning, men den fungerar för tillfället.
Future
förutsatt att jag fortsätter att utveckla Pinecone, kommer det att få LLVM-kompileringsstöd förr eller senare. Jag misstänker ingen mater hur mycket jag arbetar på det, transpiler kommer aldrig att vara helt stabil och fördelarna med LLVM är många. Det handlar bara om när jag har tid att göra några provprojekt i LLVM och få tag på det.
fram till dess är tolken bra för triviala program och C++ transpiling fungerar för de flesta saker som behöver mer prestanda.
slutsats
Jag hoppas att jag har gjort programmeringsspråk lite mindre mystiska för dig. Om du vill göra en själv, rekommenderar jag det starkt. Det finns massor av implementeringsdetaljer att räkna ut men konturen här borde räcka för att komma igång.
här är mitt råd på hög nivå för att komma igång (kom ihåg, Jag vet inte riktigt vad jag gör, så ta det med ett saltkorn):
- Om du är osäker, gå tolkad. Tolkade språk är i allmänhet enklare design, bygga och lära. Jag avskräcker dig inte från att skriva en sammanställd om du vet att det är vad du vill göra, men om du är på staketet skulle jag tolkas.
- när det gäller lexers och parsers, gör vad du vill. Det finns giltiga argument för och emot att skriva egna. I slutändan, om du tänker på din design och implementerar allt på ett förnuftigt sätt, spelar det ingen roll.
- lär dig av den pipeline jag slutade med. En hel del trial and error gick in utforma pipeline jag har nu. Jag har försökt eliminera ASTs, ASTs som förvandlas till åtgärder träd på plats, och andra fruktansvärda ideer. Den här rörledningen fungerar, så ändra inte den om du inte har en riktigt bra ide.
- Om du inte har tid eller motivation att implementera ett komplext Allmänt Språk, försök att implementera ett esoteriskt språk som Brainfuck. Dessa tolkar kan vara så korta som några hundra rader.
Jag har väldigt få beklagar när det gäller Pinecone utveckling. Jag gjorde ett antal dåliga val på vägen, men jag har skrivit om det mesta av koden som drabbats av sådana misstag.
just nu är Pinecone i ett tillräckligt bra tillstånd att det fungerar bra och lätt kan förbättras. Att skriva Pinecone har varit en enormt pedagogisk och trevlig upplevelse för mig, och det har precis börjat.