No se pueden usar fácilmente variables categóricas como predictores en regresión lineal: es necesario dividirlas en variables dicotómicas conocidas como variables ficticias.La forma ideal de crearlos es nuestra herramienta de variables ficticias. Si no desea utilizar esta herramienta, este tutorial muestra la forma correcta de hacerlo manualmente.
- Ejemplo I – Cualquier Variable Numérica
- Ejemplo II-Variable Numérica con Enteros Adyacentes
- Ejemplo III-Variable de cadena con Conversión
- Ejemplo IV-Variable de cadena sin Conversión
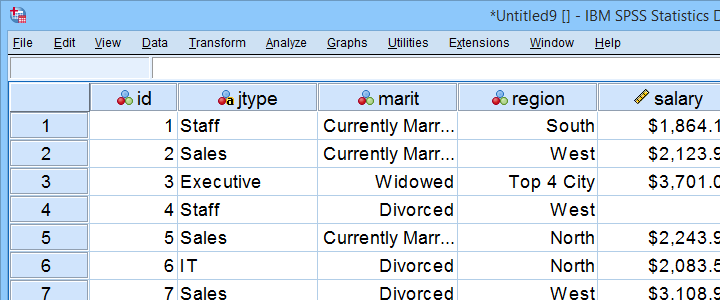
Archivo de datos de ejemplo
Este tutorial utiliza pentagrama.sav todo. Parte de este archivo de datos se muestra a continuación.
Ejemplo I – Cualquier variable numérica
Primero vamos a crear variables ficticias para marit, abreviatura de estado civil. Nuestro primer paso es ejecutar una tabla de frecuencias básicas con frecuencia marit.La siguiente tabla muestra la tabla resultante.
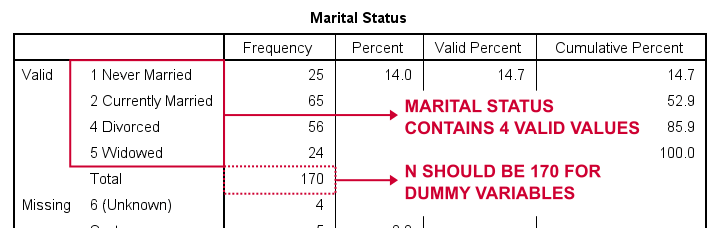
Entonces, ¿cómo dividir el estado civil en variables ficticias? En primer lugar, siempre omitimos una categoría, la categoría de referencia. Puede elegir cualquier categoría como categoría de referencia.
Para este ejemplo, elegimos 5 (Viudo). Esto implica que crearemos 3 variables ficticias que representan las categorías 1, 2 y 4 (tenga en cuenta que 3 no se producen en esta variable).
La sintaxis a continuación muestra cómo crear y etiquetar nuestras 3 variables ficticias. Vamos a comprobarlo.
calcular marit_1 =(marit = 1).
calcular marit_2 =(marit = 2).
calcular marit_4 =(marit = 4).
*Aplicar etiquetas de variables a variables ficticias.etiquetas variables marit_1 » Estado civil = Nunca casado «marit_2» Estado civil = Actualmente casado «marit_4″ Estado civil = Divorciado».
*Comprobación rápida de la primera variable ficticia
frecuencias marit_1.
Resultados
En primer lugar, tenga en cuenta que hemos creado 3 variables ficticias bien etiquetadas en nuestro conjunto de datos activo.
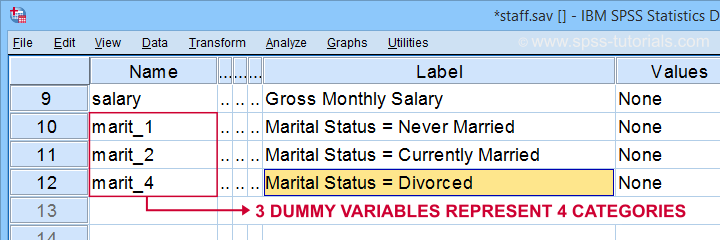
La siguiente tabla muestra la distribución de frecuencia de nuestra primera variable ficticia.

Tenga en cuenta que nuestra variable ficticia contiene 3 valores distintos:
- los encuestados cuyo estado civil no tiene una puntuación de «nunca se casó» de 0;
- los encuestados cuyo estado civil tiene una puntuación de «nunca se casó» de 1;
- los encuestados cuyo estado civil es un valor faltante (y, por lo tanto, desconocido) tienen un valor faltante del sistema.
Ahora podemos comprobar los resultados más a fondo ejecutando crosstabs marit by marit_1 a marit_4.Hacerlo crea 3 tablas de contingencia, la primera de las cuales se muestra a continuación.
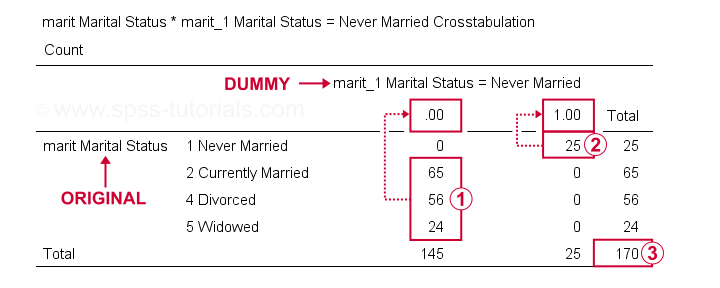
En nuestra variable ficticia,
 los encuestados que tienen otros estados maritales que «nunca se casaron» todos obtuvieron una puntuación 0;
los encuestados que tienen otros estados maritales que «nunca se casaron» todos obtuvieron una puntuación 0;
 los encuestados que «nunca se casaron» todos obtuvieron una puntuación 1;
los encuestados que «nunca se casaron» todos obtuvieron una puntuación 1;
 tenemos un tamaño de muestra de N = 170 (esta tabla solo incluye encuestados sin valores faltantes en ninguna de las variables).
tenemos un tamaño de muestra de N = 170 (esta tabla solo incluye encuestados sin valores faltantes en ninguna de las variables).
Opcionalmente, una comprobación final, muy minuciosa, es comparar los resultados de ANOVA para la variable original con los resultados de regresión utilizando nuestras variables ficticias. La sintaxis a continuación hace precisamente eso, usando el salario mensual como variable dependiente.
*ANOVA mínima usando la variable original.salario único de Marit.
Tenga en cuenta que ambos análisis dan como resultado tablas ANOVA idénticas. Discutiremos ANOVA versus regresión de variables ficticias más a fondo en un tutorial futuro.
Ejemplo II-Variable numérica con Enteros adyacentes
Ahora crearemos variables ficticias para region. Una vez más, comenzamos inspeccionando una tabla de frecuencias mínimas que crearemos ejecutando la región de frecuencias.Esto resulta en la siguiente tabla.
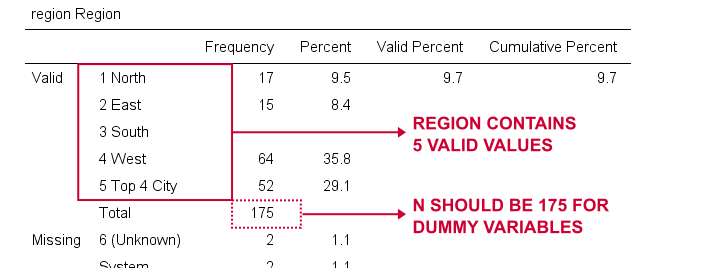
Elegiremos 1 («Norte») como nuestra categoría de referencia. Por lo tanto, crearemos variables ficticias para las categorías 2 a 5. Dado que estos son enteros adyacentes, podemos acelerar las cosas mediante el uso de REPETIR como se muestra a continuación.
fin de impresión repetida.
*Aplicar etiquetas de variables a variables nuevas.
etiquetas de variables
region_2 ‘Region = East’
region_3′ Region = South ‘
region_4′ Region = West ‘
region_5’Region = Top 4 City’.Comprobación rápida.
crosstabs región por region_2 a region_5.
Una inspección cuidadosa de las tablas resultantes confirma que todos los resultados son correctos.
Ejemplo III-Variable de cadena con conversión
Lamentablemente, nuestros primeros 2 métodos no funcionan para variables de cadena como jtype, abreviatura de «tipo de trabajo»). La solución más sencilla es convertirlo en una variable numérica como se explica en SPSS Convertir Cadena a Variable numérica. La sintaxis a continuación utiliza el CÓDIGO AUTOMÁTICO para hacer el trabajo.
autorecode jtype
/ en njtype.* Comprobar el resultado.
frecuencias njtype.
*Establecer valores faltantes.
valores faltantes njtype (1,2).* Vuelva a comprobar el resultado.
frecuencias njtype.
Result

Dado que njtype-abreviatura de» tipo de trabajo numérico » – es una variable numérica, ahora podemos usar el método I o el método II para dividirlo en variables ficticias.
Ejemplo de variable de cadena IV sin conversión
Convertir variables de cadena en numéricas es fácil de crear variables ficticias para ellas. Sin esta conversión, el proceso es engorroso porque SPSS no maneja correctamente los valores faltantes para las variables de cadena. Sin embargo, la sintaxis de abajo hace el trabajo correctamente.
frecuencias jtype.* Chance ‘ (Unknown) ‘en’NA’.recodificar jtype (‘(Unknown) ‘ = ‘NA’).
*Establecer los valores faltantes del usuario.
valores faltantes jtype ( » , ‘NA’).
*Reinspeccionar frecuencias.
frecuencias jtype.
*Crear variables ficticias para la variable de cadena.
if(not missing(jtype)) jtype_1 = (jtype = ‘IT’).
if(not missing(jtype)) jtype_2 = (jtype = ‘Management’).
if(not missing(jtype)) jtype_3 = (jtype = ‘Sales’).
if(not missing(jtype)) jtype_4 = (jtype = ‘Staff’).
*Aplicar etiquetas de variables a variables ficticias.etiquetas de variables jtype_1 ‘Job type = IT ‘
jtype_2’Job type = Management ‘
jtype_3’Job type = Sales ‘
jtype_4’Job type = Staff’.* Compruebe los resultados.
crosstabs jtype de jtype_1 a jtype_4.
Notas finales
La creación de variables ficticias para variables numéricas se puede hacer de forma rápida y sencilla. Sin embargo, establecer etiquetas de variables adecuadas siempre requiere un poco de trabajo. Las variables de cadena requieren algunos pasos adicionales, pero también son bastante factibles.
Sin embargo, la opción más fácil es nuestra herramienta Crear variables Ficticias SPSS, ya que se encarga de todo a la perfección.