Senast uppdaterad den 17 februari 2021
en förutsägelse ur ett maskininlärningsperspektiv är en enda punkt som döljer osäkerheten i den förutsägelsen.
Prediktionsintervall ger ett sätt att kvantifiera och kommunicera osäkerheten i en förutsägelse. De skiljer sig från konfidensintervall som istället försöker kvantifiera osäkerheten i en populationsparameter som en medel-eller standardavvikelse. Prediktionsintervall beskriver osäkerheten för ett enda specifikt resultat.
i denna handledning kommer du att upptäcka prediktionsintervallet och hur man beräknar det för en enkel linjär regressionsmodell.
När du har slutfört denna handledning kommer du att veta:
- att ett prediktionsintervall kvantifierar osäkerheten för en enda punktprediktion.
- att prediktionsintervall kan uppskattas analytiskt för enkla modeller, men är mer utmanande för olinjära maskininlärningsmodeller.
- hur man beräknar prediktionsintervallet för en enkel linjär regressionsmodell.
kickstarta ditt projekt med min nya Bokstatistik för maskininlärning, inklusive steg-för-steg-handledning och Python-källkodsfilerna för alla exempel.
Låt oss komma igång.
- uppdaterad Jun / 2019: korrigerad signifikansnivå som en bråkdel av standardavvikelser.
- uppdaterad Apr / 2020: fast typsnitt i plot av prediktionsintervall.

Prediktionsintervall för maskininlärning
foto av Jim Bendon, vissa rättigheter reserverade.
handledning Översikt
denna handledning är uppdelad i 5 delar; de är:
- Vad är fel med en Punktuppskattning?
- Vad är ett Prediktionsintervall?
- hur man beräknar ett Prediktionsintervall
- Prediktionsintervall för linjär Regression
- arbetat exempel
behöver du hjälp med statistik för maskininlärning?
Ta min gratis 7-dagars e-postkraschkurs nu (med provkod).
Klicka för att registrera dig och få en gratis PDF-e-bokversion av kursen.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.förutsäga (X)
|
där yhat är det uppskattade resultatet eller förutsägelsen som gjorts av den utbildade modellen för den givna indata X.
detta är en punktprognos.
per definition är det en uppskattning eller en approximation och innehåller viss osäkerhet.
osäkerheten kommer från fel i själva modellen och brus i ingångsdata. Modellen är en approximation av förhållandet mellan ingångsvariablerna och utgångsvariablerna.
Med tanke på den process som används för att välja och ställa in modellen, det kommer att vara den bästa approximation görs med tanke på tillgänglig information, men det kommer fortfarande att göra fel. Data från domänen kommer naturligtvis att dölja det underliggande och okända förhållandet mellan inmatnings-och utgångsvariablerna. Detta kommer att göra det till en utmaning att passa modellen, och kommer också att göra det till en utmaning för en passande modell att göra förutsägelser.
Med tanke på dessa två huvudsakliga felkällor är deras punktförutsägelse från en prediktiv modell otillräcklig för att beskriva den verkliga osäkerheten i förutsägelsen.
Vad är ett Prediktionsintervall?
ett prediktionsintervall är en kvantifiering av osäkerheten på en förutsägelse.
det ger en probabilistisk övre och nedre gräns för uppskattningen av en resultatvariabel.
ett prediktionsintervall för en enda framtida observation är ett intervall som med en viss grad av förtroende kommer att innehålla en framtida slumpmässigt vald observation från en distribution.
— sidan 27, statistiska intervaller: en Guide för utövare och forskare, 2017.
Prediktionsintervall används oftast när man gör förutsägelser eller prognoser med en regressionsmodell, där en kvantitet förutses.
ett exempel på presentationen av ett prediktionsintervall är följande:
givet en förutsägelse av ’y’ givet ’x’, Det finns en 95% sannolikhet att intervallet ’a’ till ’b’ täcker det sanna resultatet.
prediktionsintervallet omger prediktionen som gjorts av modellen och täcker förhoppningsvis intervallet för det sanna resultatet.
diagrammet nedan hjälper till att visuellt förstå förhållandet mellan förutsägelse, prediktionsintervall och det faktiska resultatet.
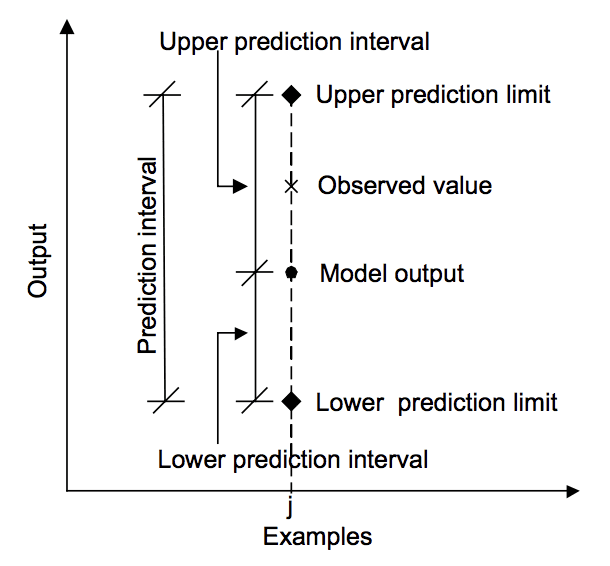
förhållandet mellan förutsägelse, verkligt värde och prediktionsintervall.
hämtad från ”Machine learning approaches for estimation of prediction interval for the model output”, 2006.
ett prediktionsintervall skiljer sig från ett konfidensintervall.
ett konfidensintervall kvantifierar osäkerheten för en uppskattad befolkningsvariabel, såsom medelvärdet eller standardavvikelsen. Medan ett prediktionsintervall kvantifierar osäkerheten på en enda observation uppskattad från befolkningen.
i prediktiv modellering kan ett konfidensintervall användas för att kvantifiera osäkerheten för den uppskattade skickligheten hos en modell, medan ett prediktionsintervall kan användas för att kvantifiera osäkerheten för en enda prognos.
ett prediktionsintervall är ofta större än konfidensintervallet eftersom det måste ta hänsyn till konfidensintervallet och variansen i utgångsvariabeln som förutses.
Prediktionsintervall kommer alltid att vara bredare än konfidensintervall eftersom de står för osäkerheten i samband med e , det irreducibla felet.
— sidan 103, En introduktion till statistiskt lärande: med applikationer i R, 2013.
hur man beräknar ett Prediktionsintervall
ett prediktionsintervall beräknas som en kombination av modellens uppskattade varians och variansen för utfallsvariabeln.
Prediktionsintervall är lätta att beskriva, men svåra att beräkna i praktiken.
i enkla fall som linjär regression kan vi uppskatta prediktionsintervallet direkt.
i fall av icke-linjära regressionsalgoritmer, såsom artificiella neurala nätverk, är det mycket mer utmanande och kräver val och implementering av specialiserade tekniker. Allmänna tekniker som bootstrap-omsamplingsmetoden kan användas, men är beräkningsmässigt dyra att beräkna.papperet” en omfattande granskning av neurala nätverksbaserade Prediktionsintervall och nya framsteg ” ger en rimligt ny studie av prediktionsintervall för olinjära modeller i samband med neurala nätverk. Följande lista sammanfattar några metoder som kan användas för förutsägelse osäkerhet för icke-linjära maskininlärningsmodeller:
- Delta-metoden, från fältet för icke-linjär regression.
- den Bayesianska metoden, från Bayesian modellering och statistik.
- Medelvariansestimeringsmetoden, med hjälp av beräknad statistik.
- Bootstrap-metoden, med hjälp av datasampling och utveckling av en ensemble av modeller.
Vi kan göra beräkningen av ett prediktionsintervall betong med ett arbetat exempel i nästa avsnitt.
Prediktionsintervall för linjär Regression
en linjär regression är en modell som beskriver den linjära kombinationen av ingångar för att beräkna utgångsvariablerna.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
vi känner inte till de sanna värdena för koefficienterna b0 och b1. Vi känner inte heller till de sanna befolkningsparametrarna som medel-och standardavvikelse för x eller y. alla dessa element måste uppskattas, vilket introducerar osäkerhet i användningen av modellen för att göra förutsägelser.
Vi kan göra vissa antaganden, såsom fördelningarna av x och y och förutsägelsesfel som gjorts av modellen, kallade rester, är gaussiska.
prediktionsintervallet runt yhat kan beräknas enligt följande:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
vi vet inte i praktiken. Vi kan beräkna en objektiv uppskattning av den förutsagda standardavvikelsen enligt följande (taget från maskininlärningsmetoder för uppskattning av prediktionsintervall för modellutgången):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
arbetat exempel
Låt oss göra fallet med linjära regressionsprognosintervall konkreta med ett arbetat exempel.
låt oss först definiera en enkel tvåvariabel dataset där utgångsvariabeln (y) beror på ingångsvariabeln (x) med något Gaussiskt brus.
exemplet nedan definierar datamängden vi kommer att använda för detta exempel.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# generera relaterade variabler
från numpy import mean
från numpy import std
from numpy.random import randn
from numpy.random import seed
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# summarize
print(’x: mean=%.3f stdv=%.3f’ % (mean(x), std(x)))
print(’y: mean=%.3f stdv=%.3f’ % (mean(y), std(y)))
# plot
pyplot.scatter(x, y)
pyplot.show()
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
en plot av datauppsättningen skapas sedan.
Vi kan se det tydliga linjära förhållandet mellan variablerna med spridningen av punkterna som markerar bruset eller slumpmässigt fel i förhållandet.
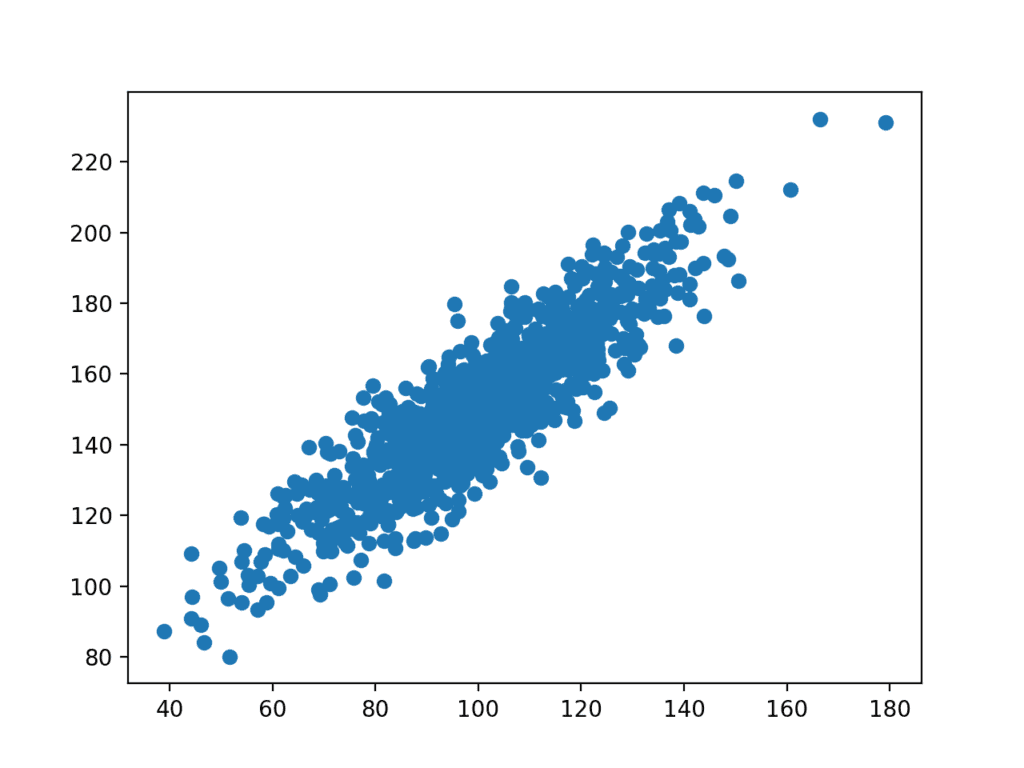
Scatter Plot av relaterade variabler
därefter kan vi utveckla en enkel linjär regression som med tanke på ingångsvariabeln x, kommer att förutsäga y-variabeln. Vi kan använda linregress () SciPy-funktionen för att passa modellen och returnera B0-och b1-koefficienterna för modellen.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# enkel icke-linjär regressionsmodell
från numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(’b0=%.3f, b1=%.3f’ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r’)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
B0=1.011, B1=49.117
|
koefficienterna används sedan med ingångarna från datauppsättningen för att göra en förutsägelse. De resulterande ingångarna och förutsagda y-värdena plottas som en linje ovanpå scatter-diagrammet för datauppsättningen.
Vi kan tydligt se att modellen har lärt sig det underliggande förhållandet i datasetet.
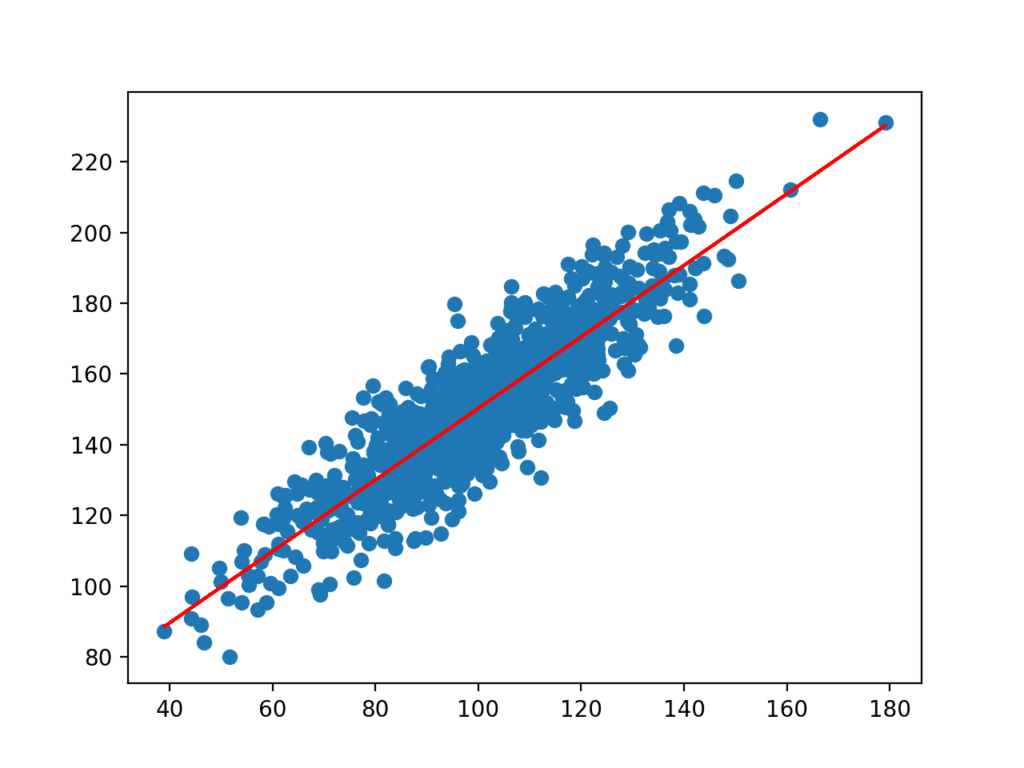
Scatter Plot av Dataset med linje för enkel linjär regressionsmodell
Vi är nu redo att göra en förutsägelse med vår enkla linjära regressionsmodell och lägga till ett prediktionsintervall.
Vi kommer att passa modellen som tidigare. Den här gången tar vi ett prov från datauppsättningen för att visa prediktionsintervallet. Vi kommer att använda ingången för att göra en förutsägelse, beräkna prediktionsintervallet för förutsägelsen och jämföra förutsägelsen och intervallet med det kända förväntade värdet.
låt oss först definiera indata, förutsägelse och förväntade värden.
|
1
2
3
|
x_in = X
y_out = y
yhat_out = yhat
|
därefter kan vi uppskatta standardkurvaturen i prediktionsriktningen.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.statistik importera linregress
från matplotlib importera pyplot
# seed slumptalsgenerator
frö(1)
# Förbered data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# montera den icke-linjära regressionsmodellen
B1, B0, r_value, p_value, std_err = linregress(x, y)
# markera förutsägelser
yhat = B0 + B1 * X
# Definiera ny ingång, förväntat värde och förutsägelse
x_in = x
y_out = y
yhat_out = yhat
# uppskattning StDev av yhat
sum_errs = arraysum ((y-yhat) * * 2)
stdev = sqrt(1/(len(y) -2) * sum_errs)
# beräkna prediktionsintervall
intervall = 1,96 * stdev
Skriv ut(’Prediktionsintervall: %.3F ’ % intervall)
lägre, övre = yhat_out-intervall, yhat_out + intervall
utskrift (’95% % sannolikhet att det verkliga värdet är mellan %.3f och %.3F’ % (lägre, övre))
Skriv ut (’sant värde: %.3f ’ % y_out)
# plot dataset och förutsägelse med intervall
pyplot.scatter (x, y)
pyplot.tomt (x, yhat, Färg=’Röd’)
pyplot.errorbar (x_in, yhat_out,yerr = intervall, Färg= ’Svart’, fmt= ’o’)
pyplot.visa ()
|
kör exemplet uppskattar yhat-standardavvikelsen och beräknar sedan prediktionsintervallet.
När det har beräknats presenteras prediktionsintervallet för användaren för den givna ingångsvariabeln. Eftersom vi konstruerade detta exempel vet vi det sanna resultatet, vilket vi också visar. Vi kan se att i detta fall täcker 95% förutsägelsesintervallet det verkliga förväntade värdet.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
en plot skapas också som visar den råa datauppsättningen som en scatter-plot, förutsägelserna för datauppsättningen som en röd linje och prediktions-och prediktionsintervallet som en svart punkt respektive linje.
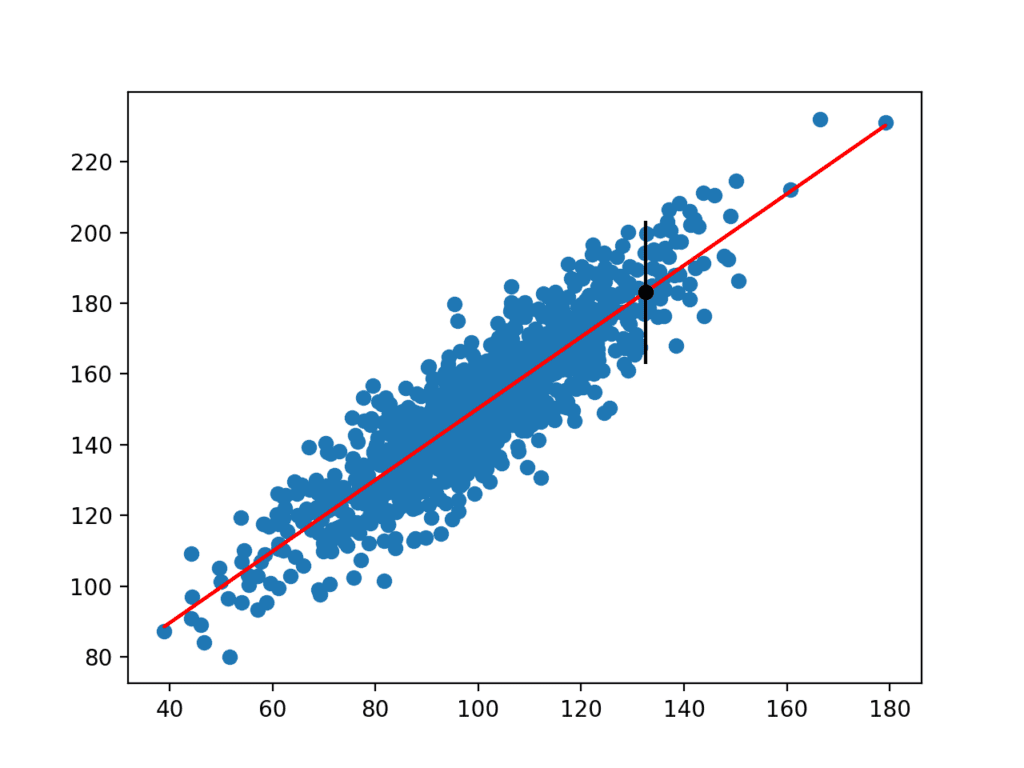
Scatter Plot av Dataset med linjär modell och Prediktionsintervall
Extensions
det här avsnittet listar några förslag på hur du kan utöka handledningen som du kanske vill utforska.
- sammanfatta skillnaden mellan tolerans, förtroende och prediktionsintervall.
- utveckla en linjär regressionsmodell för en standard maskininlärningsdataset och beräkna prediktionsintervall för en liten testuppsättning.
- Beskriv i detalj hur en icke-linjär prediktionsintervallmetod fungerar.
om du utforskar någon av dessa tillägg, skulle jag gärna veta.
Vidare läsning
det här avsnittet ger mer resurser om ämnet om du vill gå djupare.
inlägg
- hur man rapporterar Klassificeringsprestanda med konfidensintervall
- hur man beräknar Bootstrap konfidensintervall för maskininlärning resulterar i Python
- förstå Tidsserieprognososäkerhet med konfidensintervall med Python
- uppskatta antalet Experimentupprepningar för stokastiska maskininlärningsalgoritmer
böcker
- förstå den nya statistiken: effektstorlekar, konfidensintervall och metaanalys, 2017.
- statistiska intervaller: en Guide för utövare och forskare, 2017.
- En introduktion till statistiskt lärande: med applikationer i R, 2013.
- introduktion till den nya statistiken: Estimation, Open Science, and Beyond, 2016.
- prognoser: principer och praxis, 2013.
papper
- en jämförelse av vissa feluppskattningar för neurala nätverksmodeller, 1995.
- maskininlärningsmetoder för uppskattning av prediktionsintervall för modellutgången, 2006.
- en omfattande översyn av neurala nätverksbaserade Prediktionsintervall och nya framsteg, 2010.
API
- scipy.statistik.linregress () API
- matplotlib.pyplot.sprida ut () API
- matplotlib.pyplot.errorbar () API
artiklar
- Prediktionsintervall på Wikipedia
- Bootstrap prediktionsintervall på Kors validerade
sammanfattning
i denna handledning upptäckte du prediktionsintervallet och hur man beräknar det för en enkel linjär regressionsmodell.
specifikt lärde du dig:
- att ett prediktionsintervall kvantifierar osäkerheten för en enda punktprediktion.
- att prediktionsintervall kan uppskattas analytiskt för enkla modeller men är mer utmanande för icke-linjära maskininlärningsmodeller.
- hur man beräknar prediktionsintervallet för en enkel linjär regressionsmodell.
har du några frågor?
Ställ dina frågor i kommentarerna nedan och jag kommer att göra mitt bästa för att svara.
ta hand om statistik för maskininlärning!

utveckla en fungerande förståelse för statistik
…genom att skriva kodrader i python
Upptäck hur i min nya Ebook:
statistiska metoder för maskininlärning
det ger självstudiehandledning om ämnen som:
hypotesprov, korrelation, icke-parametrisk statistik, Omsampling och mycket mer…
Upptäck hur du omvandlar Data till kunskap
hoppa över akademikerna. Bara Resultat.
se vad som finns inuti