¿Qué es el Aprendizaje por Refuerzo?
El aprendizaje por refuerzo se define como un método de aprendizaje automático que se ocupa de cómo los agentes de software deben tomar acciones en un entorno. El aprendizaje por refuerzo es una parte del método de aprendizaje profundo que le ayuda a maximizar parte de la recompensa acumulada.
Este método de aprendizaje de redes neuronales le ayuda a aprender cómo lograr un objetivo complejo o maximizar una dimensión específica en muchos pasos.
En el tutorial de Aprendizaje por refuerzo, aprenderá:
- ¿Qué es el aprendizaje por refuerzo?
- Términos importantes utilizados en el método de Aprendizaje por Refuerzo Profundo
- ¿Cómo funciona el Aprendizaje por refuerzo?
- Algoritmos de Aprendizaje de Refuerzo
- Características del Aprendizaje de Refuerzo
- Tipos de Aprendizaje de Refuerzo
- Modelos de aprendizaje de Refuerzo
- Aprendizaje de Refuerzo vs. Aprendizaje Supervisado
- Aplicaciones de Aprendizaje de Refuerzo
- ¿Por qué utilizar el Aprendizaje de refuerzo?
- ¿Cuándo No usar el Aprendizaje por Refuerzo?
- Desafíos del Aprendizaje por refuerzo
Términos importantes utilizados en el método de Aprendizaje por Refuerzo Profundo
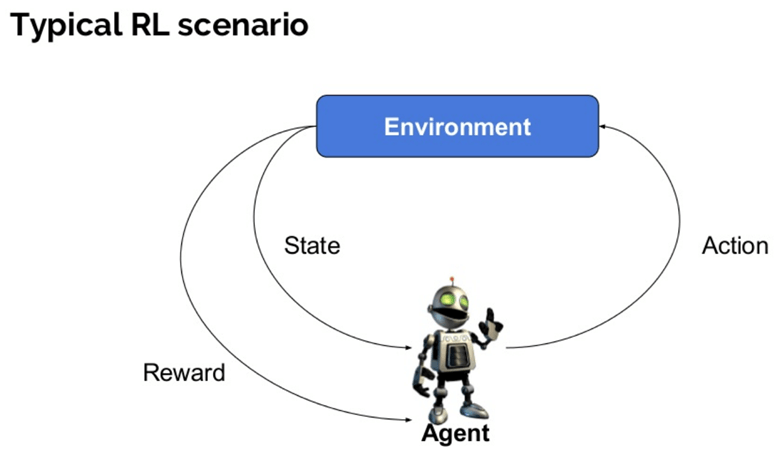
Estos son algunos términos importantes utilizados en IA por refuerzo:
- Agente: Es una entidad asumida que realiza acciones en un entorno para obtener alguna recompensa.
- Entorno (e): Un escenario al que debe enfrentarse un agente.
- Recompensa (R): Devolución inmediata a un agente cuando realiza una acción o tarea específica.
- Estado (es): Estado se refiere a la situación actual que devuelve el medio ambiente.
- Política (?): Es una estrategia que aplica el agente para decidir la siguiente acción en función del estado actual.Valor
- (V): Se espera un rendimiento a largo plazo con descuento, en comparación con la recompensa a corto plazo. Función de valor
- : Especifica el valor de un estado que es la cantidad total de recompensa. Es un agente que debe esperarse a partir de ese estado.
- Modelo del entorno: imita el comportamiento del entorno. Le ayuda a hacer inferencias a realizar y también a determinar cómo se comportará el entorno.
- Métodos basados en modelos: Es un método para resolver problemas de aprendizaje por refuerzo que utiliza métodos basados en modelos.
- Valor Q o valor de acción (Q): El valor Q es bastante similar al valor. La única diferencia entre los dos es que toma un parámetro adicional como acción actual.
¿Cómo funciona el Aprendizaje por refuerzo?
Veamos un ejemplo sencillo que te ayuda a ilustrar el mecanismo de aprendizaje por refuerzo.
Considere el escenario de enseñar nuevos trucos a su gato
- Como cat no entiende el inglés ni ningún otro idioma humano, no podemos decirle directamente qué hacer. En cambio, seguimos una estrategia diferente.
- Emulamos una situación, y el gato intenta responder de muchas maneras diferentes. Si la respuesta del gato es la deseada, le daremos pescado.
- Ahora, cada vez que el gato está expuesto a la misma situación, el gato ejecuta una acción similar con aún más entusiasmo en espera de obtener más recompensa(comida).
- Eso es como aprender que el gato obtiene de» qué hacer » de experiencias positivas.
- Al mismo tiempo, el gato también aprende lo que no hace cuando se enfrenta a experiencias negativas.
Explicación sobre el ejemplo:
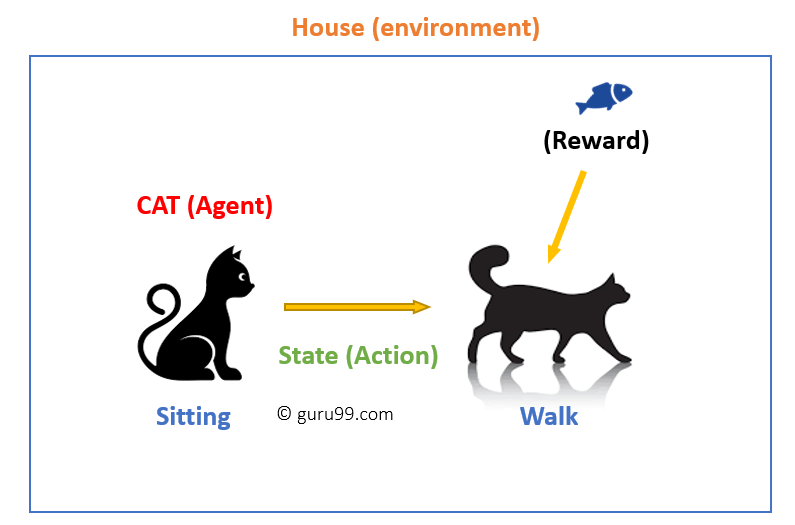
En este caso,
- Tu gato es un agente que está expuesto al ambiente. En este caso, es tu casa. Un ejemplo de un estado podría ser que tu gato esté sentado, y uses una palabra específica para que el gato camine.
- Nuestro agente reacciona realizando una transición de acción de un» estado «a otro «estado».»
- Por ejemplo, tu gato pasa de estar sentado a caminar.
- La reacción de un agente es una acción, y la política es un método para seleccionar una acción dado un estado en espera de mejores resultados.
- Después de la transición, pueden recibir una recompensa o penalización a cambio.
Algoritmos de Aprendizaje por refuerzo
Existen tres enfoques para implementar un algoritmo de Aprendizaje por refuerzo.
Basado en valores:
En un método de aprendizaje por refuerzo basado en valores, debe intentar maximizar una función de valor V (s). En este método, el agente espera un retorno a largo plazo de los estados actuales bajo la política ?.
Basado en políticas:
En un método RL basado en políticas, intenta crear una política tal que la acción realizada en cada estado le ayude a obtener la máxima recompensa en el futuro.
Dos tipos de métodos basados en políticas son:
- Deterministic: Para cualquier estado, la misma acción es producida por la política ?.
- Estocástico: Cada acción tiene una cierta probabilidad, que está determinada por la siguiente ecuación.Política estocástica:
n{a\s) = P\A, = a\S, =S]
Basado en modelos:
En este método de aprendizaje por refuerzo, debe crear un modelo virtual para cada entorno. El agente aprende a actuar en ese entorno específico.
Características del Aprendizaje por refuerzo
Aquí hay características importantes del aprendizaje por refuerzo
- No hay supervisor, solo un número real o una señal de recompensa
- Toma de decisiones secuencial
- El tiempo juega un papel crucial en los problemas de refuerzo
- La retroalimentación siempre se retrasa, no es instantánea
- Las acciones del agente determinan los datos posteriores que recibe
Tipos de aprendizaje por refuerzo
Dos tipos de métodos de aprendizaje por refuerzo son:
Positivo:
Se define como un evento, que ocurre debido a un comportamiento específico. Aumenta la fuerza y la frecuencia del comportamiento e impacta positivamente en la acción tomada por el agente.
Este tipo de refuerzo le ayuda a maximizar el rendimiento y mantener el cambio durante un período más prolongado. Sin embargo, un refuerzo excesivo puede llevar a una optimización excesiva del estado, lo que puede afectar a los resultados.
Negativo:
El refuerzo negativo se define como el fortalecimiento del comportamiento que ocurre debido a una condición negativa que debería haberse detenido o evitado. Le ayuda a definir el nivel mínimo de rendimiento. Sin embargo, el inconveniente de este método es que proporciona suficiente para cumplir con el comportamiento mínimo.
Modelos de aprendizaje de Refuerzo
Hay dos modelos de aprendizaje importantes en el aprendizaje de refuerzo:
- Proceso de Decisión de Markov
- Q aprendizaje
Proceso de Decisión de Markov
Los siguientes parámetros se utilizan para obtener una solución:
- Conjunto de acciones-A
- Conjunto de estados-S
- Recompensa – R
- Política-n
- Valor-V
El enfoque matemático para mapear una solución en el aprendizaje por refuerzo es recon como un Proceso de Decisión de Markov o (MDP).
Q-Learning
El aprendizaje Q es un método basado en valores para proporcionar información para informar qué acción debe tomar un agente.
Entendamos este método con el siguiente ejemplo:
- Hay cinco habitaciones en un edificio que están conectadas por puertas.
- Cada habitación está numerada del 0 al 4
- El exterior del edificio puede ser un área exterior grande (5)
- Las puertas número 1 y 4 conducen al edificio desde la habitación 5
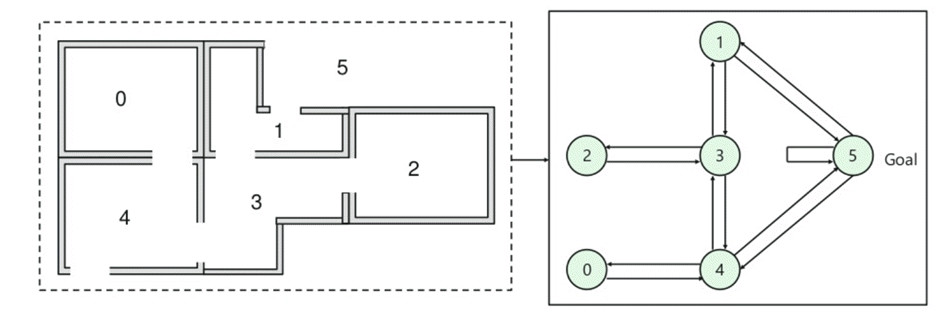
A continuación, debe asociar un valor de recompensa a cada puerta:
- Las puertas que conducen directamente al objetivo tienen una recompensa de 100
- Las puertas que no están conectadas directamente a la habitación objetivo dan cero recompensa
- Ya que las puertas son bidireccionales y se asignan dos flechas para cada habitación
- Cada flecha de la imagen de arriba contiene un valor de recompensa instantáneo
Explicación:
En esta imagen, puede ver que la habitación representa un estado
El movimiento del agente de una habitación a otra representa una acción
En la imagen dada a continuación, un estado se describe como un nodo, mientras que las flechas muestran la acción.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Aprendizaje supervisado
| Parámetros | Aprendizaje por Refuerzo | Aprendizaje Supervisado |
| la Decisión de estilo | aprendizaje por refuerzo le ayuda a tomar sus decisiones de forma secuencial. | En este método, se toma una decisión sobre la entrada dada al principio. |
| Funciona en | Funciona en la interacción con el medio ambiente. | Trabaja con ejemplos o datos de muestra dados. |
| Dependencia de la decisión | En el método RL, la decisión de aprendizaje depende. Por lo tanto, debe dar etiquetas a todas las decisiones dependientes. | Aprendizaje supervisado de las decisiones que son independientes entre sí, por lo que se dan etiquetas para cada decisión. |
| El más adecuado | Soporta y funciona mejor en IA, donde la interacción humana es frecuente. | Se opera principalmente con un sistema de software interactivo o aplicaciones. |
| Ejemplo | Juego de ajedrez | Reconocimiento de objetos |
Aplicaciones de Aprendizaje por refuerzo
Aquí están las aplicaciones de Aprendizaje por refuerzo:
- Robótica para automatización industrial.
- Planificación de estrategias de negocio
- Aprendizaje automático y procesamiento de datos
- Le ayuda a crear sistemas de capacitación que proporcionan instrucción y materiales personalizados de acuerdo con los requisitos de los estudiantes.
- Control de aeronaves y control de movimiento de robots
¿Por qué utilizar el aprendizaje por refuerzo?
Estas son las principales razones para usar el aprendizaje por refuerzo:
- Te ayuda a encontrar qué situación necesita una acción
- Te ayuda a descubrir qué acción produce la recompensa más alta durante un período más largo.
- El aprendizaje por refuerzo también proporciona al agente de aprendizaje una función de recompensa.
- También le permite descubrir el mejor método para obtener grandes recompensas.
¿Cuándo No usar el Aprendizaje por Refuerzo?
No se puede aplicar el modelo de aprendizaje por refuerzo es toda la situación. Estas son algunas condiciones en las que no debe usar el modelo de aprendizaje por refuerzo.
- Cuando tiene suficientes datos para resolver el problema con un método de aprendizaje supervisado
- , debe recordar que el aprendizaje por refuerzo requiere mucho tiempo y mucha informática. en particular, cuando el espacio de acción es grande.
Desafíos del aprendizaje por refuerzo
Estos son los principales desafíos a los que se enfrentará mientras gana refuerzos:
- Diseño de características/recompensas que debe ser muy involucrado
- Los parámetros pueden afectar la velocidad del aprendizaje.
- Los entornos realistas pueden tener observabilidad parcial.
- Demasiado refuerzo puede provocar una sobrecarga de estados que puede disminuir los resultados.
- Los entornos realistas pueden ser no estacionarios.
Resumen:
- El aprendizaje por refuerzo es un método de aprendizaje automático
- Que le ayuda a descubrir qué acción produce la recompensa más alta durante un período más largo.
- Tres métodos para el aprendizaje por refuerzo son 1) Basado en valores 2) Basado en políticas y Aprendizaje basado en modelos.
- Agente, Estado, Recompensa, Entorno, Valor Modelo de función del entorno, Métodos basados en modelos, son algunos términos importantes que se usan en el método de aprendizaje RL
- El ejemplo de aprendizaje por refuerzo es que su gato es un agente que está expuesto al entorno.
- La mayor característica de este método es que no hay supervisor, solo un número real o una señal de recompensa
- Dos tipos de aprendizaje por refuerzo son 1) Positivo 2) Negativo
- Dos modelos de aprendizaje ampliamente utilizados son 1) Proceso de Decisión de Markov 2) Aprendizaje Q
- El método de aprendizaje por refuerzo funciona en la interacción con el entorno, mientras que el método de aprendizaje supervisado funciona en datos de muestra o ejemplos dados.
- Los métodos de aprendizaje de aplicación o refuerzo son: Robótica para automatización industrial y planificación estratégica de negocios
- No debe usar este método cuando tiene suficientes datos para resolver el problema
- El mayor desafío de este método es que los parámetros pueden afectar la velocidad de aprendizaje