VMware High Availability (HA) är ett verktyg som eliminerar behovet av dedikerad standby-hårdvara och programvara i en virtualiserad miljö. VMware HA används ofta för att förbättra tillförlitligheten, minska driftstopp i virtuella miljöer och förbättra katastrofåterställning/kontinuitet i verksamheten.
detta kapitel utdrag från VCP4 Exam Cram: VMware Certified Professional, 2: a upplagan av Elias Khnaser utforskar VMware HA bästa praxis.
VMware hög tillgänglighet handlar främst om ESX / ESXi-värdfel och vad som händer med virtuella maskiner (VM) som körs på den här värden. HA kan också övervaka och starta om en VM genom att kontrollera om VMware-verktygen fortfarande körs. När en ESX / ESXi värd misslyckas av någon anledning, alla kör VM misslyckas också. VMware HA säkerställer att VM: erna från den misslyckade värden kan startas om på andra ESX/ESXi-värdar.
många förväxlar felaktigt VMware HA med feltolerans. VMware HA är inte feltolerant i att om en värd misslyckas, VM: erna på den misslyckas också. HA handlar bara om att starta om dessa virtuella datorer på andra ESX / ESXi-värdar med tillräckligt med resurser. Feltolerans ger å andra sidan oavbruten tillgång till resurser i händelse av värdfel.
 klicka på bokomslagsbilden ovan
klicka på bokomslagsbilden ovan för att ladda ner Elias Khnasers hela kapitel
om säkerhetskopiering och hög tillgänglighet.
VMware HA upprätthåller en kommunikationskanal med alla andra ESX / ESXi-värdar som är medlemmar i samma kluster genom att använda ett hjärtslag som det skickar ut varje 1 sekund i vSphere 4.0 eller var 10: e sekund i vSphere 4.1 som standard. När en ESX-server missar ett hjärtslag väntar de andra värdarna 15 sekunder på att den andra värden svarar igen. Efter 15 sekunder initierar klustret omstart av VM: erna på den misslyckade ESX/ESXi-värden på de återstående ESX/ESXi-värdarna i klustret. VMware HA övervakar också ständigt ESX / ESXi-värdarna som är medlemmar i klustret och ser till att resurser alltid är tillgängliga för att uppfylla kraven i händelse av värdfel.
övervakning av virtuell maskinfel
övervakning av virtuell maskinfel är teknik som är inaktiverad som standard. Dess funktion är att övervaka virtuella maskiner, som den frågar var 20: e sekund via ett hjärtslag. Det gör detta genom att använda VMware-verktygen som är installerade i VM. När en VM missar ett hjärtslag, VMware HA anser denna VM som misslyckades och försöker återställa den. Tänk på övervakning av virtuella maskinfel som en slags hög tillgänglighet för VM.
övervakning av virtuella maskinfel kan upptäcka om en virtuell maskin var manuellt avstängd, avstängd eller migrerad och försöker därmed inte starta om den.
VMware ha-konfigurationsförutsättningar
HA kräver följande konfigurationsförutsättningar innan den kan fungera korrekt:
- vCenter: eftersom VMware HA är en företagsklassfunktion kräver den vCenter innan den kan aktiveras.
- DNS-upplösning: alla ESX / ESXi-värdar som är medlemmar i Ha-klustret måste kunna lösa varandra med DNS.
- tillgång till delad lagring: alla värdar i Ha-klustret måste ha åtkomst och synlighet till samma delade Lagring; annars skulle de inte ha tillgång till VM: erna.
- tillgång till samma nätverk: Alla ESX / ESXi-värdar måste ha samma nätverk konfigurerade på alla värdar så att när en VM startas om på någon värd, har den igen tillgång till rätt nätverk.
Service Console redundans
rekommenderad praxis dikterar att Service Console (SC) har redundans. VMware HA klagar och utfärdar en varning om den upptäcker att Servicekonsolen är konfigurerad på en vSwitch med endast en vmnic. Som Figur 1 visar kan du konfigurera Service Console redundans på ett av två sätt:
- skapa två Service Console portgrupper, var och en på en annan vSwitch.
- tilldela två fysiska nätverkskort (Nic) i form av ett NIC-team till Service Console vSwitch.
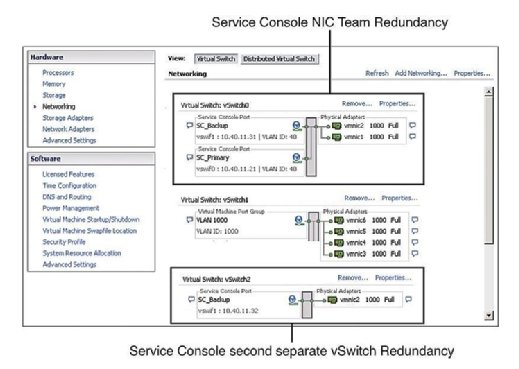
i båda fallen måste du konfigurera hela IP-stacken med IP-adress, subnät och gateway. Service Console vSwitches används för hjärtslag och tillståndssynkronisering och använder följande portar:
- inkommande TCP-port 8042
- inkommande UDP-port 8045
- utgående TCP-port 2050
- utgående UDP-port 2250
- inkommande TCP-port 8042-8045
- inkommande UDP-port 8042-8045
- utgående TCP-port 2050-2250
- utgående UDP-port 2050-2250
underlåtenhet att konfigurera SC-redundans resulterar i ett varningsmeddelande när du aktiverar ha. Så, för att undvika att se detta felmeddelande och följa bästa praxis, konfigurera SC för att vara överflödig.
värd failover kapacitetsplanering
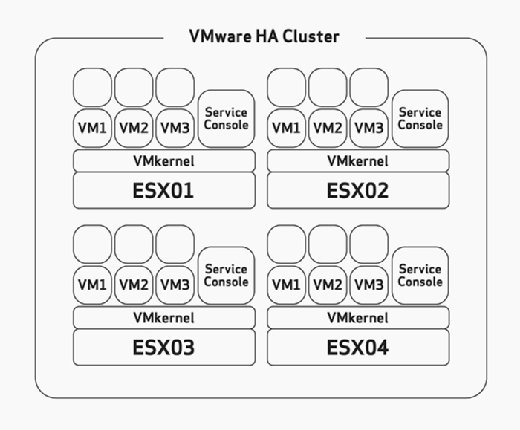
När du konfigurerar HA måste du manuellt konfigurera den maximala värdfeltoleransen. Det här är en uppgift som du eftertänksamt bör överväga under maskinvarustorleken och planeringsfasen för din distribution. Detta förutsätter att du har byggt dina ESX/ESXi-värdar med tillräckligt med resurser för att köra fler virtuella maskiner än planerat för att kunna rymma HA. I Figur 2 märker du till exempel att ha-klustret har fyra ESX-värdar och att alla fyra av dessa värdar har tillräcklig kapacitet för att köra minst tre VM. Eftersom de alla redan kör tre VM, betyder det att detta kluster har råd med förlusten av två ESX/ESXi-värdar eftersom de återstående två ESX/ESXi-värdarna kan slå på de sex misslyckade VM-erna utan problem om fel uppstår.
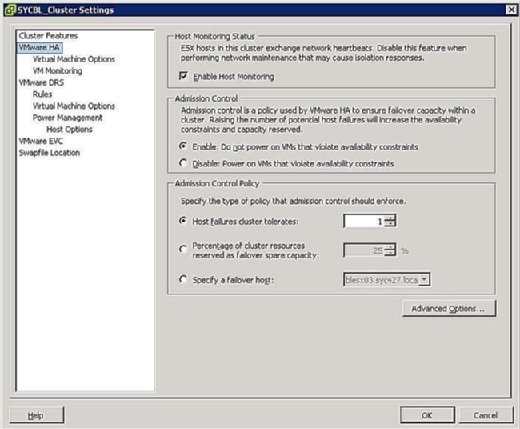
under konfigurationsfasen för ha-klustret visas en skärm som liknar den som visas i Figur 3 som uppmanar dig att definiera två clusterwide-konfigurationer enligt följande:
- Värdövervakningsstatus:
- aktivera Värdövervakning: med den här inställningen kan du styra om ha-klustret ska övervaka värdarna för hjärtslag. Detta är klustrets sätt att avgöra om en värd fortfarande är aktiv. I vissa fall, när du kör underhållsuppgifter på ESX / ESXi-värdar, kan det vara önskvärt att inaktivera det här alternativet för att undvika att isolera en värd.
- Antagningskontroll:
- aktivera: slå inte på VM som bryter mot tillgänglighetsbegränsningar: Om du väljer det här alternativet indikerar det att om inga resurser finns tillgängliga för att uppfylla en VM, ska den inte vara påslagen.
- inaktivera: slå på virtuella datorer som bryter mot tillgänglighetsbegränsningar: om du väljer det här alternativet indikerar du att du ska slå på en VM även om du måste överkomma resurser.
- Admission Control Policy:
- värdfel kluster tolererar: med den här inställningen kan du konfigurera hur många värdfel du vill tolerera. De tillåtna inställningarna är 1 till 4.
- andel klusterresurser som reserverats som reservkapacitet vid växling vid fel: Om du väljer det här alternativet anger du att du reserverar en procentandel av de totala klusterresurserna i reserv för failover. I ett kluster med fyra värdar indikerar en reservation på 25% att du avsätter en hel värd för failover. Om du vill avsätta färre kan du välja 10% av klusterresurserna istället.
- ange en failover-värd: om du väljer det här alternativet anger du att du väljer en viss värd som failover-värd i klustret. Detta kan vara fallet om du har en extra värd eller har en viss värd som har betydligt mer beräknings-och minnesresurser tillgängliga.
Värdisolering
ett nätverksfenomen som kallas en delad hjärna uppstår när ESX/ESXi-värden har slutat ta emot hjärtslag från resten av klustret. Hjärtslaget frågas för varje sekund i vSphere 4.0 eller 10 sekunder i vSphere 4.1. Om ett svar inte tas emot tror klustret att ESX/ESXi-värden har misslyckats. När detta inträffar har ESX/ESXi-värden förlorat sin nätverksanslutning på sitt hanteringsgränssnitt. Värden kan fortfarande vara igång och VM: erna kanske inte ens påverkas med tanke på att de kanske använder ett annat nätverksgränssnitt som inte har påverkats. VSphere måste dock vidta åtgärder när detta händer eftersom det tror att en värd har misslyckats. För den delen skapades värdisoleringsresponsen. Värdisoleringssvar är HA: s sätt att hantera en ESX/ESXi-värd som har tappat sin nätverksanslutning.
Du kan styra vad som händer med VM i händelse av en värdisolering. För att komma till skärmen VM Isolation Response högerklickar du på klustret i fråga och klickar på Redigera Inställningar. Du kan sedan klicka på virtuella Maskinalternativ under VMware HA-bannern i den vänstra rutan. Du kan styra alternativ clusterwide genom att ställa in alternativet värdisoleringssvar i enlighet därmed. Detta tillämpas på alla VM på den drabbade värden. Med det sagt kan du alltid åsidosätta klusterinställningarna genom att definiera ett annat svar på VM-nivån.
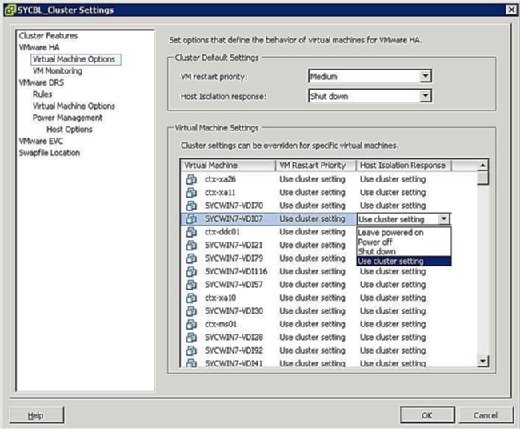
som visas i Figur 4 är alternativen för Isoleringssvar följande:
- lämna påslagen: som etiketten antyder betyder denna inställning att VM förblir påslagen vid värdisolering.
- strömavstängning: den här inställningen anger att VM-datorn stängs av vid en isolering. Detta är en hård avstängning.
- Stäng av: den här inställningen definierar att i händelse av en isolering stängs VM graciöst med VMware-verktyg. Om den här uppgiften inte har slutförts inom fem minuter utförs en avstängning omedelbart. Om VMware Tools inte är installerat körs en avstängning istället.
- använd Klusterinställning: denna inställning vidarebefordrar uppgiften till den klusteromfattande inställning som definierats i fönstret som tidigare visas i Figur 4.
i händelse av en isolering betyder det inte nödvändigtvis att värden är nere. Eftersom VM: erna kan konfigureras med olika fysiska nätverkskort och anslutas till olika nätverk kan de fortsätta att fungera korrekt; du måste därför överväga detta när du ställer in prioritet för isolering. När en värd är isolerad betyder det helt enkelt att dess Servicekonsol inte kan kommunicera med resten av ESX/ESXi-värdarna i klustret.
virtuell maskinåterställningsprioritet
Om ditt HA-kluster inte kan rymma alla virtuella datorer i händelse av ett fel, har du möjlighet att prioritera virtuella datorer. Prioriteringarna dikterar vilka VM-ar som startas om först och vilka VM-ar som inte är så viktiga i händelse av en nödsituation. Dessa alternativ är konfigurerade på samma skärm som Isolationssvaret som omfattas av föregående avsnitt. Du kan konfigurera clusterwide-inställningar som ska tillämpas på alla virtuella datorer på den berörda värden, eller du kan åsidosätta klusterinställningarna genom att konfigurera en åsidosättning på VM-nivå.
Du kan ställa in en VM: s omstartsprioritet till något av följande:
- hög: VM med hög prioritet startas om först.
- Medium: detta är standardinställningen.
- låg: VM med låg prioritet startas om senast.
- använd Klusterinställning: virtuella datorer startas om baserat på inställningen definierad på klusternivån definierad i fönstret som visas i figuren nedan.
- inaktiverad: VM slås inte på.
prioriteten bör ställas in baserat på VMs: s betydelse. Med andra ord kanske du vill starta om domänkontrollanter och inte starta om skrivarservrar. De högre prioriterade virtuella maskinerna startas om först. Virtuella maskiner som tål att vara avstängda i händelse av en nödsituation bör konfigureras för att förbli avstängda för att spara resurser.
MSCs clustering
huvudsyftet med ett kluster är att säkerställa att kritiska system förblir online till varje pris och hela tiden. I likhet med fysiska maskiner som kan grupperas kan virtuella maskiner också grupperas med ESX med tre olika scenarier:
- Cluster-in-a-box: i det här scenariot finns alla virtuella datorer som ingår i klustret på samma ESX/ESXi-värd. Som du kanske har gissat skapar detta omedelbart en enda felpunkt: ESX/ESXi-värden. När det gäller delad lagring kan du använda virtuella diskar som delad lagring i det här scenariot, eller du kan använda Raw Device Mapping (RDM) i virtuellt kompatibilitetsläge.
- Cluster-across-boxes: i det här scenariot finns klusternoder (virtuella datorer som är medlemmar i klustret) på flera ESX/ESXi-värdar, varigenom var och en av noderna som utgör klustret kan komma åt samma lagring så att om en VM misslyckas kan den andra fortsätta att fungera och få tillgång till samma data. Detta scenario skapar en idealisk klustermiljö genom att eliminera en enda felpunkt. Delad lagring är en förutsättning för detta och måste ligga på Fibre Channel SAN. Du måste också använda en RDM i fysiskt eller virtuellt kompatibilitetsläge eftersom virtuella diskar inte är en konfiguration som stöds för delad lagring. Varigenom var och en av noderna som utgör klustret kan komma åt samma lagring så att om en VM misslyckas kan den andra fortsätta att fungera och få tillgång till samma data.
- fysiskt till virtuellt kluster: I detta scenario är en medlem i klustret en virtuell maskin, medan den andra medlemmen är en fysisk maskin. Delad lagring är en förutsättning i detta scenario och måste konfigureras som en RDM i fysiskt kompatibilitetsläge.
När du utformar en klusterlösning måste du ta itu med problemet med delad lagring, vilket skulle tillåta flera värdar eller virtuella datorer åtkomst till samma data. vSphere erbjuder flera metoder genom vilka du kan tillhandahålla delad lagring enligt följande:
- virtuella diskar: Du kan bara använda en virtuell disk som ett delat lagringsområde om du gör kluster i en ruta-med andra ord bara om båda VM: erna finns på samma ESX/ESXi-värd.
- RDM i fysiskt kompatibilitetsläge: med det här läget kan du ansluta en fysisk LUN direkt till en VM eller fysisk maskin. Detta läge hindrar dig från att använda funktioner som ögonblicksbilder och används idealiskt när en medlem i klustret är en fysisk maskin medan den andra är en VM.
- RDM i virtuellt kompatibilitetsläge: med det här läget kan du ansluta en fysisk LUN direkt till en VM eller fysisk maskin. Detta läge ger dig alla fördelar med virtuella diskar som körs på VMFS inklusive ögonblicksbilder och avancerad fillåsning. Skivan nås via hypervisorn och är idealisk när du konfigurerar ett kluster-across-boxes-scenario där du måste ge båda virtuella datorerna tillgång till delad lagring.
När detta skrivs är den enda VMware-stödda klustringstjänsten Microsoft Clustering Services (MSCS). Du kan konsultera VMware white paper ” Setup för Failover Clustering och Microsoft Cluster Service.”
VMware feltolerans
VMware feltolerans (FT) är en annan form av VM-kluster som utvecklats av VMware för system som kräver extrem drifttid. En av de mest övertygande funktionerna i FT är dess enkla installation. FT är helt enkelt en kryssruta som kan aktiveras. Jämfört med traditionella kluster som kräver specifika konfigurationer och i vissa fall kablage, FT är enkel men kraftfull.
hur fungerar det?
När du skyddar VM med FT skapas en sekundär VM i låssteg av den skyddade VM, den första VM. FT arbetar genom att samtidigt skriva till den första VM och den andra VM samtidigt. Varje uppgift skrivs två gånger. Om du klickar på Start-menyn på den första VM, kommer Start-menyn på den andra VM också att klickas. Kraften i FT är dess förmåga att hålla båda VM: erna synkroniserade.
om den skyddade VM skulle gå ner av någon anledning, tar den sekundära VM omedelbart sin plats, griper sin identitet och dess IP-adress, fortsätter att betjäna användare utan avbrott. Den nyligen främjade skyddade VM skapar sedan en sekundär för sig själv på en annan värd och cykeln startar om.
för att klargöra, låt oss se ett exempel. Om du vill skydda en Exchange-server kan du aktivera FT. Om ESX/ESXi-värden som bär den skyddade VM av någon anledning misslyckas, sparkar den sekundära VM in och tar sina uppgifter utan avbrott i tjänsten.
tabellen nedan beskriver de olika hög tillgänglighet och klusterteknik som du har tillgång till med vSphere och belyser begränsningar för varje.

feltoleranskrav
feltolerans skiljer sig inte från någon annan företagsfunktion genom att den kräver att vissa förutsättningar uppfylls innan tekniken kan fungera korrekt och effektivt. Dessa krav beskrivs i följande lista och delas upp i de olika kategorierna som kräver specifika minimikrav:
- Värdkrav:
- FT-kompatibel CPU. Kontrollera den här VMware KB-artikeln för mer information.
- hårdvaruvirtualisering måste vara aktiverad i bios.
- värdens CPU – klockhastigheter måste ligga inom 400 MHz från varandra.
- VM krav:
- VM måste finnas på stöds delad lagring (FC, iSCSI och NFS).
- VMs måste köra ett operativsystem som stöds.
- VMs måste lagras i antingen en VMDK eller en virtuell RDM.
- VMs kan inte ha tunt tillhandahållit VMDK och måste använda en Eagerzeroedthick virtuell disk.
- virtuella datorer kan inte ha mer än en vCPU konfigurerad.
- Klusterkrav:
- Alla ESX / ESXi-värdar måste vara samma version och samma patchnivå.
- Alla ESX / ESXi-värdar måste ha tillgång till VM-datalager och nätverk.
- VMware HA måste vara aktiverat i klustret.
- varje värd måste ha ETT vMotion-och FT-Loggningsnic konfigurerat.
- Värdcertifikatkontroll måste också vara aktiverad.
det är mycket tillrådligt att du förutom att kontrollera processorkompatibilitet med FT kontrollerar din servers fabrikat och modellkompatibilitet med FT mot VMware Hardware Compatibility List (HCL).
medan FT är en bra klusterlösning är det viktigt att notera att det också har vissa begränsningar. Till exempel kan FT VMs inte snapshotted, och de kan inte Lagring vMotioned. Faktum är att dessa virtuella datorer automatiskt flaggas DRS-inaktiverade och kommer inte att delta i någon dynamisk resursbelastningsbalansering.
hur man aktiverar FT
Aktivera FT är inte svårt, men det innebär att konfigurera några olika inställningar. Följande inställningar måste konfigureras korrekt för att FT ska fungera:
- aktivera Värdcertifikatkontroll: För att aktivera denna inställning, logga in på din vCenter server och klicka på Administration från Arkiv-menyn och klicka på vCenter Server Settings. I den vänstra rutan klickar du på SSL-inställningar och markerar rutan vCenter kräver verifierad värd SSL-certifikat.
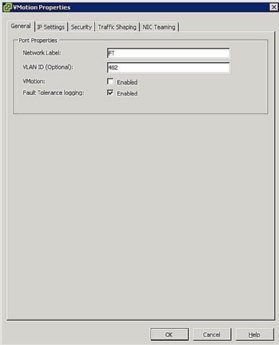
Figur 5. FT port gruppinställningar - konfigurera värdnätverk: Nätverkskonfigurationen för FT är enkel och följer samma steg och procedurer som vMotion, förutom i stället för att kontrollera VMotion-rutan, Kontrollera Feltoleransloggningsrutan som visas i Figur 5.
- slå FT på och av: när du har uppfyllt de föregående kraven kan du nu slå FT på och av för VM. Denna process är också enkel: hitta VM du vill skydda, högerklicka på den och välj feltolerans>slå på feltolerans.
medan FT är en första generationens klusterteknik, fungerar den imponerande bra och förenklar överkomplicerade traditionella metoder för att bygga, konfigurera och underhålla kluster. FT är en imponerande teknik för en upptidssynpunkt och från en sömlös failover-synvinkel.