Lineare Diskriminanzanalyse oder normale Diskriminanzanalyse oder Diskriminanzfunktionsanalyse ist eine Dimensionalitätsreduktionstechnik, die üblicherweise für die überwachten Klassifizierungsprobleme verwendet wird. Es wird zur Modellierung von Unterschieden in Gruppen verwendet, d. H. Zur Trennung von zwei oder mehr Klassen. Es wird verwendet, um die Features in einem Raum mit höherer Dimension in einen Raum mit niedrigerer Dimension zu projizieren.
Zum Beispiel haben wir zwei Klassen und wir müssen sie effizient trennen. Klassen können mehrere Funktionen haben. Wenn Sie nur ein einzelnes Feature verwenden, um sie zu klassifizieren, kann es zu Überlappungen kommen, wie in der folgenden Abbildung gezeigt. Daher werden wir die Anzahl der Funktionen für eine ordnungsgemäße Klassifizierung weiter erhöhen.

Beispiel:
Angenommen, wir haben zwei Sätze von Datenpunkten, die zu zwei verschiedenen Klassen gehören, die wir klassifizieren möchten. Wie im angegebenen 2D-Diagramm gezeigt, gibt es beim Zeichnen der Datenpunkte in der 2D-Ebene keine gerade Linie, die die beiden Klassen der Datenpunkte vollständig trennen kann. Daher wird in diesem Fall LDA (Lineare Diskriminanzanalyse) verwendet, die den 2D-Graphen in einen 1D-Graphen reduziert, um die Trennbarkeit zwischen den beiden Klassen zu maximieren.
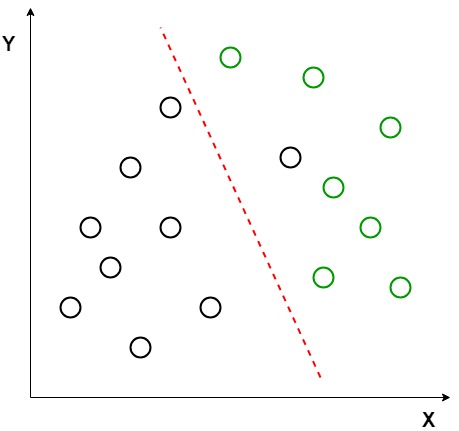
Hier verwendet die lineare Diskriminanzanalyse beide Achsen (X und Y), um eine neue Achse zu erstellen, und projiziert Daten auf eine neue Achse, um die Trennung der beiden Kategorien zu maximieren und somit den 2D-Graphen in einen 1D-Graphen zu reduzieren.
LDA verwendet zwei Kriterien, um eine neue Achse zu erstellen:
- Maximiere den Abstand zwischen den Mittelwerten der beiden Klassen.
- Minimiere die Variation innerhalb jeder Klasse.
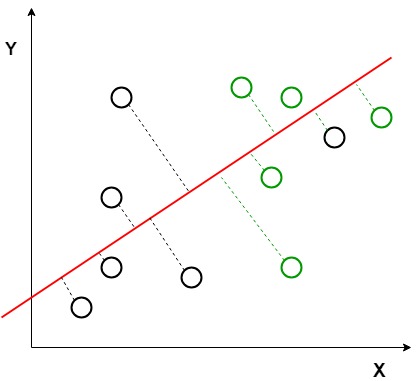
In der obigen Grafik ist zu sehen, dass eine neue Achse (in rot) erzeugt und in der 2D-Grafik so gezeichnet wird, dass sie den Abstand zwischen den Mitteln der beiden Klassen maximiert und die Variation innerhalb jeder Klasse minimiert. Vereinfacht ausgedrückt vergrößert diese neu erzeugte Achse den Abstand zwischen den dtla-Punkten der beiden Klassen. Nach dem Generieren dieser neuen Achse unter Verwendung der oben genannten Kriterien werden alle Datenpunkte der Klassen auf dieser neuen Achse aufgetragen und in der folgenden Abbildung dargestellt.

Die lineare Diskriminanzanalyse schlägt jedoch fehl, wenn der Mittelwert der Verteilungen geteilt wird, da es für LDA unmöglich wird, eine neue Achse zu finden, die beide Klassen linear trennbar macht. In solchen Fällen verwenden wir die nichtlineare Diskriminanzanalyse.
Erweiterungen zu LDA:
- Quadratische Diskriminanzanalyse (QDA): Jede Klasse verwendet ihre eigene Varianzschätzung (oder Kovarianz, wenn mehrere Eingabevariablen vorhanden sind).
- Flexible Diskriminanzanalyse (FDA): Hier werden nichtlineare Kombinationen von Eingaben wie Splines verwendet.
- Regularisierte Diskriminanzanalyse (RDA): Führt eine Regularisierung in die Schätzung der Varianz (eigentlich Kovarianz) ein und moderiert den Einfluss verschiedener Variablen auf die LDA.
Anwendungen:
- Gesichtserkennung: Im Bereich der Computer Vision ist die Gesichtserkennung eine sehr beliebte Anwendung, bei der jedes Gesicht durch eine sehr große Anzahl von Pixelwerten dargestellt wird. Die lineare Diskriminanzanalyse (LDA) wird hier verwendet, um die Anzahl der Merkmale vor dem Klassifizierungsprozess auf eine überschaubarere Anzahl zu reduzieren. Jede der neu erzeugten Dimensionen ist eine lineare Kombination von Pixelwerten, die eine Vorlage bilden. Die linearen Kombinationen, die mit der linearen Diskriminante von Fisher erhalten werden, werden Fisher-Flächen genannt.
- Medizinisch: In diesem Bereich wird die lineare Diskriminanzanalyse (LDA) verwendet, um den Krankheitszustand des Patienten als mild, mittelschwer oder schwer zu klassifizieren, basierend auf den verschiedenen Parametern des Patienten und der medizinischen Behandlung, die er durchläuft. Dies hilft den Ärzten, das Tempo ihrer Behandlung zu intensivieren oder zu reduzieren.
- Kundenidentifikation: Angenommen, wir möchten die Art von Kunden identifizieren, die am wahrscheinlichsten ein bestimmtes Produkt in einem Einkaufszentrum kaufen. Durch eine einfache Umfrage zu Fragen und Antworten können wir alle Funktionen der Kunden sammeln. Hier hilft uns die lineare Diskriminanzanalyse, die Merkmale zu identifizieren und auszuwählen, die die Merkmale der Gruppe von Kunden beschreiben können, die dieses bestimmte Produkt am wahrscheinlichsten im Einkaufszentrum kaufen.
