versionsinformation: kod för denna sida testades i Stata 12.
Poisson regression används för att modellera räkna variabler.
Observera: syftet med denna sida är att visa hur man använder olika dataanalyskommandon. Det täcker inte alla aspekter av forskningsprocessen som forskare förväntas göra. I synnerhet omfattar det inte datarengöring och kontroll, verifiering av antaganden, modelldiagnostik eller potentiella uppföljningsanalyser.
exempel på Poisson regression
exempel 1. Antalet personer som dödats av mule eller häst sparkar i preussiska armen per år.Ladislaus Bortkiewicz samlade in data från 20 volymer av preussischen Statistik. Dessa uppgifter samlades in på 10 corps of the Preussian army i slutet av 1800-talet under 20 år.
exempel 2. Antalet personer i linje framför dig i mataffären. Prediktorer kan inkludera antalet artiklar som för närvarande erbjuds till ett speciellt rabatterat pris och om en speciell händelse (t.ex. en semester, ett stort sportevenemang) är tre eller färre dagar bort.
exempel 3. Antalet utmärkelser som tjänats av studenter på en gymnasium. Prediktorer för antalet intjänade utmärkelser inkluderar den typ av program där studenten var inskriven (t.ex. yrkesmässig, allmän eller akademisk) och poängen på deras slutprov i matematik.
beskrivning av data
för illustrationen har vi simulerat en datamängd till exempel 3 ovan. I det här exemplet är num_awards resultatvariabeln och anger antalet utmärkelser som elever på en gymnasium får på ett år, matematik är en kontinuerlig prediktorvariabel och representerar elevernas poäng på deras matematiska slutprov och prog är en kategorisk prediktorvariabel med tre nivåer som indikerar vilken typ av program eleverna var inskrivna i.
Låt oss börja med att ladda data och titta på några beskrivande statistik.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
varje variabel har 200 giltiga observationer och deras fördelningar verkar ganska rimliga. I detta är det ovillkorliga medelvärdet och variansen för vår resultatvariabel inte extremt annorlunda.
Låt oss fortsätta med vår beskrivning av variablerna i denna dataset. Tabellen nedan visar det genomsnittliga antalet utmärkelser per programtyp och verkar föreslå att programtyp är en bra kandidat för att förutsäga antalet utmärkelser, vår resultatvariabel, eftersom medelvärdet av resultatet verkar variera med prog.
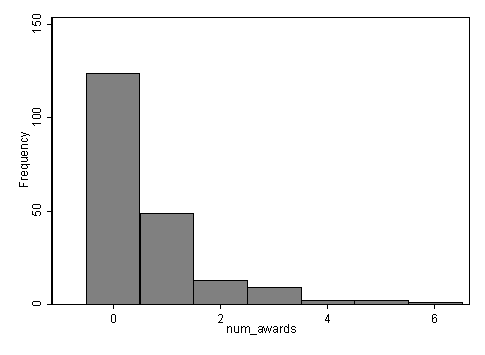
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
analysmetoder du kan överväga
nedan är en lista över några analysmetoder som du kan ha stött på. Några av de angivna metoderna är ganska rimliga, medan andra antingen har fallit i favör eller har begränsningar.
- Poisson regression-Poisson regression används ofta för modellering av räkningsdata. Poisson regression har ett antal tillägg som är användbara för räknemodeller.
- negativ binomial regression-negativ binomial regression kan användas för överdispergerade räkningsdata, det vill säga när den villkorliga variansen överstiger det villkorliga medelvärdet. Det kan betraktas som en generalisering av Poisson-regression eftersom den har samma medelstruktur som Poisson-regression och den har en extra parameter för att modellera överdispersionen. Om den villkorliga fördelningen av resultatvariabeln är överdispergerad, kommer konfidensintervallen för negativ binomialregression sannolikt att vara smalare jämfört med de från en Poisson-regression.
- noll-uppblåst regressionsmodell-noll-uppblåsta modeller försöker redogöra för överskott av nollor. Med andra ord tros två typer av nollor existera i data, ”sanna nollor” och ”överflödiga nollor”. Nolluppblåsta modeller uppskattar två ekvationer samtidigt, en för räknemodellen och en för överskott av nollor.
- OLS regression – Count resultatvariabler loggas ibland och analyseras med hjälp av OLS-regression. Många problem uppstår med detta tillvägagångssätt, inklusive förlust av data på grund av odefinierade värden som genereras genom att ta loggen på noll (som är odefinierad) och partiska uppskattningar.
Poisson regression
nedan använder vi poisson-kommandot för att uppskatta en Poisson regressionsmodell. I. before prog indikerar att det är en faktorvariabel (dvs., kategorisk variabel), och att den ska ingå i modellen som en serie indikatorvariabler.
vi använder alternativet VCE(robust) för att få robusta standardfel för parameteruppskattningarna som rekommenderas av Cameron och Trivedi (2009) för att kontrollera för mild överträdelse av underliggande antaganden.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
Chi-square-testet med två grader av frihet indikerar att prog, tillsammans, är en statistiskt signifikant prediktor för num_awards.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
för att hjälpa till att bedöma modellens passform kan kommandot estat gof användas för att erhålla Chi-squared-testet för godhet. Detta är inte ett test av modellkoefficienterna (som vi såg i rubrikinformationen), utan ett test av modellformen: passar poisson-modellformen våra data?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
vi drar slutsatsen att modellen passar ganska bra eftersom Chi-squared-testet inte är statistiskt signifikant. Om testet hade varit statistiskt signifikant skulle det indikera att data inte passar modellen bra. I den situationen kan vi försöka avgöra om det finns utelämnade prediktorvariabler, om vårt linjäritetsantagande håller och/eller om det finns ett problem med överdispersion.
Ibland kanske vi vill presentera regressionsresultaten som incidentfrekvensförhållanden, vi kan använda theirr-alternativet. Dessa IRR-värden är lika med våra koefficienter från utgången ovan exponentierad.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
utmatningen ovan indikerar att incidenthastigheten för 2.prog är 2,96 gånger incidenthastigheten för referensgruppen (1.Prog). Likaså incidenthastigheten för 3.prog är 1,45 gånger incidenthastigheten för referensgruppen som håller de andra variablerna konstanta. Den procentuella förändringen i incidenthastigheten för num_awards är en ökning med 7% för varje enhetsökning i matematik.
minns formen av vår modell ekvation:
log (num_awards)=avlyssna + b1(prog=2) + b2(prog = 3) + b3math.
detta innebär:
num_awards = exp(Intercept + b1(prog=2) + b2(prog=3)+ b3math) = exp(Intercept) * exp(b1(prog=2)) * exp(b2(prog=3)) * exp(b3math)
koefficienterna har en additiv effekt i Log(y) – skalan och IRR har en multiplikativ effekt i y-skalan.
För ytterligare information om de olika mätvärdena där resultaten kan presenteras och tolkningen av sådana, se regressionsmodeller för kategoriska beroende variabler med Stata, andra upplagan av J. Scott Long och Jeremy Freese (2006).
för att förstå modellen bättre kan vi använda kommandot marginaler. Nedan använder vi kommandot marginaler för att beräkna de förutsagda räkningarna på varje nivå avprog, håller alla andra variabler (i detta exempel matematik) i modellen vid deras medelvärden.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
i utmatningen ovan ser vi att det förutsagda antalet händelser för nivå 1 i prog handlar om .21, håller matematik vid dess medelvärde. Det förutsagda antalet händelser för nivå 2 av prog är högre vid .62, och det förutsagda antalet händelser för nivå 3 av prog handlar om .31. Observera att den förutsagda räkningen av nivå 2 av prog är (.6249446/.211411) = 2,96 gånger högre än det förutsagda antalet för nivå 1 av prog. Detta matchar vad vi såg i IRR-utgångstabellen.
nedan kommer vi att få de förutsagda räkningarna för matematiska värden som sträcker sig från 35 till 75 i steg om 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
tabellen ovan visar att med prog vid dess observerade värden och matematik som hålls vid 35 för alla observationer är det genomsnittliga förutsagda antalet (eller genomsnittligt antal utmärkelser) ungefär .13; när matematik = 75 är det genomsnittliga förutsagda antalet cirka 2,17. Om vi jämför de förutsagda räkningarna vid math = 35 och math = 45 kan vi se att förhållandet är (.2644714/.1311326) = 2.017. Detta matchar IRR för 1.0727 för en 10-enhetsbyte: 1.0727^10 = 2.017.
det användarskrivna fitstat-kommandot (liksom statas estat-kommandon) kan användas för att få ytterligare information som kan vara till hjälp om du vill jämföra modeller. Du kan skriva search fitstat för att ladda ner det här programmet (se hur kan jag använda sökkommandot för att söka efter program och få ytterligare hjälp? för mer information om hur du använder Sök).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
Du kan rita det förutsagda antalet händelser med kommandona nedan. Grafen indikerar att flest utmärkelser förutses för dem i det akademiska programmet (prog = 2), särskilt om studenten har en hög matematikpoäng. Det lägsta antalet förutspådda utmärkelser är för de studenter i det allmänna programmet (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
saker att tänka på
- Om överdispersion verkar vara ett problem, bör vi först kontrollera om vår modell är korrekt specificerad, till exempel utelämnade variabler och funktionella former. Om vi till exempel utelämnade prediktorvariabeln progin exemplet ovan verkar vår modell ha problem med överdispersion. Med andra ord kan en felspecificerad modell presentera ett symptom som ett överdispersionsproblem.
- Om du antar att modellen är korrekt specificerad, kanske du vill kontrollera foroverdispersion. Det finns flera sätt att göra detta inklusive sannolikhetsprovet för överdispersionsparameter alfa genom att köra samma regressionsmodell med negativ binomialfördelning (nbreg).
- en vanlig orsak till överdispersion är överskott av nollor, som i sin tur genereras av en ytterligare datagenereringsprocess. I denna situation bör nolluppblåst modell övervägas.
- Om datagenereringsprocessen inte tillåter några 0s (t.ex. antalet dagar som spenderas på sjukhuset), kan en nollkortad modell vara mer lämplig.
- Räkningsdata har ofta en exponeringsvariabel, som anger hur många gånger händelsen kunde ha hänt. Denna variabel bör införlivas i en Poisson-modell med alternativet exp ().
- resultatvariabeln i en Poisson-regression kan inte ha negativa tal och exponeringen kan inte ha 0s.
- i Stata kan en Poisson-modell uppskattas via glm-kommandot med logglänken och Poisson-familjen.
- Du måste använda glm-kommandot för att få resterna för att kontrollera andra antaganden om Poisson-modellen (se Cameron and Trivedi (1998) och Dupont (2002) för mer information).
- Det finns många olika mått på pseudo-R-kvadrat. De försöker alla ge information som liknar den som tillhandahålls av R-kvadrat i OLS-regression, även om ingen av dem kan tolkas exakt som R-kvadrat i OLS-regression tolkas. För en diskussion om olika pseudo-R-kvadrater, se Long and Freese (2006) eller vår FAQ-sidavad är pseudo-r-kvadrater?.
- Poisson-regression uppskattas via maximal sannolikhetsbedömning. Det kräver vanligtvis en stor provstorlek.
Se även
- annoterad utgång för Poisson-kommandot
- Stata FAQ: Hur kan jag använda countfit när jag väljer en räknemodell?
- Stata Online manual
- poisson
- Stata Vanliga frågor
- Hur beräknas standardfel och konfidensintervall för incidensfrekvensförhållanden (IRR) av poisson och nbreg?
- Cameron, AC och Trivedi, Pk (2009). Mikroekonometri Med Stata. College Station, TX: Stata Press.
- Cameron, A. C. och Trivedi ,P. K. (1998). Regressionsanalys av Räkningsdata. New York: Cambridge Press.
- Cameron, A. C. framsteg i Räkna data Regression prata för tillämpad statistik Workshop, Mars 28, 2009.http://cameron.econ.ucdavis.edu/racd/count.html .
- Dupont, W. D. (2002). Statistisk modellering för biomedicinska forskare: en enkel introduktion till analys av komplexa Data. New York: Cambridge Press.
- lång, J. S. (1997). Regressionsmodeller för kategoriska och begränsade beroende variabler.Thousand Oaks, CA: Sage publikationer.
- Long, J. S. och Freese, J. (2006). Regressionsmodeller för kategoriska beroende variabler med Stata, andra upplagan. College Station, TX: Stata Press.