Aktivierungsfunktionen sind der wichtigste Teil eines neuronalen Netzwerks im Deep Learning. Beim Deep Learning sind sehr komplizierte Aufgaben Bildklassifizierung, Sprachtransformation, Objekterkennung usw., die mit Hilfe neuronaler Netze und Aktivierungsfunktionen angegangen werden müssen. Ohne sie sind diese Aufgaben also äußerst komplex zu handhaben.
Kurz gesagt, ein neuronales Netzwerk ist eine sehr potente Technik im maschinellen Lernen, die im Grunde imitiert, wie ein Gehirn versteht, wie? Das Gehirn empfängt die Reize als Input aus der Umgebung, verarbeitet sie und produziert den Output entsprechend.
Einführung
Die neuronalen Netzwerkaktivierungsfunktionen sind im Allgemeinen die wichtigste Komponente des tiefen Lernens, sie werden grundsätzlich zur Bestimmung der Ausgabe von Deep-Learning-Modellen, ihrer Genauigkeit und Leistungseffizienz des Trainingsmodells verwendet, das ein riesiges neuronales Netzwerk entwerfen oder teilen kann.
Aktivierungsfunktionen haben erhebliche Auswirkungen auf die Konvergenzfähigkeit und Konvergenzgeschwindigkeit neuronaler Netze hinterlassen, möchten Sie nicht wie? Lassen Sie uns mit einer Einführung in die Aktivierungsfunktion fortfahren, Arten von Aktivierungsfunktionen & ihre Bedeutung und Einschränkungen in diesem Blog.
Was ist die Aktivierungsfunktion?
Die Aktivierungsfunktion definiert die Ausgabe von input oder Set von inputs oder anders ausgedrückt definiert node der Ausgabe von node , die in inputs angegeben ist. Grundsätzlich entscheiden sie, Neuronen zu deaktivieren oder zu aktivieren, um die gewünschte Ausgabe zu erhalten. Es führt auch eine nichtlineare Transformation der Eingabe durch, um bessere Ergebnisse in einem komplexen neuronalen Netzwerk zu erzielen.
Die Aktivierungsfunktion hilft auch, die Ausgabe eines beliebigen Eingangs im Bereich zwischen 1 und -1 zu normalisieren. Diese Funktion muss effizient sein, und es sollte die Rechenzeit reduzieren, weil das neuronale Netzwerk manchmal auf Millionen von Datenpunkten trainiert.
Die Aktivierungsfunktion entscheidet grundsätzlich in jedem neuronalen Netzwerk, ob eine gegebene Eingabe oder empfangende Information relevant oder irrelevant ist. Nehmen wir ein Beispiel, um besser zu verstehen, was ein Neuron ist und wie die Aktivierungsfunktion den Ausgabewert auf ein bestimmtes Limit begrenzt.
Das Neuron ist im Grunde ein gewichteter Durchschnitt der Eingabe, dann wird diese Summe durch eine Aktivierungsfunktion geleitet, um eine Ausgabe zu erhalten.
Y = ∑ (weights*input + bias)
Hier kann Y alles für ein Neuron zwischen Bereich -unendlich bis +unendlich sein. Wir müssen also unsere Ausgabe binden, um die gewünschten Vorhersagen oder verallgemeinerten Ergebnisse zu erhalten.
Y = Aktivierungsfunktion(∑ (Gewichte*Eingabe + Vorspannung))
Wir übergeben also dieses Neuron an die Aktivierungsfunktion, um die Ausgabewerte zu binden.
Warum brauchen wir Aktivierungsfunktionen?
Ohne Aktivierungsfunktion hätten Gewicht und Vorspannung nur eine lineare Transformation, oder das neuronale Netzwerk ist nur ein lineares Regressionsmodell, eine lineare Gleichung ist nur ein Polynom von einem Grad, das einfach zu lösen ist, aber in Bezug auf die Fähigkeit, komplexe Probleme oder Polynome höheren Grades zu lösen, begrenzt ist. Im Gegensatz dazu führt die Hinzufügung einer Aktivierungsfunktion zum neuronalen Netzwerk die nichtlineare Transformation zur Eingabe aus und macht es in der Lage, komplexe Probleme wie Sprachübersetzungen und Bildklassifikationen zu lösen. Darüber hinaus sind Aktivierungsfunktionen differenzierbar, wodurch sie leicht Rückpropagationen implementieren können, optimierte Strategie bei der Durchführung von Backpropagationen zur Messung von Gradientenverlustfunktionen in den neuronalen Netzen.
Arten von Aktivierungsfunktionen
Die bekanntesten Aktivierungsfunktionen sind unten angegeben,
-
Binärschritt
-
Linear
-
ReLU
-
LeakyReLU
-
Sigmoid
-
Tanh
-
Softmax
1. Binary Schritt Aktivierungsfunktion
Diese Aktivierungsfunktion sehr einfach und es kommt jedes Mal in den Sinn, wenn wir versuchen, Ausgabe zu binden. Es ist im Grunde ein Schwellenwert-Basisklassifikator, in diesem entscheiden wir einen Schwellenwert, um zu entscheiden, ob dieses Neuron aktiviert oder deaktiviert werden soll.
f(x) = 1 wenn x > 0 sonst 0 wenn x < 0
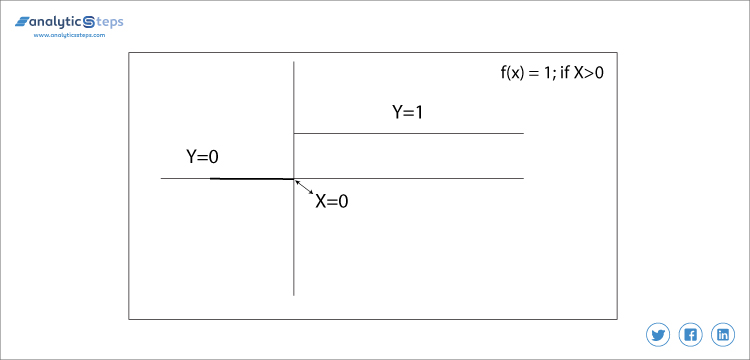
Binäre Schrittfunktion
In diesem legen wir den Schwellenwert auf 0 fest. Es ist sehr einfach und nützlich, binäre Probleme oder Klassifikatoren zu klassifizieren.
2. Lineare Aktivierungsfunktion
Es ist eine einfache gerade Aktivierungsfunktion, bei der unsere Funktion direkt proportional zur gewichteten Summe von Neuronen oder Input ist. Lineare Aktivierungsfunktionen sind besser darin, einen breiten Bereich von Aktivierungen zu ergeben, und eine Linie mit einer positiven Steigung kann die Zündrate erhöhen, wenn die Eingangsrate zunimmt.
Im Binärmodus feuert entweder ein Neuron oder nicht. Wenn Sie den Gradientenabstieg im Deep Learning kennen, würden Sie feststellen, dass in dieser Funktion die Ableitung konstant ist.
Y = mZ
Wobei die Ableitung in Bezug auf Z konstant ist m. Der Bedeutungsgradient ist ebenfalls konstant und hat nichts mit Z zu tun.
In diesem Fall ist unsere zweite Ebene die Ausgabe einer linearen Funktion der vorherigen Ebenen. Warten Sie eine Minute, was haben wir dabei gelernt, dass wir, wenn wir alle Ebenen vergleichen und alle Ebenen außer der ersten und der letzten entfernen, auch nur eine Ausgabe erhalten können, die eine lineare Funktion der ersten Ebene ist.
3. ReLU( Rectified Linear Unit) Aktivierungsfunktion
Rectified Linear Unit oder ReLU ist derzeit die am weitesten verbreitete Aktivierungsfunktion, die von 0 bis unendlich reicht, Alle negativen Werte werden in Null umgewandelt, und diese Konvertierungsrate ist so schnell, dass sie weder richtig abgebildet noch in Daten eingefügt werden kann, was ein Problem verursacht, aber wo es ein Problem gibt, gibt es eine Lösung.
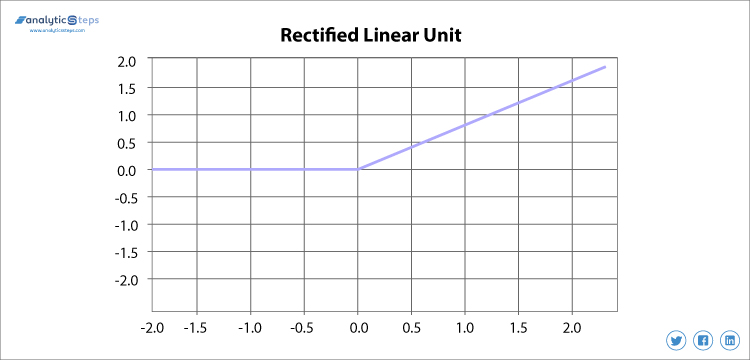
Rektifiziert Linear Einheit aktivierung funktion
Wir verwenden Undichte ReLU funktion anstelle von ReLU zu vermeiden diese unpassende, in Undichte ReLU palette ist erweitert, die verbessert die leistung.
Undichte ReLU-Aktivierungsfunktion
Undichte ReLU-Aktivierungsfunktion
Wir brauchten die undichte ReLU-Aktivierungsfunktion, um das „Sterbende ReLU“ -Problem zu lösen, wie in ReLU diskutiert, Wir beobachten, dass alle negativen Eingabewerte sehr schnell zu Null werden und im Fall von Undichtem ReLU machen wir nicht alle negativen Eingaben auf Null, sondern auf einen Wert nahe Null, der das Hauptproblem der ReLU-Aktivierungsfunktion löst.
Sigmoid-Aktivierungsfunktion
Die Sigmoid-Aktivierungsfunktion wird hauptsächlich verwendet, da sie ihre Aufgabe mit großer Effizienz erfüllt, sie ist im Grunde ein probabilistischer Ansatz zur Entscheidungsfindung und liegt zwischen 0 und 1. Wenn wir also eine Entscheidung treffen oder eine Ausgabe vorhersagen müssen, verwenden wir diese Aktivierungsfunktion, da der Bereich das Minimum ist, daher wäre die Vorhersage genauer.
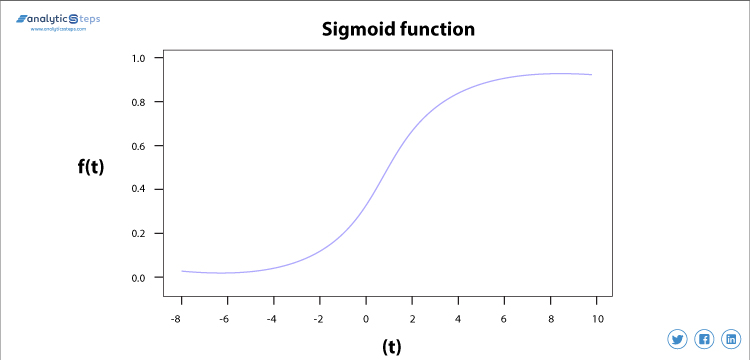
Sigmoid-Aktivierungsfunktion
Die Gleichung für die Sigmoidfunktion lautet
f(x) = 1/(1+e(-x) )
Die Sigmoidfunktion verursacht ein Problem, das hauptsächlich als verschwindendes Gradientenproblem bezeichnet wird, das auftritt, weil wir große Eingaben zwischen dem Bereich von 0 und 1 konvertieren und daher ihre Ableitungen viel kleiner werden, was keine zufriedenstellende Ausgabe ergibt. Um dieses Problem zu lösen, wird eine andere Aktivierungsfunktion wie ReLU verwendet, bei der wir kein kleines Ableitungsproblem haben.
Aktivierungsfunktion der hyperbolischen Tangente(Tanh)
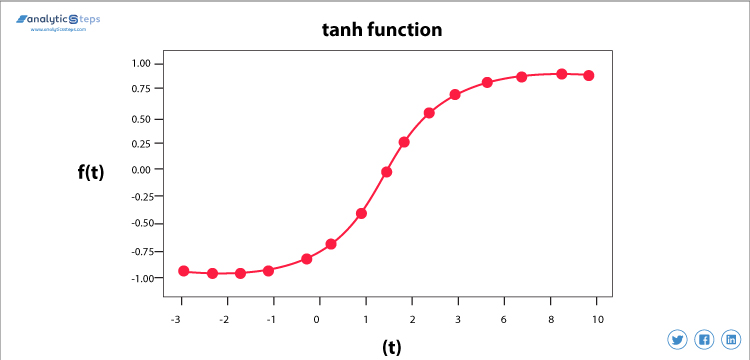
Tanh-Aktivierungsfunktion
Diese Aktivierungsfunktion ist etwas besser als die Sigmoidfunktion, wie die Sigmoidfunktion wird sie auch zur Vorhersage oder Unterscheidung zwischen zwei Klassen verwendet, aber sie bildet den negativen Eingang nur in eine negative Größe ab und liegt zwischen -1 und 1.
Softmax-Aktivierungsfunktion
Softmax wird hauptsächlich an der letzten Schicht i verwendet.e Ausgabeschicht für die Entscheidungsfindung Genauso wie die Sigmoidaktivierung funktioniert, gibt der Softmax der Eingangsvariablen im Grunde einen Wert entsprechend ihrem Gewicht und die Summe dieser Gewichte ist schließlich eins.
Softmax zur binären Klassifizierung
Für die binäre Klassifizierung sind sowohl Sigmoid als auch Softmax gleichermaßen zugänglich, aber im Falle eines Klassifizierungsproblems mit mehreren Klassen verwenden wir im Allgemeinen Softmax und Cross-Entropy .
Fazit
Die Aktivierungsfunktionen sind diejenigen signifikanten Funktionen, die eine nichtlineare Transformation der Eingabe durchführen und es ermöglichen, komplexere Aufgaben zu verstehen und auszuführen. Wir haben diskutiert 7 majorly verwendet aktivierung funktionen mit ihre begrenzung (wenn überhaupt), diese aktivierung funktionen sind verwendet für die gleichen zweck aber in verschiedenen bedingungen.