Was ist Reinforcement Learning?
Reinforcement Learning ist definiert als eine Methode des maschinellen Lernens, die sich damit beschäftigt, wie Softwareagenten in einer Umgebung Aktionen ausführen sollen. Reinforcement Learning ist ein Teil der Deep Learning-Methode, mit der Sie einen Teil der kumulativen Belohnung maximieren können.
Diese Lernmethode für neuronale Netze hilft Ihnen, in vielen Schritten zu lernen, wie Sie ein komplexes Ziel erreichen oder eine bestimmte Dimension maximieren können.
Im Reinforcement Learning Tutorial lernen Sie:
- Was ist Reinforcement Learning?
- Wichtige Begriffe der Deep Reinforcement Learning Methode
- Wie funktioniert Reinforcement Learning?
- Algorithmen für Verstärkungslernen
- Merkmale des Verstärkungslernens
- Arten des Verstärkungslernens
- Lernmodelle der Verstärkung
- Verstärkungslernen vs. überwachtes Lernen
- Anwendungen des Verstärkungslernens
- Warum Verstärkungslernen verwenden?
- Wann sollte man Reinforcement Learning nicht verwenden?
- Herausforderungen des Verstärkungslernens
Wichtige Begriffe, die in der Deep Reinforcement Learning-Methode verwendet werden
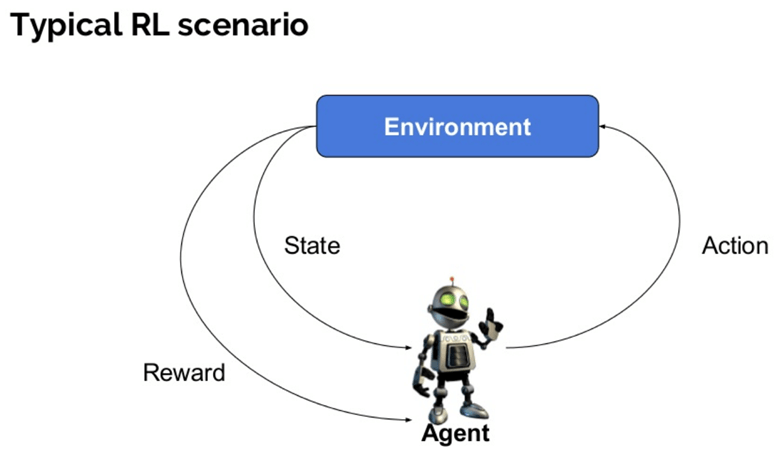
Hier sind einige wichtige Begriffe, die in der Verstärkungs-KI verwendet werden:
- Agent: Es ist eine angenommene Entität, die führt Aktionen in einer Umgebung aus, um eine Belohnung zu erhalten.
- Environment (e): Ein Szenario, dem sich ein Agent stellen muss.
- Belohnung (R): Eine sofortige Rückgabe an einen Agenten, wenn er eine bestimmte Aktion oder Aufgabe ausführt.
- State (s): State bezieht sich auf die aktuelle Situation, die von der Umgebung zurückgegeben wird.
- Politik (?): Es ist eine Strategie, die vom Agenten angewendet wird, um die nächste Aktion basierend auf dem aktuellen Status zu entscheiden.
- Wert (V): Es wird erwartet, langfristige Rendite mit Rabatt, im Vergleich zu der kurzfristigen Belohnung.
- Value-Funktion: Sie gibt den Wert eines Zustands an, der der Gesamtbetrag der Belohnung ist. Es ist ein Agent, der ab diesem Zustand erwartet werden sollte.
- Modell der Umgebung: Dies ahmt das Verhalten der Umgebung nach. Es hilft Ihnen, Rückschlüsse zu ziehen und auch zu bestimmen, wie sich die Umgebung verhält.
- Modellbasierte Methoden: Es ist eine Methode zur Lösung von Reinforcement-Learning-Problemen, die modellbasierte Methoden verwenden.
- Q-Wert oder Aktionswert (Q): Der Q-Wert ist dem Wert sehr ähnlich. Der einzige Unterschied zwischen den beiden besteht darin, dass ein zusätzlicher Parameter als aktuelle Aktion verwendet wird.
Wie funktioniert Reinforcement Learning?
Sehen wir uns ein einfaches Beispiel an, das Ihnen hilft, den Mechanismus des verstärkenden Lernens zu veranschaulichen.
Betrachten Sie das Szenario, Ihrer Katze neue Tricks beizubringen
- Da die Katze kein Englisch oder eine andere menschliche Sprache versteht, können wir ihr nicht direkt sagen, was sie tun soll. Stattdessen verfolgen wir eine andere Strategie.
- Wir emulieren eine Situation, und die Katze versucht auf viele verschiedene Arten zu reagieren. Wenn die Antwort der Katze der gewünschte Weg ist, geben wir ihr Fisch.
- Wenn die Katze nun derselben Situation ausgesetzt ist, führt sie eine ähnliche Aktion mit noch mehr Begeisterung aus, in der Erwartung, mehr Belohnung(Futter) zu erhalten.
- Das ist, als würde man lernen, dass Katze aus positiven Erfahrungen „was zu tun ist“ bekommt.
- Gleichzeitig lernt die Katze auch, was bei negativen Erfahrungen nicht zu tun ist.
Erläuterung zum Beispiel:
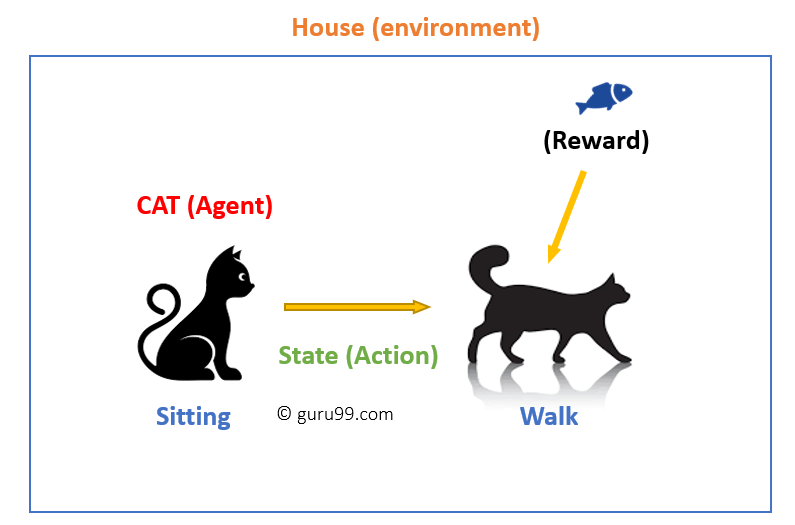
In diesem Fall
- Ihre Katze ist ein Agent, der der Umwelt ausgesetzt ist. In diesem Fall ist es Ihr Haus. Ein Beispiel für einen Zustand könnte Ihre Katze sitzen, und Sie verwenden ein bestimmtes Wort in for cat to walk.
- Unser Agent reagiert, indem er einen Aktionsübergang von einem „Zustand“ zu einem anderen „Zustand“ durchführt.“
- Zum Beispiel wechselt Ihre Katze vom Sitzen zum Gehen.
- Die Reaktion eines Agenten ist eine Aktion, und die Richtlinie ist eine Methode zur Auswahl einer Aktion in einem bestimmten Zustand in Erwartung besserer Ergebnisse.
- Nach dem Übergang erhalten sie möglicherweise eine Belohnung oder Strafe.
Algorithmen für Verstärkungslernen
Es gibt drei Ansätze, um einen Algorithmus für Verstärkungslernen zu implementieren.
Wertebasiert:
Bei einer wertebasierten Verstärkungslernmethode sollten Sie versuchen, eine Wertfunktion V(s) zu maximieren. Bei dieser Methode erwartet der Agent eine langfristige Rückkehr der aktuellen Zustände unter der Richtlinie ?.
Richtlinienbasiert:
In einer richtlinienbasierten RL-Methode versuchen Sie, eine solche Richtlinie zu erstellen, dass die in jedem Status ausgeführte Aktion Ihnen hilft, in Zukunft eine maximale Belohnung zu erhalten.
Zwei Arten von richtlinienbasierten Methoden sind:
- Deterministisch: Wird für jeden Zustand dieselbe Aktion von der Richtlinie erzeugt ?.
- Stochastisch: Jede Aktion hat eine bestimmte Wahrscheinlichkeit, die durch die folgende Gleichung bestimmt wird.Stochastische Politik :
n{a\s) = P\A, = a\S, =S]
Modellbasiert:
Bei dieser Verstärkungslernmethode müssen Sie für jede Umgebung ein virtuelles Modell erstellen. Der Agent lernt, in dieser spezifischen Umgebung zu arbeiten.
Merkmale des Verstärkungslernens
Hier sind wichtige Merkmale des Verstärkungslernens
- Es gibt keinen Supervisor, nur eine reelle Zahl oder ein Belohnungssignal
- Sequentielle Entscheidungsfindung
- Zeit spielt eine entscheidende Rolle bei Verstärkungsproblemen
- Feedback ist immer verzögert, nicht sofort
- Die Aktionen des Agenten bestimmen die nachfolgenden Daten, die er empfängt
Arten des Verstärkungslernens
Zwei Arten von Verstärkungslernmethoden sind:
Positiv:
Es ist definiert als ein Ereignis, das aufgrund eines bestimmten Verhaltens auftritt. Es erhöht die Stärke und die Häufigkeit des Verhaltens und wirkt sich positiv auf die Wirkung des Mittels aus.
Diese Art der Verstärkung hilft Ihnen, die Leistung zu maximieren und Veränderungen über einen längeren Zeitraum aufrechtzuerhalten. Eine zu starke Verstärkung kann jedoch zu einer Überoptimierung des Zustands führen, was sich auf die Ergebnisse auswirken kann.
Negativ:
Negative Verstärkung ist definiert als Verstärkung eines Verhaltens, das aufgrund eines negativen Zustands auftritt, der hätte gestoppt oder vermieden werden sollen. Es hilft Ihnen, den Mindeststand der Leistung zu definieren. Der Nachteil dieser Methode besteht jedoch darin, dass sie genug bietet, um das Mindestverhalten zu erfüllen.
Lernmodelle der Verstärkung
Beim Verstärkungslernen gibt es zwei wichtige Lernmodelle:
- Markov-Entscheidungsprozess
- Q-Lernen
Markov-Entscheidungsprozess
Die folgenden Parameter werden verwendet, um eine Lösung zu erhalten:
- Menge von Aktionen- A
- Menge von Zuständen -S
- Belohnung- R
- Politik- n
- Wert- V
Der mathematische Ansatz zur Abbildung einer Lösung im Verstärkungslernen wird als Markov-Entscheidungsprozess oder (MDP) bezeichnet.
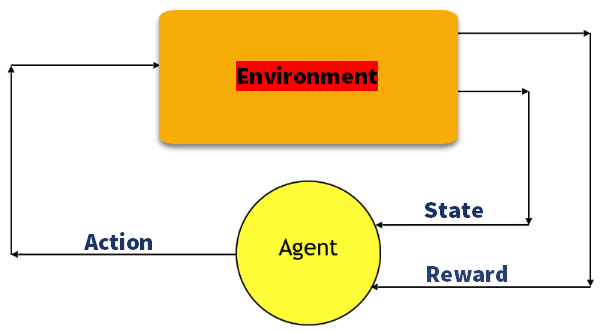
Q-Learning
Q-Learning ist eine wertbasierte Methode zur Bereitstellung von Informationen, um zu informieren, welche Aktion ein Agent ausführen soll.
Lassen Sie uns diese Methode anhand des folgenden Beispiels verstehen:
- Es gibt fünf Räume in einem Gebäude, die durch Türen verbunden sind.
- Jedes Zimmer ist von 0 bis 4 nummeriert
- Die Außenseite des Gebäudes kann ein großer Außenbereich sein (5)
- Türen Nummer 1 und 4 führen von Raum 5 ins Gebäude
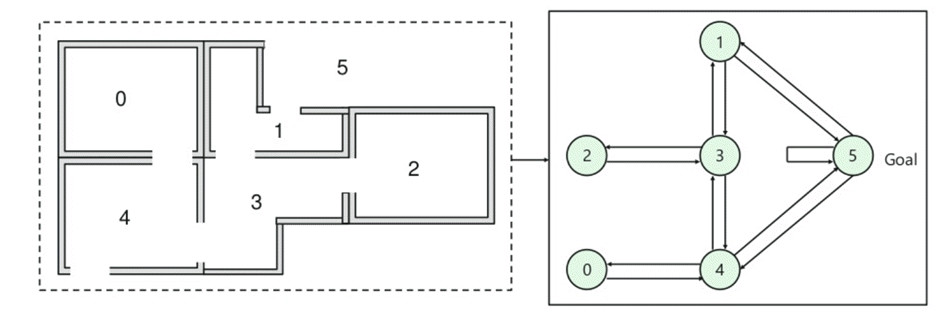
Als nächstes müssen Sie jeder Tür einen Belohnungswert zuordnen:
- Türen, die direkt zum Ziel führen, haben eine Belohnung von 100
- Türen, die nicht direkt mit dem Zielraum verbunden sind, erhalten keine Belohnung
- Da Türen zweiseitig sind und jedem Raum zwei Pfeile zugewiesen sind
- Jeder Pfeil im obigen Bild enthält einen sofortigen Belohnungswert
Erklärung:
In diesem Bild können Sie sehen, dass der Raum einen Zustand darstellt
Die Bewegung des Agenten von einem Raum in einen anderen stellt eine Aktion dar
Im unten angegebenen Bild wird ein Zustand als Knoten beschrieben, während die Pfeile die Aktion anzeigen.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Überwachtes Lernen
| Parameter | Reinforcement Learning | Überwachtes Lernen |
| Entscheidungsstil | reinforcement Learning hilft Ihnen, Ihre Entscheidungen nacheinander zu treffen. | Bei dieser Methode wird über die eingangs gegebene Eingabe entschieden. |
| Arbeitet an | Arbeitet an der Interaktion mit der Umgebung. | Arbeitet an Beispielen oder gegebenen Beispieldaten. |
| Abhängigkeit von der Entscheidung | In der RL-Methode ist die Lernentscheidung abhängig. Daher sollten Sie allen abhängigen Entscheidungen Etiketten geben. | Überwachtes Lernen der Entscheidungen, die unabhängig voneinander sind, so dass Etiketten für jede Entscheidung gegeben werden. |
| Am besten geeignet | Unterstützt und arbeitet besser in der KI, wo menschliche Interaktion vorherrscht. | Es wird meist mit einem interaktiven Softwaresystem oder Anwendungen betrieben. |
| Beispiel | Schachspiel | Objekterkennung |
Anwendungen des verstärkenden Lernens
Hier sind Anwendungen des verstärkenden Lernens:
- Robotik für die industrielle Automatisierung.
- Geschäftsstrategieplanung
- Maschinelles Lernen und Datenverarbeitung
- Es hilft Ihnen, Trainingssysteme zu erstellen, die benutzerdefinierte Anweisungen und Materialien entsprechend den Anforderungen der Schüler bereitstellen.
- Flugzeugsteuerung und Roboterbewegungssteuerung
Warum Verstärkungslernen einsetzen?
Hier sind die wichtigsten Gründe für die Verwendung von Reinforcement Learning:
- Es hilft Ihnen herauszufinden, welche Situation eine Aktion erfordert
- Hilft Ihnen herauszufinden, welche Aktion über einen längeren Zeitraum die höchste Belohnung erbringt.
- Reinforcement Learning bietet dem Learning Agent auch eine Belohnungsfunktion.
- Es erlaubt ihm auch, die beste Methode herauszufinden, um große Belohnungen zu erhalten.
Wann sollte man Verstärkungslernen nicht verwenden?
Sie können kein Verstärkungslernmodell anwenden, ist die ganze Situation. Hier sind einige Bedingungen, unter denen Sie kein Verstärkungslernmodell verwenden sollten.
- Wenn Sie über genügend Daten verfügen, um das Problem mit einer überwachten Lernmethode zu lösen
- Sie müssen bedenken, dass Verstärkungslernen rechenintensiv und zeitaufwändig ist. insbesondere dann, wenn der Aktionsraum groß ist.
Herausforderungen des Reinforcement Learning
Hier sind die wichtigsten Herausforderungen, denen Sie beim Reinforcement Earning gegenüberstehen werden:
- Feature- / Belohnungsdesign, das sehr involviert sein sollte
- Parameter können die Lerngeschwindigkeit beeinflussen.
- Realistische Umgebungen können teilweise beobachtbar sein.
- Zu viel Verstärkung kann zu einer Überlastung von Zuständen führen, was die Ergebnisse beeinträchtigen kann.
- Realistische Umgebungen können nicht stationär sein.
Zusammenfassung:
- Reinforcement Learning ist eine Methode des maschinellen Lernens
- Hilft Ihnen herauszufinden, welche Aktion über einen längeren Zeitraum die höchste Belohnung bringt.
- Drei Methoden für Reinforcement Learning sind 1) Wertebasiertes 2) Policy-basiertes und modellbasiertes Lernen.
- Agent, Zustand, Belohnung, Umwelt, Wertfunktionsmodell der Umwelt, Modellbasierte Methoden, sind einige wichtige Begriffe, die in der RL-Lernmethode verwendet werden
- Das Beispiel für Verstärkungslernen ist Ihre Katze ist ein Agent, der der Umwelt ausgesetzt ist.
- Das größte Merkmal dieser Methode ist, dass es keinen Supervisor gibt, nur eine reelle Zahl oder ein Belohnungssignal
- Zwei Arten von Verstärkungslernen sind 1) Positiv 2) Negativ
- Zwei weit verbreitete Lernmodelle sind 1) Markov-Entscheidungsprozess 2) Q-Lernen
- Die Verstärkungslernmethode arbeitet an der Interaktion mit der Umgebung, während die überwachte Lernmethode an bestimmten Beispieldaten oder Beispielen arbeitet.
- Anwendungs- oder Reinforcement-Learning-Methoden sind: Robotik für die industrielle Automatisierung und Geschäftsstrategieplanung
- Sie sollten diese Methode nicht verwenden, wenn Sie über genügend Daten verfügen, um das Problem zu lösen
- Die größte Herausforderung dieser Methode besteht darin, dass Parameter die Lerngeschwindigkeit beeinflussen können