Hallo und willkommen zu einem illustrierten Leitfaden für Long Short-Term Memory (LSTM) und Gated Recurrent Units GRU). Ich bin Michael und ich bin Ingenieur für maschinelles Lernen im Bereich KI-Sprachassistenten.
In diesem Beitrag beginnen wir mit der Intuition hinter LSTMs und GRUS. Dann erkläre ich die internen Mechanismen, die es LSTMs und Grus ermöglichen, so gut zu funktionieren. Wenn Sie verstehen möchten, was für diese beiden Netzwerke unter der Haube passiert, dann ist dieser Beitrag genau das Richtige für Sie.
Sie können die Videoversion dieses Beitrags auch auf Youtube ansehen, wenn Sie dies vorziehen.
Wiederkehrende neuronale Netze leiden unter Kurzzeitgedächtnis. Wenn eine Sequenz lang genug ist, fällt es ihnen schwer, Informationen von früheren Zeitschritten zu späteren zu übertragen. Wenn Sie also versuchen, einen Textabschnitt zu verarbeiten, um Vorhersagen zu treffen, können RNNs wichtige Informationen von Anfang an auslassen.
Während der Rückausbreitung leiden rekurrente neuronale Netze unter dem Problem des verschwindenden Gradienten. Gradienten sind Werte, die zum Aktualisieren der Gewichte eines neuronalen Netzes verwendet werden. Das Problem mit dem verschwindenden Gradienten besteht darin, dass der Gradient schrumpft, wenn er sich im Laufe der Zeit wieder ausbreitet. Wenn ein Gradientenwert extrem klein wird, trägt er nicht zu viel zum Lernen bei.

In rekurrenten neuronalen Netzen hören Ebenen, die ein kleines Gradientenupdate erhalten, auf zu lernen. Dies sind normalerweise die früheren Schichten. Da diese Schichten also nicht lernen, können RNNs vergessen, was sie in längeren Sequenzen gesehen haben, und haben so ein Kurzzeitgedächtnis. Wenn Sie mehr über die Mechanik rekurrenter neuronaler Netze im Allgemeinen erfahren möchten, können Sie meinen vorherigen Beitrag hier lesen.
LSTMs und GRUS als Lösung
LSTMs und GRUS wurden als Lösung für das Kurzzeitgedächtnis entwickelt. Sie verfügen über interne Mechanismen, sogenannte Gates, die den Informationsfluss regulieren können.

ie können lernen, welche Daten in einer Sequenz wichtig sind, um sie aufzubewahren oder wegzuwerfen. Auf diese Weise kann es relevante Informationen entlang der langen Kette von Sequenzen weitergeben, um Vorhersagen zu treffen. Mit diesen beiden Netzen werden nahezu alle Ergebnisse des Standes der Technik erzielt, die auf rekurrenten neuronalen Netzen basieren. LSTMs und GRUS finden sich in der Spracherkennung, Sprachsynthese und Texterzeugung. Sie können sie sogar verwenden, um Untertitel für Videos zu generieren.
Ok, also sollten Sie am Ende dieses Beitrags ein solides Verständnis dafür haben, warum LSTMs und GRUS gut darin sind, lange Sequenzen zu verarbeiten. Ich werde dies mit intuitiven Erklärungen und Illustrationen angehen und so viel Mathematik wie möglich vermeiden.
Intuition
Ok, fangen wir mit einem Gedankenexperiment an. Nehmen wir an, Sie schauen sich Bewertungen online an, um festzustellen, ob Sie Life Cereal kaufen möchten (fragen Sie mich nicht warum). Sie werden zuerst die Rezension lesen und dann feststellen, ob jemand sie für gut oder schlecht hielt.

Wenn Sie die denken Sie daran, dass sich Ihr Gehirn unbewusst nur an wichtige Schlüsselwörter erinnert. Sie nehmen Wörter wie „erstaunlich“ und „perfekt ausgewogenes Frühstück“ auf. Sie kümmern sich nicht viel um Wörter wie „dies“, „gab“, „alles“, „sollte“ usw. Wenn ein Freund Sie am nächsten Tag fragt, was in der Rezension steht, würden Sie sich wahrscheinlich nicht Wort für Wort daran erinnern. Vielleicht erinnern Sie sich an die wichtigsten Punkte wie „werde auf jeden Fall wieder kaufen“. Wenn Sie mir sehr ähnlich sind, werden die anderen Wörter aus dem Gedächtnis verschwinden.

Und das ist im Wesentlichen das, was ein LSTM oder GRU tut. Es kann lernen, nur relevante Informationen zu behalten, um Vorhersagen zu treffen, und nicht relevante Daten zu vergessen. In diesem Fall ließen Sie die Worte, an die Sie sich erinnerten, beurteilen, dass es gut war.
Überprüfung der rekurrenten neuronalen Netze
Um zu verstehen, wie LSTMs oder GRUS dies erreichen, lassen Sie uns das rekurrente neuronale Netz überprüfen. Ein RNN funktioniert so; Erste Wörter werden in maschinenlesbare Vektoren umgewandelt. Dann verarbeitet der RNN die Sequenz von Vektoren nacheinander.

Während der Verarbeitung wird der vorherige verborgene Zustand an den nächsten Schritt der Sequenz übergeben. Der verborgene Zustand fungiert als Speicher des neuronalen Netzes. Es enthält Informationen zu früheren Daten, die das Netzwerk zuvor gesehen hat.

Schauen wir uns eine Zelle des RNN an, um zu sehen, wie Sie den versteckten Zustand berechnen würden. Zunächst werden der Eingabe- und der vorherige ausgeblendete Zustand zu einem Vektor kombiniert. Dieser Vektor enthält nun Informationen über die aktuelle Eingabe und die vorherigen Eingaben. Der Vektor durchläuft die Tanh-Aktivierung und die Ausgabe ist der neue versteckte Status oder der Speicher des Netzwerks.

Tanh-Aktivierung
Die Tanh-Aktivierung wird verwendet, um die durch das Netzwerk fließenden Werte zu regulieren. Die tanh-Funktion zerquetscht Werte so, dass sie immer zwischen -1 und 1 liegen.

Wenn Vektoren durch ein neuronales Netzwerk fließen, erfährt es viele Transformationen aufgrund verschiedener mathematischer Operationen. Stellen Sie sich also einen Wert vor, der weiterhin mit 3 multipliziert wird. Sie können sehen, wie einige Werte explodieren und astronomisch werden können, wodurch andere Werte unbedeutend erscheinen.

Eine Tanh-Funktion sorgt dafür, dass die Werte zwischen -1 und 1 bleiben und regelt so die Ausgabe des neuronalen Netzes. Sie können sehen, wie die gleichen Werte von oben zwischen den von der tanh-Funktion zulässigen Grenzen bleiben.

Das ist also eine RNN. Es hat intern sehr wenige Operationen, funktioniert aber unter den richtigen Umständen (wie kurzen Sequenzen) ziemlich gut. RNNs verbraucht viel weniger Rechenressourcen als seine weiterentwickelten Varianten, LSTMs und GRUS.
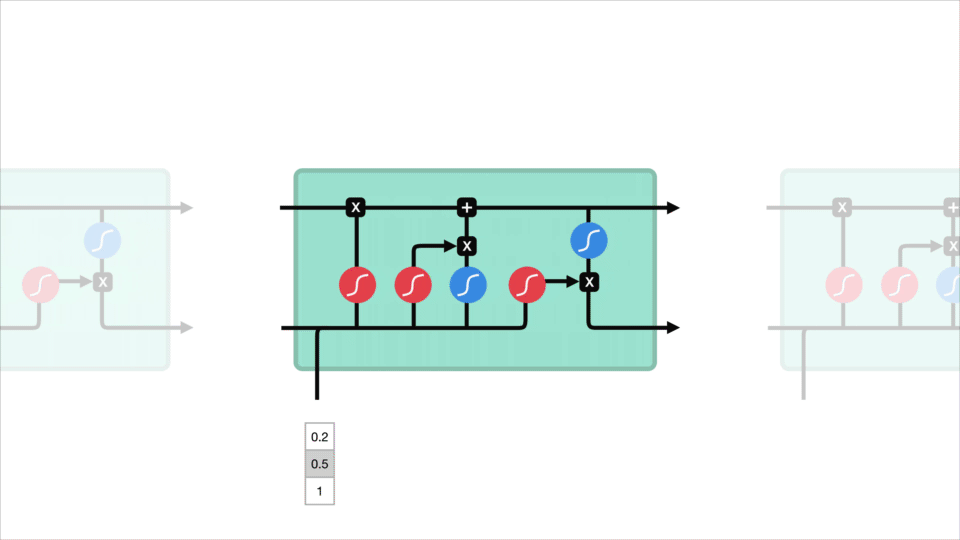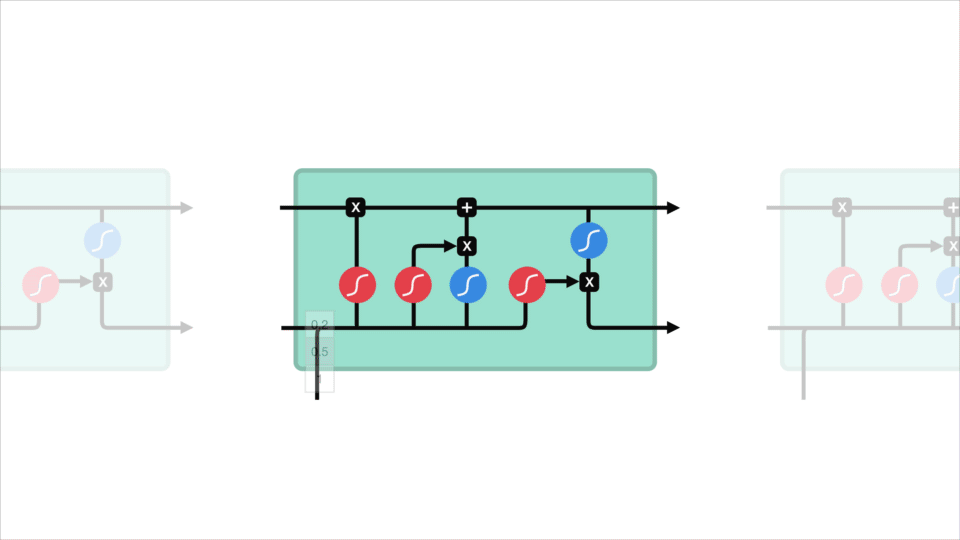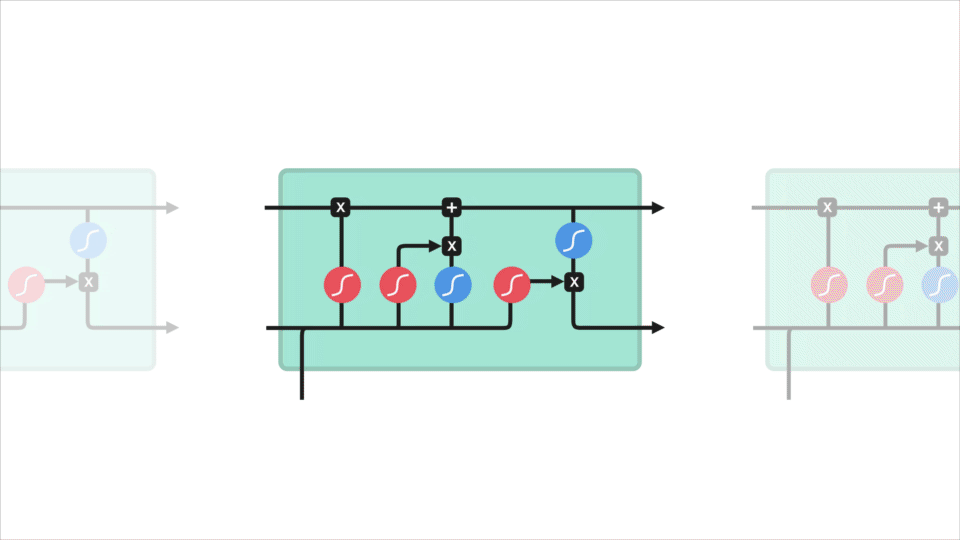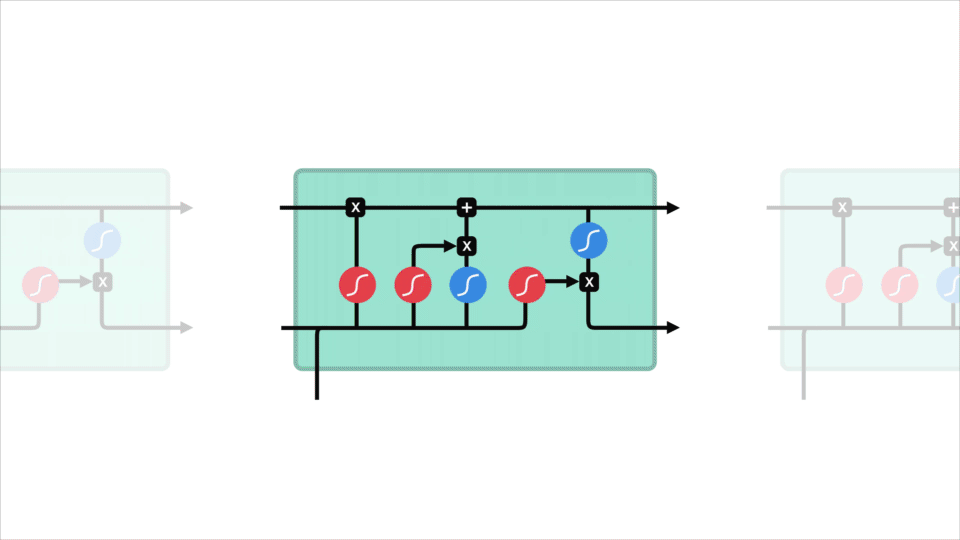
LSTM
Ein LSTM hat einen ähnlichen Kontrollfluss wie ein rekurrentes neuronales Netzwerk. Es verarbeitet Daten, die Informationen weitergeben, während sie sich vorwärts ausbreiten. Die Unterschiede sind die Operationen innerhalb der LSTM-Zellen.

Diese Operationen werden verwendet, damit das LSTM Informationen behalten oder vergessen kann. Wenn Sie sich diese Vorgänge jetzt ansehen, kann dies etwas überwältigend werden, daher werden wir dies Schritt für Schritt durchgehen.
Kernkonzept
Das Kernkonzept von LSTMs sind der Zellzustand und seine verschiedenen Gatter. Der Zellzustand fungiert als Transportautobahn, die relative Informationen entlang der Sequenzkette überträgt. Sie können es sich als „Speicher“ des Netzwerks vorstellen. Der Zellzustand kann theoretisch relevante Informationen während der gesamten Verarbeitung der Sequenz enthalten. So können sogar Informationen aus den früheren Zeitschritten zu späteren Zeitschritten gelangen, wodurch die Auswirkungen des Kurzzeitgedächtnisses verringert werden. Während der Zellzustand seine Reise fortsetzt, werden Informationen über Gatter zum Zellzustand hinzugefügt oder daraus entfernt. Die Gates sind verschiedene neuronale Netze, die entscheiden, welche Informationen über den Zellzustand erlaubt sind. Das Kind kann lernen, welche Informationen während des Trainings relevant sind, um sie zu behalten oder zu vergessen.
Sigmoid
Gates enthält Sigmoid-Aktivierungen. Eine Sigmoid-Aktivierung ähnelt der Tanh-Aktivierung. Anstatt Werte zwischen -1 und 1 zu quetschen, werden Werte zwischen 0 und 1 gequetscht. Dies ist hilfreich, um Daten zu aktualisieren oder zu vergessen, da jede Zahl, die mit 0 multipliziert wird, 0 ist, wodurch Werte verschwinden oder „vergessen“ werden.“ Jede Zahl multipliziert mit 1 ist der gleiche Wert, daher bleibt dieser Wert gleich oder wird beibehalten.“ Das Netzwerk kann lernen, welche Daten nicht wichtig sind und daher vergessen werden können oder welche Daten wichtig zu behalten sind.

Lassen Sie uns ein wenig tiefer in das eintauchen, was die verschiedenen Tore tun, sollen wir? Wir haben also drei verschiedene Gatter, die den Informationsfluss in einer LSTM-Zelle regulieren. EIN vergessen tor, eingang tor, und ausgang tor.
Forget gate
Zuerst haben wir das forget Gate. Dieses Tor entscheidet, welche Informationen weggeworfen oder aufbewahrt werden sollen. Informationen aus dem vorherigen verborgenen Zustand und Informationen aus dem aktuellen Eingang werden durch die Sigmoidfunktion geleitet. Die Werte liegen zwischen 0 und 1. Je näher an 0 bedeutet zu vergessen, und je näher an 1 bedeutet zu halten.

Eingangstor
Um den Zellstatus zu aktualisieren, haben wir das Eingangstor. Zuerst übergeben wir den vorherigen verborgenen Zustand und die aktuelle Eingabe in eine Sigmoidfunktion. Das entscheidet, welche Werte aktualisiert werden, indem die Werte zwischen 0 und 1 transformiert werden. 0 bedeutet nicht wichtig und 1 bedeutet wichtig. Sie übergeben auch den versteckten Status und die Stromeingabe an die Tanh-Funktion, um Werte zwischen -1 und 1 zu quetschen, um das Netzwerk zu regulieren. Dann multiplizieren Sie die Tanh-Ausgabe mit der Sigmoid-Ausgabe. Die Sigmoidausgabe entscheidet, welche Informationen wichtig sind, um sie von der Tanh-Ausgabe fernzuhalten.

Zellzustand
Jetzt sollten wir genügend Informationen haben, um den Zellzustand zu berechnen. Zuerst wird der Zellzustand punktweise mit dem Forget-Vektor multipliziert. Dies hat die Möglichkeit, Werte im Zellstatus zu löschen, wenn sie mit Werten nahe 0 multipliziert werden. Dann nehmen wir die Ausgabe vom Eingangsgatter und führen eine punktweise Addition durch, die den Zellzustand auf neue Werte aktualisiert, die das neuronale Netzwerk für relevant hält. Das gibt uns unseren neuen Zellzustand.

Ausgangstor
Zuletzt haben wir das Ausgangstor. Das Ausgangstor entscheidet, was der nächste versteckte Zustand sein soll. Denken Sie daran, dass der ausgeblendete Status Informationen zu vorherigen Eingaben enthält. Der verborgene Zustand wird auch für Vorhersagen verwendet. Zuerst übergeben wir den vorherigen versteckten Zustand und die aktuelle Eingabe in eine Sigmoidfunktion. Dann übergeben wir den neu modifizierten Zellzustand an die Tanh-Funktion. Wir multiplizieren die Tanh-Ausgabe mit der Sigmoid-Ausgabe, um zu entscheiden, welche Informationen der versteckte Zustand enthalten soll. Die Ausgabe ist der verborgene Zustand. Der neue Zellzustand und der neue Wert werden dann in den nächsten Zeitschritt übernommen.

Zur Überprüfung entscheidet das Forget Gate, was relevant ist, um von vorherigen Schritten fernzuhalten. Das Eingangsgatter entscheidet, welche Informationen aus dem aktuellen Schritt hinzugefügt werden sollen. Das Ausgangstor bestimmt, was der nächste versteckte Zustand sein soll.
Code-Demo
Für diejenigen unter Ihnen, die den Code besser verstehen, finden Sie hier ein Beispiel mit Python-Pseudocode.

1. Zuerst werden der vorherige ausgeblendete Status und die aktuelle Eingabe verkettet. Wir nennen es kombinieren.
2. Kombinieren Sie get’s in die Forget-Schicht. Diese Ebene entfernt nicht relevante Daten.
4. Mit combine wird eine Kandidatenebene erstellt. Der Kandidat enthält mögliche Werte, die dem Zellstatus hinzugefügt werden sollen.
3. Es wird auch in die Eingabeschicht eingespeist. Diese Ebene entscheidet, welche Daten vom Kandidaten dem neuen Zellstatus hinzugefügt werden sollen.
5. Nach dem Berechnen der Forget-Schicht, der Kandidatenschicht und der Eingangsschicht wird der Zellzustand unter Verwendung dieser Vektoren und des vorherigen Zellzustands berechnet.
6. Die Ausgabe wird dann berechnet.
7. Durch punktweises Multiplizieren der Ausgabe und des neuen Zellzustands erhalten wir den neuen versteckten Zustand.
Das war’s! Der Kontrollfluss eines LSTM-Netzwerks besteht aus einigen Tensoroperationen und einer for-Schleife. Sie können die versteckten Zustände für Vorhersagen verwenden. Durch die Kombination all dieser Mechanismen kann ein LSTM auswählen, welche Informationen relevant sind, um sie während der Sequenzverarbeitung zu speichern oder zu vergessen.
GRU
Jetzt wissen wir also, wie ein LSTM funktioniert. Die GRU ist die neuere Generation von rekurrenten neuronalen Netzen und ist einem LSTM ziemlich ähnlich. GRU hat den Zellstatus entfernt und den versteckten Status zum Übertragen von Informationen verwendet. Es hat auch nur zwei Tore, ein Reset-Tor und Update-Tor.

Update-Gate
Das Update-Gate verhält sich ähnlich wie das Forget- und Input-Gate eines LSTM. Es entscheidet, welche Informationen weggeworfen und welche neuen Informationen hinzugefügt werden sollen.
Reset-Gate
Das Reset-Gate ist ein weiteres Tor, das verwendet wird, um zu entscheiden, wie viele vergangene Informationen vergessen werden sollen.
Und das ist ein GRU. GRU hat weniger Tensoroperationen; daher sind sie etwas schneller zu trainieren als LSTMs. Es gibt keinen klaren Gewinner, welcher besser ist. Forscher und Ingenieure versuchen normalerweise beides, um festzustellen, welches für ihren Anwendungsfall besser geeignet ist.
Das war’s also
Zusammenfassend lässt sich sagen, dass RNNs gut für die Verarbeitung von Sequenzdaten für Vorhersagen geeignet sind, aber unter Kurzzeitgedächtnis leiden. LSTMs und GRUS wurden als Methode zur Abschwächung des Kurzzeitgedächtnisses mithilfe von Mechanismen namens Gates entwickelt. Gates sind nur neuronale Netze, die den Informationsfluss durch die Sequenzkette regulieren. LSTMs und GRUS werden in hochmodernen Deep-Learning-Anwendungen wie Spracherkennung, Sprachsynthese, Verständnis natürlicher Sprache usw. verwendet.
Wenn Sie daran interessiert sind, tiefer zu gehen, finden Sie hier Links zu einigen fantastischen Ressourcen, die Ihnen eine andere Perspektive beim Verständnis von LSTMs und GRUS geben können. Dieser Beitrag wurde stark von ihnen inspiriert.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/