Versionsinfo: Der Code für diese Seite wurde in Stata 12 getestet.
Die Poisson-Regression wird verwendet, um Zählvariablen zu modellieren.
Bitte beachten Sie: Diese Seite soll zeigen, wie Sie verschiedene Datenanalysebefehle verwenden. Es deckt nicht alle Aspekte des Forschungsprozesses ab, die von Forschern erwartet werden. Sie umfasst insbesondere nicht die Datenbereinigung und -prüfung, die Verifizierung von Annahmen, die Modelldiagnostik oder mögliche Folgeanalysen.
Beispiele für die Poisson-Regression
Beispiel 1. Die Zahl der durch Maultier- oder Pferdetritte getöteten Personen in der preußischen Armee pro Jahr.Ladislaus Bortkiewicz sammelte Daten aus 20 Bänden der Preußischen Statistik. Diese Daten wurden auf 10 Korps der preußischen Armee in den späten 1800er Jahren im Laufe von 20 Jahren gesammelt.
Beispiel 2. Die Anzahl der Personen in der Schlange vor Ihnen im Supermarkt. Prädiktoren können die Anzahl der Artikel umfassen, die derzeit zu einem ermäßigten Sonderpreis angeboten werden, und ob ein besonderes Ereignis (z. B. ein Feiertag, ein großes Sportereignis) drei oder weniger Tage entfernt ist.
Beispiel 3. Die Anzahl der Auszeichnungen, die Schüler an einer High School erhalten haben. Prädiktoren für die Anzahl der Auszeichnungen sind die Art des Programms, in dem der Student eingeschrieben war (z. B. beruflich, allgemein oder akademisch) und die Punktzahl seiner Abschlussprüfung in Mathematik.
Beschreibung der Daten
Zur Veranschaulichung haben wir oben einen Datensatz für Beispiel 3 simuliert. In diesem Beispiel ist num_awards die Ergebnisvariable und gibt die Anzahl der Auszeichnungen an, die Schüler an einer High School in einem Jahr erhalten haben, math ist eine kontinuierliche Prädiktorvariable und stellt die Ergebnisse der Schüler bei ihrer Mathe-Abschlussprüfung dar, und prog ist eine kategoriale Prädiktorvariable mit drei Ebenen, die die Art des Programms angeben, in dem die Schüler eingeschrieben waren.
Beginnen wir mit dem Laden der Daten und dem Betrachten einiger deskriptiver Statistiken.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
Jede Variable hat 200 gültige Beobachtungen und ihre Verteilungen scheinen ziemlich vernünftig zu sein. In diesem speziellen Fall unterscheiden sich der bedingungslose Mittelwert und die Varianz unserer Ergebnisvariablen nicht extrem.
Fahren wir mit der Beschreibung der Variablen in diesem Datensatz fort. Die folgende Tabelle zeigt die durchschnittliche Anzahl der Auszeichnungen nach Programmtyp und scheint darauf hinzudeuten, dass der Programmtyp ein guter Kandidat für die Vorhersage der Anzahl der Auszeichnungen ist, unsere Ergebnisvariable, weil der Mittelwert des Ergebnisses von Prog zu variieren scheint.
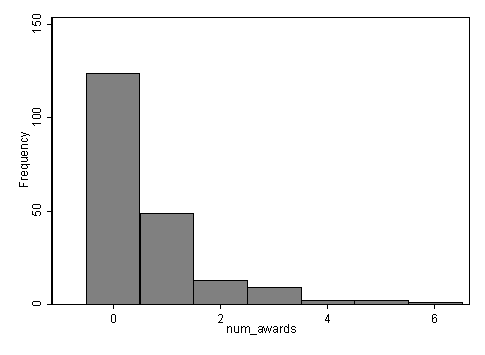
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
Analyse methoden sie
Nachfolgend finden Sie eine Liste einiger Analysemethoden, auf die Sie möglicherweise gestoßen sind. Einige der aufgeführten Methoden sind durchaus sinnvoll, während andere entweder in Ungnade gefallen sind oder Einschränkungen aufweisen.
- Poisson-Regression – Die Poisson-Regression wird häufig zur Modellierung von Zähldaten verwendet. Die Poisson-Regression verfügt über eine Reihe von Erweiterungen, die für Zählmodelle nützlich sind.
- Negative Binomialregression – Eine negative Binomialregression kann für überdispergierte Zähldaten verwendet werden, dh wenn die bedingte Varianz den bedingten Mittelwert überschreitet. Es kann als Verallgemeinerung der Poisson-Regression betrachtet werden, da es die gleiche mittlere Struktur wie die Poisson-Regression hat und einen zusätzlichen Parameter zur Modellierung der Überstreuung hat. Wenn die bedingte Verteilung der Ergebnisvariablen überstreut ist, sind die Konfidenzintervalle für eine negative Binomialregression im Vergleich zu denen aus einer Poisson-Regression wahrscheinlich enger.
- Null-aufgeblähtes Regressionsmodell – Null-aufgeblähte Modelle versuchen, überschüssige Nullen zu berücksichtigen. Mit anderen Worten, es wird angenommen, dass zwei Arten von Nullen in den Daten vorhanden sind, „echte Nullen“ und „überschüssige Nullen“. Nullpunktmodelle schätzen zwei Gleichungen gleichzeitig, eine für das Zählmodell und eine für die überschüssigen Nullen.
- OLS-Regression – Ergebnisvariablen werden manchmal log-transformiert und mithilfe der OLS-Regression analysiert. Bei diesem Ansatz treten viele Probleme auf, einschließlich Datenverlust aufgrund undefinierter Werte, die durch das Protokoll von Null (das undefiniert ist) und voreingenommene Schätzungen generiert werden.
Poisson-Regression
Im Folgenden verwenden wir den Befehl poisson, um ein Poisson-Regressionsmodell zu schätzen. Das i. before prog zeigt an, dass es sich um eine Faktorvariable handelt (d.h., kategoriale Variable), und dass sie als eine Reihe von Indikatorvariablen in das Modell aufgenommen werden sollte.
Wir verwenden die Option vce(robust), um robuste Standardfehler für die Parameterschätzungen zu erhalten, wie von Cameron und Trivedi (2009) empfohlen, um eine leichte Verletzung der zugrunde liegenden Annahmen zu kontrollieren.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
Um die Anpassung des Modells zu beurteilen, kann der Befehl estat gof verwendet werden, um den Chi-Quadrat-Test für die Güte der Anpassung zu erhalten. Dies ist kein Test der Modellkoeffizienten (den wir in den Kopfzeileninformationen gesehen haben), sondern ein Test der Modellform: Passt die Poisson-Modellform zu unseren Daten?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
Wir schließen daraus, dass das Modell einigermaßen gut passt, da der Chi-Quadrat-Test der Anpassungsgüte statistisch nicht signifikant ist. Wenn der Test statistisch signifikant gewesen wäre, würde dies darauf hindeuten, dass die Daten nicht gut zum Modell passen. In dieser Situation können wir versuchen festzustellen, ob Prädiktorvariablen weggelassen wurden, ob unsere Linearitätsannahme zutrifft und / oder ob ein Problem der Überstreuung vorliegt.
Manchmal möchten wir die Regressionsergebnisse als incident Rate ratios darstellen, wir können ihre eigene Option verwenden. Diese IRR-Werte werden gleich unseren Koeffizienten aus der obigen Ausgabe potenziert.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
Die obige Ausgabe zeigt an, dass die Ereignisrate für 2.prog ist das 2,96-fache der Incident-Rate für die Referenzgruppe (1.Progrock). Ebenso ist die Incident Rate für 3.prog ist das 1,45-fache der Incident-Rate für die Referenzgruppe, die die anderen Variablen konstant hält. Die prozentuale Änderung der Incident-Rate von num_awards ist eine Erhöhung von 7% für jede Erhöhung der Einheit in math.
Erinnern Sie sich an die Form unserer Modellgleichung:
log(num_awards) = Abfangen + b1(prog=2) + b2(prog=3) + b3math.
Dies impliziert:
num_awards = exp(Abschnitt + b1(prog=2) + b2(prog=3)+ b3math) = exp(Abschnitt) * exp(b1(prog=2)) * exp(b2(prog=3)) * exp(b3math)
Die Koeffizienten haben einen additiven Effekt in der log (y) -Skala und der IRR einen multiplikativen Effekt in der y-Skala. Weitere Informationen zu den verschiedenen Metriken, in denen die Ergebnisse dargestellt werden können, und deren Interpretation finden Sie unter Regressionsmodelle für kategoriale abhängige Variablen mit Stata, Zweite Ausgabe von J. Scott Long und Jeremy Freese (2006).
Um das Modell besser zu verstehen, können wir den Befehl margins verwenden. Im Folgenden verwenden wir den Befehl margins, um die vorhergesagten Zählungen auf jeder Ebene vonprog zu berechnen und alle anderen Variablen (in diesem Beispiel math) im Modell auf ihren Mittelwerten zu halten.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
In der obigen Ausgabe sehen wir, dass die vorhergesagte Anzahl von Ereignissen für Level 1 von prog ungefähr ist .21, halten Mathematik an seinem Mittelwert. Die vorhergesagte Anzahl von Ereignissen für Level 2 von prog ist höher bei .62, und die vorhergesagte Anzahl von Ereignissen für Level 3 von prog ist ungefähr .31. Beachten Sie, dass die vorhergesagte Anzahl von Level 2 von prog (.6249446/.211411) = 2,96 mal höher als die vorhergesagte Anzahl für Stufe 1 von prog. Dies entspricht dem, was wir in der IRR-Ausgabetabelle gesehen haben.
Im Folgenden erhalten wir die vorhergesagten Zählungen für mathematische Werte im Bereich von 35 bis 75 in Schritten von 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
Die obige Tabelle zeigt, dass mit prog bei seinen beobachteten Werten und Mathematik bei 35 für alle Beobachtungen die durchschnittliche vorhergesagte Anzahl (oder durchschnittliche Anzahl von Auszeichnungen) ungefähr ist .13; Wenn math = 75 ist, beträgt die durchschnittliche vorhergesagte Anzahl etwa 2,17. Wenn wir die vorhergesagten Zählungen bei math = 35 und math = 45 vergleichen, können wir sehen, dass das Verhältnis (.2644714/.1311326) = 2.017. Dies entspricht dem IRR von 1,0727 für eine Änderung von 10 Einheiten: 1,0727 ^ 10 = 2,017.
Der vom Benutzer geschriebene fitstat-Befehl (sowie die estat-Befehle von Stata) können verwendet werden, um zusätzliche Informationen zu erhalten, die hilfreich sein können, wenn Sie Modelle vergleichen möchten. Sie können search fitstat eingeben, um dieses Programm herunterzuladen (siehe Wie kann ich den Suchbefehl verwenden, um nach Programmen zu suchen und zusätzliche Hilfe zu erhalten? weitere Informationen zur Verwendung der Suche).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
Mit den folgenden Befehlen können Sie die vorhergesagte Anzahl von Ereignissen grafisch darstellen. Die Grafik zeigt, dass die meisten Auszeichnungen für diejenigen im akademischen Programm (prog = 2) vorhergesagt werden, insbesondere wenn der Schüler eine hohe mathematische Punktzahl hat. Die niedrigste Anzahl vorhergesagter Auszeichnungen gilt für die Studenten des allgemeinen Programms (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
Dinge zu beachten
- Wenn eine Überdispersion ein Problem zu sein scheint, sollten wir zuerst prüfen, ob unser Modell angemessen spezifiziert ist, wie ausgelassene Variablen und funktionale Formen. Wenn wir beispielsweise die Prädiktorvariable progim obigen Beispiel weglassen, scheint unser Modell ein Problem mit der Überstreuung zu haben. Mit anderen Worten, ein falsch spezifiziertes Modell könnte ein Symptom wie ein Überstreuungsproblem darstellen.
- Unter der Annahme, dass das Modell korrekt angegeben ist, sollten Sie foroverdispersion überprüfen. Es gibt mehrere Möglichkeiten, dies zu tun, einschließlich des Likelihood Ratio-Tests des Überdispersionsparameters alpha, indem dasselbe Regressionsmodell unter Verwendung der negativen Binomialverteilung (nbreg) ausgeführt wird.
- Eine häufige Ursache für Überstreuung sind überschüssige Nullen, die wiederum durch einen zusätzlichen Datengenerierungsprozess erzeugt werden. In dieser Situation sollte ein Null-aufgeblasenes Modell in Betracht gezogen werden.
- Wenn der Datengenerierungsprozess keine 0s zulässt (z. B. die Anzahl der im Krankenhaus verbrachten Tage), ist ein Null-verkürztes Modell möglicherweise besser geeignet.
- Zähldaten haben oft eine Expositionsvariable, die angibt, wie oft das Ereignis hätte passieren können. Diese Variable sollte mit der Option exp() in ein Poisson-Modell aufgenommen werden.
- Die Ergebnisvariable in einer Poisson-Regression darf keine negativen Zahlen haben, und die Exposition darf keine 0s haben.
- In Stata kann ein Poisson-Modell über den glm-Befehl mit dem Log-Link und der Poisson-Familie geschätzt werden.
- Sie müssen den Befehl glm verwenden, um die Residuen zu erhalten, um andere Annahmen des Poisson-Modells zu überprüfen (siehe Cameron und Trivedi (1998) und Dupont (2002) für weitere Informationen).
- Es gibt viele verschiedene Maße von Pseudo-R-Quadrat. Sie alle versuchen, Informationen bereitzustellen, die denen von R-squared in der OLS-Regression ähneln, obwohl keine von ihnen genau so interpretiert werden kann, wie R-squared in der OLS-Regression interpretiert wird. Für eine Diskussion verschiedener Pseudo-R-Quadrate siehe Long and Freese (2006) oder unsere FAQ-Seite Was sind Pseudo-R-Quadrate?.
- Die Poisson-Regression wird mittels Maximum-Likelihood-Schätzung geschätzt. Es erfordert normalerweise eine große Stichprobengröße.
Siehe auch
- Kommentierte Ausgabe für den Poisson-Befehl
- Stata FAQ: Wie kann ich countfit bei der Auswahl eines Zählmodells verwenden?
- Stata online manual
- poisson
- Stata FAQs
- Wie werden die Standardfehler und Konfidenzintervalle für Inzidenz-Raten-Verhältnisse (IRRs) von Poisson und nbreg berechnet?
- Cameron, A. C. und Trivedi, P. K. (2009). Mikroökonometrie mit Stata. In: College Station, TX: Stata Press.
- Cameron, A. C. und Trivedi, P. K. (1998). Regressionsanalyse von Zähldaten. New York: Cambridge Press.Cameron, A. C. Fortschritte in der Zähldatenregression Vortrag für den Applied Statistics Workshop, 28. März 2009.http://cameron.econ.ucdavis.edu/racd/count.html .
- Dupont, W. D. (2002). Statistische Modellierung für biomedizinische Forscher: Eine einfache Einführung in die Analyse komplexer Daten. New York: Cambridge Press.
- Lange, JS (1997). Regressionsmodelle für kategoriale und begrenzte abhängige Variablen.In: Thousand Oaks, CA: Sage Publications.
- Long, J. S. und Freese, J. (2006). Regressionsmodelle für kategoriale abhängige Variablen mit Stata, Zweite Auflage. In: College Station, TX: Stata Press.