von William W Wold
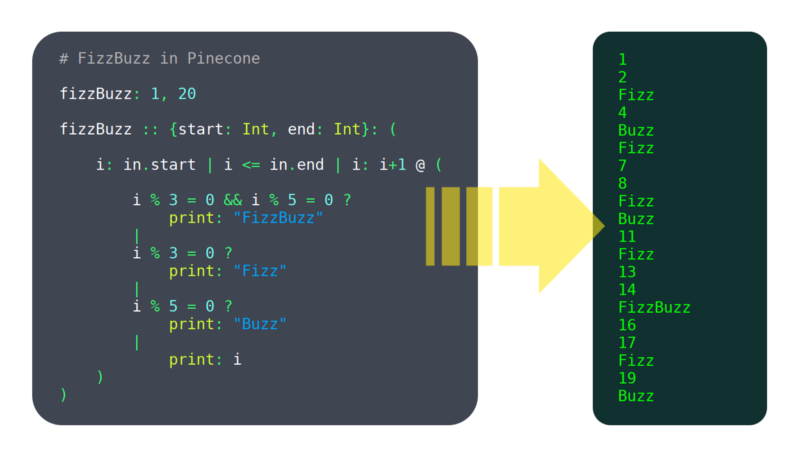
In den letzten 6 Monaten habe ich an einer Programmiersprache namens Pinecone gearbeitet. Ich würde es noch nicht als ausgereift bezeichnen, aber es hat bereits genug Funktionen, um verwendbar zu sein, wie zum Beispiel:
- Variablen
- Funktionen
- benutzerdefinierte Strukturen
Wenn Sie daran interessiert sind, schauen Sie sich die Landing Page von Pinecone oder das GitHub-Repo an.
Ich bin kein Experte. Als ich mit diesem Projekt anfing, hatte ich keine Ahnung, was ich tat, und ich weiß es immer noch nicht. Ich habe null Kurse zur Spracherstellung besucht, online nur ein bisschen darüber gelesen und nicht viel von den Ratschlägen befolgt, die mir gegeben wurden.
Und trotzdem habe ich eine völlig neue Sprache gemacht. Und es funktioniert. Also muss ich etwas richtig machen.
In diesem Beitrag tauche ich unter die Haube und zeige Ihnen die Pipeline, mit der Pinecone (und andere Programmiersprachen) Quellcode in Magie verwandeln.
Ich werde auch auf einige der Kompromisse eingehen, die ich gemacht habe, und warum ich die Entscheidungen getroffen habe, die ich getroffen habe.
Dies ist keineswegs ein vollständiges Tutorial zum Schreiben einer Programmiersprache, aber es ist ein guter Ausgangspunkt, wenn Sie neugierig auf die Sprachentwicklung sind.
Erste Schritte
„Ich habe absolut keine Ahnung, wo ich überhaupt anfangen würde“ höre ich oft, wenn ich anderen Entwicklern erzähle, dass ich eine Sprache schreibe. Falls das Ihre Reaktion ist, werde ich jetzt einige erste Entscheidungen und Schritte durchgehen, die beim Starten einer neuen Sprache getroffen werden.
Kompiliert vs interpretiert
Es gibt zwei Haupttypen von Sprachen: kompiliert und interpretiert:
- Ein Compiler findet alles heraus, was ein Programm tun wird, wandelt es in „Maschinencode“ um (ein Format, das der Computer sehr schnell ausführen kann) und speichert es dann, um es später auszuführen.
- Ein Interpreter durchläuft den Quellcode Zeile für Zeile und findet heraus, was er tut.
Technisch gesehen könnte jede Sprache kompiliert oder interpretiert werden, aber die eine oder andere ist normalerweise für eine bestimmte Sprache sinnvoller. Im Allgemeinen ist das Interpretieren tendenziell flexibler, während das Kompilieren tendenziell eine höhere Leistung aufweist. Dies kratzt jedoch nur an der Oberfläche eines sehr komplexen Themas.
Ich lege großen Wert auf Leistung, und ich sah einen Mangel an Programmiersprachen, die sowohl hohe Leistung und Einfachheit orientiert sind, so ging ich mit compiled for Pinecone.
Dies war eine wichtige Entscheidung, die frühzeitig getroffen werden musste, da viele Sprachdesignentscheidungen davon betroffen sind (zum Beispiel ist statische Typisierung ein großer Vorteil für kompilierte Sprachen, aber nicht so sehr für interpretierte).
Trotz der Tatsache, dass Pinecone für das Kompilieren entwickelt wurde, verfügt es über einen voll funktionsfähigen Interpreter, der die einzige Möglichkeit war, ihn für eine Weile auszuführen. Dafür gibt es eine Reihe von Gründen, die ich später erläutern werde.
Eine Sprache auswählen
Ich weiß, es ist ein bisschen Meta, aber eine Programmiersprache ist selbst ein Programm, und daher müssen Sie es in einer Sprache schreiben. Ich entschied mich für C ++ wegen seiner Leistung und großen Funktionsumfang. Außerdem arbeite ich gerne in C ++.
Wenn Sie eine interpretierte Sprache schreiben, ist es sehr sinnvoll, sie in einer kompilierten Sprache (wie C, C ++ oder Swift) zu schreiben, da der Leistungsverlust in der Sprache Ihres Dolmetschers und des Dolmetschers, der Ihren Dolmetscher interpretiert, zunimmt.
Wenn Sie kompilieren möchten, ist eine langsamere Sprache (wie Python oder JavaScript) akzeptabler. Kompilierzeit kann schlecht sein, aber meiner Meinung nach ist das nicht annähernd so groß wie schlechte Laufzeit.
High Level Design
Eine Programmiersprache ist im Allgemeinen als Pipeline strukturiert. Das heißt, es hat mehrere Stufen. Jede Stufe enthält Daten, die auf eine bestimmte, genau definierte Weise formatiert sind. Es hat auch Funktionen, um Daten von jeder Stufe zur nächsten zu transformieren.
Die erste Stufe ist ein String, der die gesamte Eingabequelldatei enthält. Die letzte Stufe ist etwas, das ausgeführt werden kann. Dies wird alles klar, wenn wir Schritt für Schritt durch die Pinecone-Pipeline gehen.
Lexing

Der erste Schritt in den meisten Programmiersprachen ist Lexing oder Tokenizing. ‚Lex‘ ist die Abkürzung für Lexical Analysis, ein sehr ausgefallenes Wort, um eine Reihe von Text in Token aufzuteilen. Das Wort ‚Tokenizer‘ macht viel mehr Sinn, aber ‚Lexer‘ macht so viel Spaß zu sagen, dass ich es trotzdem benutze.
Tokens
Ein Token ist eine kleine Einheit einer Sprache. Ein Token kann ein Variablen- oder Funktionsname (auch Bezeichner genannt), ein Operator oder eine Zahl sein.
Aufgabe des Lexers
Der Lexer soll eine Zeichenfolge aufnehmen, die eine ganze Datei im Wert von Quellcode enthält, und eine Liste mit jedem Token ausspucken.
Zukünftige Phasen der Pipeline werden nicht auf den ursprünglichen Quellcode verweisen, daher muss der Lexer alle von ihnen benötigten Informationen erzeugen. Der Grund für dieses relativ strenge Pipeline-Format ist, dass der Lexer Aufgaben wie das Entfernen von Kommentaren oder das Erkennen, ob etwas eine Zahl oder ein Bezeichner ist, ausführen kann. Sie möchten diese Logik im Lexer behalten, damit Sie beim Schreiben des Restes der Sprache nicht über diese Regeln nachdenken müssen und diese Art von Syntax an einem Ort ändern können.
Flex
An dem Tag, als ich mit der Sprache anfing, war das erste, was ich schrieb, ein einfacher Lexer. Bald darauf lernte ich Werkzeuge kennen, die das Lexing angeblich einfacher und weniger fehlerhaft machen würden.
Das vorherrschende Tool ist Flex, ein Programm, das Lexer generiert. Sie geben ihm eine Datei, die eine spezielle Syntax hat, um die Grammatik der Sprache zu beschreiben. Daraus generiert es ein C-Programm, das einen String lext und die gewünschte Ausgabe erzeugt.
Meine Entscheidung
Ich habe mich entschieden, den von mir geschriebenen Lexer vorerst beizubehalten. Am Ende habe ich keine signifikanten Vorteile bei der Verwendung von Flex gesehen, zumindest nicht genug, um das Hinzufügen einer Abhängigkeit und das Komplizieren des Erstellungsprozesses zu rechtfertigen.
Mein Lexer ist nur ein paar hundert Zeilen lang und bereitet mir selten Probleme. Das Rollen meines eigenen Lexers bietet mir auch mehr Flexibilität, z. B. die Möglichkeit, der Sprache einen Operator hinzuzufügen, ohne mehrere Dateien bearbeiten zu müssen.
Parsen

Die zweite Stufe der Pipeline ist der Parser. Der Parser wandelt eine Liste von Token in einen Knotenbaum um. Ein Baum, der zum Speichern dieser Art von Daten verwendet wird, wird als abstrakter Syntaxbaum oder AST bezeichnet. Zumindest in Pinecone hat der AST keine Informationen über Typen oder welche Bezeichner welche sind. Es ist einfach Token strukturiert.
Aufgaben des Parsers
Der Parser fügt der geordneten Liste der Token, die der Lexer erzeugt, eine Struktur hinzu. Um Mehrdeutigkeiten zu vermeiden, muss der Parser Klammern und die Reihenfolge der Operationen berücksichtigen. Das einfache Parsen von Operatoren ist nicht besonders schwierig, aber wenn mehr Sprachkonstrukte hinzugefügt werden, kann das Parsen sehr komplex werden.
Bison
Wieder gab es eine Entscheidung, die eine Drittanbieterbibliothek einbezog. Die vorherrschende Parsing-Bibliothek ist Bison. Bison arbeitet viel wie Flex. Sie schreiben eine Datei in einem benutzerdefinierten Format, in dem die Grammatikinformationen gespeichert sind, und Bison verwendet diese, um ein C-Programm zu generieren, das Ihre Analyse durchführt. Ich habe mich nicht für Bison entschieden.
Warum Custom besser ist
Mit dem Lexer war die Entscheidung, meinen eigenen Code zu verwenden, ziemlich offensichtlich. Ein Lexer ist ein so triviales Programm, dass es sich fast so albern anfühlte, kein eigenes zu schreiben, als nicht mein eigenes ‚Left-Pad‘ zu schreiben.
Mit dem Parser ist es eine andere Sache. Mein Tannenzapfen-Parser ist derzeit 750 Zeilen lang, und ich habe drei davon geschrieben, weil die ersten beiden Müll waren.
Ich habe meine Entscheidung ursprünglich aus einer Reihe von Gründen getroffen, und obwohl es nicht ganz reibungslos gelaufen ist, gelten die meisten von ihnen. Die wichtigsten sind wie folgt:
- Minimieren Sie den Kontextwechsel im Workflow: Der Kontextwechsel zwischen C ++ und Pinecone ist schlimm genug, ohne Bisons Grammatik einzugeben Grammatik
- Build einfach halten: Jedes Mal, wenn sich die Grammatik ändert, muss Bison vor dem Build ausgeführt werden. Dies kann automatisiert werden, wird jedoch beim Umschalten zwischen Build-Systemen zu einem Problem.
- Ich mag es, coole Scheiße zu bauen: Ich habe Pinecone nicht gemacht, weil ich dachte, es wäre einfach, also warum sollte ich eine zentrale Rolle delegieren, wenn ich es selbst tun könnte? Ein benutzerdefinierter Parser ist möglicherweise nicht trivial, aber vollständig machbar.
Am Anfang war ich mir nicht ganz sicher, ob ich einen gangbaren Weg einschlagen würde, aber ich war zuversichtlich, was Walter Bright (ein Entwickler einer frühen Version von C ++ und der Schöpfer der D-Sprache) zu diesem Thema zu sagen hatte:
„Etwas umstrittener würde ich keine Zeit mit Lexer- oder Parsergeneratoren und anderen sogenannten „Compiler-Compilern“ verschwenden.“ Sie sind Zeitverschwendung. Das Schreiben eines Lexers und Parsers ist ein winziger Prozentsatz des Schreibens eines Compilers. Die Verwendung eines Generators nimmt ungefähr so viel Zeit in Anspruch wie das Schreiben von Hand und verbindet Sie mit dem Generator (was beim Portieren des Compilers auf eine neue Plattform wichtig ist). Und Generatoren haben auch den unglücklichen Ruf, miese Fehlermeldungen auszusenden.“
Aktionsbaum
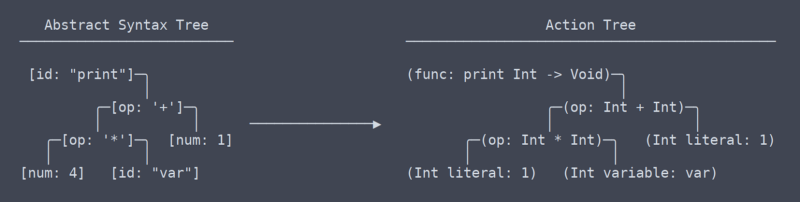
Wir haben jetzt den Bereich der allgemeinen, universellen Begriffe verlassen, oder zumindest weiß ich nicht mehr, was die Begriffe sind. Nach meinem Verständnis ähnelt das, was ich den ‚Aktionsbaum‘ nenne, am ehesten der IR (Intermediate Representation) von LLVM.
Es gibt einen subtilen, aber sehr signifikanten Unterschied zwischen dem Aktionsbaum und dem abstrakten Syntaxbaum. Ich habe eine ganze Weile gebraucht, um herauszufinden, dass es sogar einen Unterschied zwischen ihnen geben sollte (was dazu beitrug, dass der Parser neu geschrieben werden musste).
Aktionsbaum vs AST
Einfach ausgedrückt ist der Aktionsbaum der AST mit Kontext. Dieser Kontext sind Informationen wie der Typ, den eine Funktion zurückgibt, oder dass zwei Stellen, an denen eine Variable verwendet wird, tatsächlich dieselbe Variable verwenden. Da dieser Kontext herausgefunden und gespeichert werden muss, benötigt der Code, der den Aktionsbaum generiert, viele Namespace-Lookup-Tabellen und andere thingamabobs.
Ausführen des Aktionsbaums
Sobald wir den Aktionsbaum haben, ist das Ausführen des Codes einfach. Jeder Aktionsknoten verfügt über eine Funktion ‚execute‘, die Eingaben entgegennimmt, alles tut, was die Aktion soll (einschließlich möglicherweise des Aufrufs einer Unteraktion), und die Ausgabe der Aktion zurückgibt. Dies ist der Dolmetscher in Aktion.
Kompilierungsoptionen
„Aber warte!“ Ich höre dich sagen: „Soll Pinecone das nicht?“ Ja, das ist es. Aber Kompilieren ist schwieriger als interpretieren. Es gibt einige mögliche Ansätze.
Meinen eigenen Compiler bauen
Dasklang zunächst nach einer guten Idee für mich. Ich liebe es, Dinge selbst zu machen, und ich habe nach einer Ausrede gesucht, um gut in der Montage zu werden.
Leider ist das Schreiben eines portablen Compilers nicht so einfach wie das Schreiben von Maschinencode für jedes Sprachelement. Aufgrund der Anzahl der Architekturen und Betriebssysteme ist es für jeden Einzelnen unpraktisch, ein plattformübergreifendes Compiler-Backend zu schreiben.
Selbst die Teams hinter Swift, Rust und Clang wollen sich nicht alleine darum kümmern, also benutzen sie alle…
LLVM
LLVM ist eine Sammlung von Compiler-Tools. Es ist im Grunde eine Bibliothek, die Ihre Sprache in eine kompilierte ausführbare Binärdatei verwandelt. Es schien die perfekte Wahl zu sein, also sprang ich direkt ein. Leider habe ich nicht überprüft, wie tief das Wasser war und bin sofort ertrunken.
LLVM ist zwar keine Assemblersprache, aber eine komplexe Bibliothek. Es ist nicht unmöglich zu verwenden, und sie haben gute Tutorials, aber mir wurde klar, dass ich etwas Übung brauchen würde, bevor ich bereit war, einen Pinecone-Compiler damit vollständig zu implementieren.
Transpiling
Ich wollte eine Art kompilierten Tannenzapfen und ich wollte es schnell, also wandte ich mich einer Methode zu, von der ich wusste, dass ich sie zum Laufen bringen konnte: Transpiling.
Ich habe einen Tannenzapfen in den C ++ – Transpiler geschrieben und die Möglichkeit hinzugefügt, die Ausgabequelle automatisch mit GCC zu kompilieren. Dies funktioniert derzeit für fast alle Pinecone-Programme (obwohl es einige Randfälle gibt, die es brechen). Es ist keine besonders tragbare oder skalierbare Lösung, aber es funktioniert vorerst.
Zukunft
Angenommen, ich entwickle Pinecone weiter, wird es früher oder später LLVM-Kompilierungsunterstützung erhalten. Ich vermute, egal wie viel ich daran arbeite, der Transpiler wird niemals vollständig stabil sein und die Vorteile von LLVM sind zahlreich. Es ist nur eine Frage der Zeit, wann ich Zeit habe, einige Beispielprojekte in LLVM zu erstellen und den Dreh raus zu bekommen.
Bis dahin ist der Interpreter ideal für triviale Programme und C ++ Transpiling funktioniert für die meisten Dinge, die mehr Leistung benötigen.
Fazit
Ich hoffe, ich habe Programmiersprachen für Sie etwas weniger mysteriös gemacht. Wenn Sie selbst eine machen wollen, empfehle ich es sehr. Es gibt eine Menge Implementierungsdetails, die es herauszufinden gilt, aber die Gliederung hier sollte ausreichen, um Sie zum Laufen zu bringen.
Hier ist mein hoher Ratschlag für den Einstieg (denken Sie daran, ich weiß nicht wirklich, was ich tue, also nehmen Sie es mit einem Körnchen Salz):
- Wenn Sie Zweifel haben, gehen Sie weiter. Interpretierte Sprachen sind im Allgemeinen einfacher zu entwerfen, zu bauen und zu lernen. Ich entmutige Sie nicht, einen kompilierten zu schreiben, wenn Sie wissen, dass Sie das tun möchten, aber wenn Sie am Zaun sind, würde ich weitermachen.
- Wenn es um Lexer und Parser geht, tun Sie, was Sie wollen. Es gibt gute Argumente für und gegen das eigene Schreiben. Wenn Sie am Ende Ihr Design durchdenken und alles sinnvoll umsetzen, spielt es keine Rolle.
- Lernen Sie von der Pipeline, mit der ich gelandet bin. Viel Versuch und Irrtum ging in die Gestaltung der Pipeline, die ich jetzt habe. Ich habe versucht, ASTs zu eliminieren, ASTs, die sich in Aktionsbäume verwandeln, und andere schreckliche Ideen. Diese Pipeline funktioniert, also ändern Sie sie nicht, es sei denn, Sie haben eine wirklich gute Idee.
- Wenn Sie nicht die Zeit oder Motivation haben, eine komplexe Allzwecksprache zu implementieren, versuchen Sie, eine esoterische Sprache wie Brainfuck zu implementieren. Diese Dolmetscher können bis zu einigen hundert Zeilen lang sein.
Ich bereue es sehr wenig, wenn es um die Entwicklung von Tannenzapfen geht. Ich habe auf dem Weg eine Reihe von schlechten Entscheidungen getroffen, aber ich habe den größten Teil des Codes, der von solchen Fehlern betroffen ist, neu geschrieben.
Im Moment ist Pinecone in einem so guten Zustand, dass es gut funktioniert und leicht verbessert werden kann. Das Schreiben von Pinecone war für mich eine äußerst lehrreiche und unterhaltsame Erfahrung, und es fängt gerade erst an.