VMware High Availability (HA) ist ein Dienstprogramm, das dedizierte Standby-Hardware und -Software in einer virtualisierten Umgebung überflüssig macht. VMware HA wird häufig verwendet, um die Zuverlässigkeit zu verbessern, Ausfallzeiten in virtuellen Umgebungen zu verringern und die Notfallwiederherstellung / Geschäftskontinuität zu verbessern.
Dieses Kapitel Auszug aus VCP4 Prüfung Cram: VMware Certified Professional, 2nd Edition von Elias Khnaser erforscht VMware HA Best Practices.
VMware High Availability befasst sich in erster Linie mit dem Ausfall des ESX/ESXi-Hosts und dem, was mit den virtuellen Maschinen (VMs) passiert, die auf diesem Host ausgeführt werden. Sie können eine VM auch überwachen und neu starten, indem Sie überprüfen, ob die VMware Tools noch ausgeführt werden. Wenn ein ESX / ESXi-Host aus irgendeinem Grund ausfällt, schlagen auch alle ausgeführten VMs fehl. VMware HA stellt sicher, dass die VMs des ausgefallenen Hosts auf anderen ESX/ESXi-Hosts neu gestartet werden können.
Viele verwechseln VMware HA fälschlicherweise mit Fehlertoleranz. VMware HA ist nicht fehlertolerant, da bei einem Ausfall eines Hosts auch die darauf befindlichen VMs ausfallen. HA befasst sich nur mit dem Neustart dieser VMs auf anderen ESX / ESXi-Hosts mit ausreichenden Ressourcen. Fehlertoleranz hingegen bietet unterbrechungsfreien Zugriff auf Ressourcen im Falle eines Hostausfalls.
 Klicken Sie auf das obige Titelbild
Klicken Sie auf das obige Titelbild , um Elias Khnasers gesamtes Kapitel
über Backup und Hochverfügbarkeit herunterzuladen.
VMware HA unterhält einen Kommunikationskanal mit allen anderen ESX / ESXi-Hosts, die Mitglieder desselben Clusters sind, indem ein Heartbeat verwendet wird, der standardmäßig alle 1 Sekunde in vSphere 4.0 oder alle 10 Sekunden in vSphere 4.1 gesendet wird. Wenn ein ESX-Server einen Heartbeat verpasst, warten die anderen Hosts 15 Sekunden, bis der andere Host erneut antwortet. Nach 15 Sekunden initiiert der Cluster den Neustart der VMs auf dem fehlerhaften ESX/ESXi-Host auf den verbleibenden ESX/ESXi-Hosts im Cluster. VMware HA überwacht auch ständig die ESX / ESXi-Hosts, die Mitglieder des Clusters sind, und stellt sicher, dass Ressourcen immer verfügbar sind, um die Anforderungen im Falle eines Hostausfalls zu erfüllen.
Fehlerüberwachung virtueller Maschinen
Die Fehlerüberwachung virtueller Maschinen ist eine Technologie, die standardmäßig deaktiviert ist. Seine Funktion besteht darin, virtuelle Maschinen zu überwachen, die es alle 20 Sekunden über einen Heartbeat abfragt. Dazu werden die VMware Tools verwendet, die in der VM installiert sind. Wenn eine VM einen Heartbeat verpasst, betrachtet VMware HA diese VM als fehlgeschlagen und versucht, sie zurückzusetzen. Stellen Sie sich die Fehlerüberwachung virtueller Maschinen als eine Art Hochverfügbarkeit für VMs vor.
Virtual Machine Failure Monitoring kann erkennen, ob eine virtuelle Maschine manuell ausgeschaltet, angehalten oder migriert wurde, und versucht daher nicht, sie neu zu starten.
VMware HA-Konfigurationsvoraussetzungen
HA erfordert die folgenden Konfigurationsvoraussetzungen, bevor es ordnungsgemäß funktionieren kann:
- vCenter: Da VMware HA ein Feature der Enterprise-Klasse ist, ist vCenter erforderlich, bevor es aktiviert werden kann.
- DNS-Auflösung: Alle ESX/ESXi-Hosts, die Mitglieder des HA-Clusters sind, müssen sich gegenseitig über DNS auflösen können.
- Zugriff auf gemeinsam genutzten Speicher: Alle Hosts im HA-Cluster müssen Zugriff und Sichtbarkeit auf denselben gemeinsam genutzten Speicher haben.
- Zugriff auf dasselbe Netzwerk: Für alle ESX/ESXi-Hosts müssen auf allen Hosts dieselben Netzwerke konfiguriert sein, damit eine VM beim Neustart auf einem beliebigen Host wieder Zugriff auf das richtige Netzwerk hat.
Redundanz der Dienstkonsole
Die empfohlene Vorgehensweise schreibt vor, dass die Dienstkonsole (SC) Redundanz aufweist. VMware HA beschwert sich und gibt eine Warnung aus, wenn festgestellt wird, dass die Service Console auf einem vSwitch mit nur einer VMNIC konfiguriert ist. Wie Abbildung 1 zeigt, können Sie die Dienstkonsolenredundanz auf zwei Arten konfigurieren:
- Erstellen Sie zwei Dienstkonsolenportgruppen auf jeweils einem anderen vSwitch.
- Weisen Sie der Service Console vSwitch zwei physische Netzwerkkarten (NICs) in Form eines NIC-Teams zu.
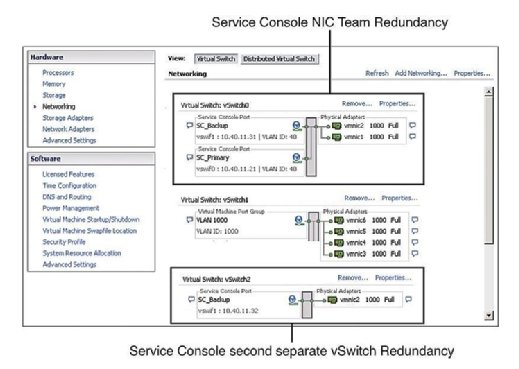
In beiden Fällen müssen Sie den gesamten IP-Stack mit IP-Adresse, Subnetz und Gateway konfigurieren. Die vSwitches der Dienstkonsole werden für die Heartbeats- und Statussynchronisierung verwendet und verwenden die folgenden Ports:
- Eingehender TCP-Port 8042
- Eingehender UDP-Port 8045
- Ausgehender TCP-Port 2050
- Ausgehender UDP-Port 2250
- Eingehender TCP-Port 8042-8045
- Eingehender UDP-Port 8042-8045
- Ausgehender TCP-Port 2050-2250
- Ausgehender UDP-Port 2050-2250
Fehler beim Konfigurieren der SC-Redundanz führt zu einer Warnmeldung, wenn Sie HA aktivieren. Um diese Fehlermeldung zu vermeiden und die bewährten Methoden einzuhalten, konfigurieren Sie den SC so, dass er redundant ist.
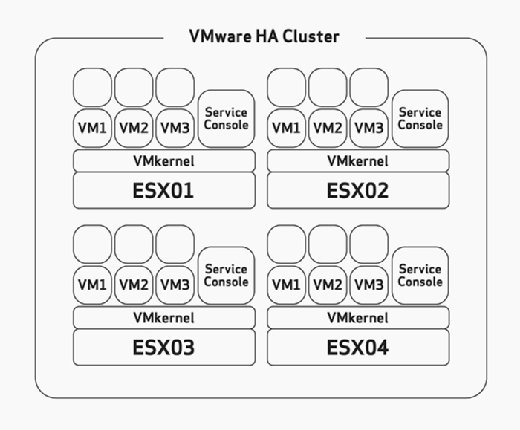
Planung der Host-Failover-Kapazität
Bei der Konfiguration von HA müssen Sie die maximale Host-Fehlertoleranz manuell konfigurieren. Dies ist eine Aufgabe, die Sie während der Hardware-Dimensionierung und Planungsphase Ihrer Bereitstellung sorgfältig berücksichtigen sollten. Dies würde davon ausgehen, dass Sie Ihre ESX / ESXi-Hosts mit genügend Ressourcen erstellt haben, um mehr VMs als geplant auszuführen, um HA aufnehmen zu können. Beachten Sie beispielsweise in Abbildung 2, dass der HA-Cluster über vier ESX-Hosts verfügt und dass alle vier Hosts über genügend Kapazität verfügen, um mindestens drei weitere VMs auszuführen. Da auf allen bereits drei VMs ausgeführt werden, kann sich dieser Cluster den Verlust von zwei ESX / ESXi-Hosts leisten, da die verbleibenden zwei ESX / ESXi-Hosts die sechs ausgefallenen VMs problemlos einschalten können, wenn ein Fehler auftritt.
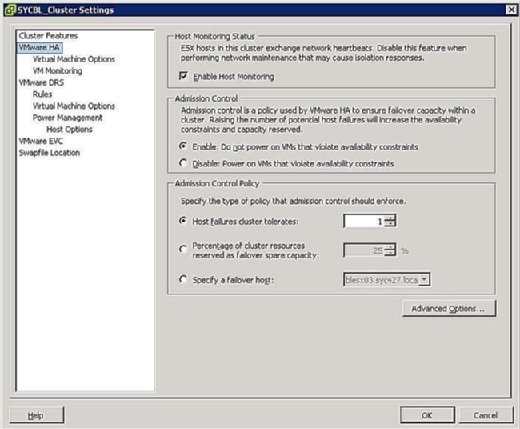
Während der Konfigurationsphase des HA-Clusters wird ein Bildschirm angezeigt, der dem in Abbildung 3 gezeigten ähnelt und Sie auffordert, zwei clusterweite Konfigurationen wie folgt zu definieren:
- Host-Überwachungsstatus:
- Host-Überwachung aktivieren: Mit dieser Einstellung können Sie steuern, ob der HA-Cluster die Hosts auf einen Heartbeat überwachen soll. Auf diese Weise kann der Cluster feststellen, ob ein Host noch aktiv ist. In einigen Fällen, wenn Sie Wartungsaufgaben auf ESX/ESXi-Hosts ausführen, kann es wünschenswert sein, diese Option zu deaktivieren, um die Isolierung eines Hosts zu vermeiden.
- Zugriffskontrolle:
- Aktivieren: VMs, die gegen Verfügbarkeitsbeschränkungen verstoßen, nicht einschalten: Wenn Sie diese Option auswählen, wird angezeigt, dass die VM nicht eingeschaltet werden sollte, wenn keine Ressourcen zur Befriedigung einer VM verfügbar sind.
- Deaktivieren: Einschalten von VMs, die gegen Verfügbarkeitseinschränkungen verstoßen: Wenn Sie diese Option auswählen, sollten Sie eine VM einschalten, auch wenn Sie Ressourcen überbelegen müssen.
- Zulassungssteuerungsrichtlinie:
- Hostfehler Cluster toleriert: Mit dieser Einstellung können Sie konfigurieren, wie viele Hostfehler Sie tolerieren möchten. Die zulässigen Einstellungen sind 1 bis 4.
- Prozentsatz der Cluster-Ressourcen, die als Failover-Reservekapazität reserviert sind: Wenn Sie diese Option auswählen, wird angezeigt, dass Sie einen Prozentsatz der gesamten Clusterressourcen in Reserve für das Failover reservieren. In einem Cluster mit vier Hosts zeigt eine Reservierung von 25% an, dass Sie einen vollständigen Host für das Failover reservieren. Wenn Sie weniger beiseite legen möchten, können Sie stattdessen 10% der Clusterressourcen auswählen.
- Failover-Host angeben: Wenn Sie diese Option auswählen, wählen Sie einen bestimmten Host als Failover-Host im Cluster aus. Dies kann der Fall sein, wenn Sie einen Ersatzhost oder einen bestimmten Host mit deutlich mehr Rechen- und Speicherressourcen haben.
Host isolation
Ein Netzwerkphänomen, das als Split-Brain bekannt ist, tritt auf, wenn der ESX/ESXi-Host keinen Heartbeat mehr vom Rest des Clusters empfängt. Der Heartbeat wird jede Sekunde in vSphere 4.0 oder 10 Sekunden in vSphere 4.1 abgefragt. Wenn keine Antwort empfangen wird, denkt der Cluster, dass der ESX /ESXi-Host fehlgeschlagen ist. In diesem Fall hat der ESX / ESXi-Host seine Netzwerkkonnektivität auf seiner Verwaltungsschnittstelle verloren. Der Host ist möglicherweise noch in Betrieb und die VMs sind möglicherweise nicht einmal betroffen, da sie möglicherweise eine andere Netzwerkschnittstelle verwenden, die nicht betroffen ist. In diesem Fall muss vSphere jedoch Maßnahmen ergreifen, da es der Ansicht ist, dass ein Host ausgefallen ist. In diesem Fall wurde die Host-Isolationsantwort erstellt. Host Isolation Response ist die Methode von HA, mit einem ESX / ESXi-Host umzugehen, der seine Netzwerkverbindung verloren hat.
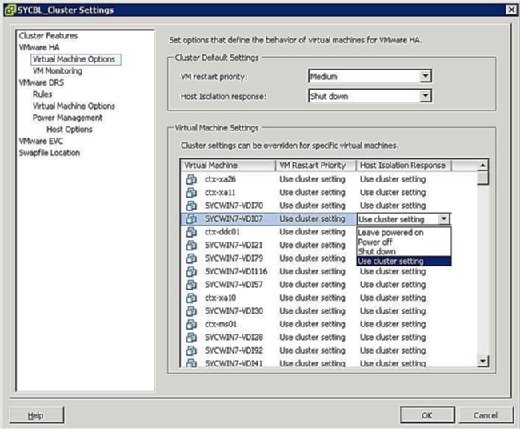
Sie können steuern, was mit VMs im Falle einer Host-Isolation passiert. Um zum Bildschirm VM Isolation Response zu gelangen, klicken Sie mit der rechten Maustaste auf den betreffenden Cluster und klicken Sie auf Einstellungen bearbeiten. Sie können dann im linken Bereich unter dem VMware HA-Banner auf Optionen für virtuelle Maschinen klicken. Sie können Optionen clusterweit steuern, indem Sie die Option host Isolation Response entsprechend festlegen. Dies gilt für alle VMs auf dem betroffenen Host. Sie können die Clustereinstellungen jedoch jederzeit überschreiben, indem Sie eine andere Antwort auf VM-Ebene definieren.
Wie in Abbildung 4 dargestellt, sind Ihre Isolationsantwort-Optionen wie folgt:
- Eingeschaltet lassen: Wie die Bezeichnung andeutet, bedeutet diese Einstellung, dass die VM im Falle einer Host-Isolation eingeschaltet bleibt.
- Power Off: Diese Einstellung definiert, dass im Falle einer Isolation die VM ausgeschaltet wird. Dies ist ein hartes Ausschalten.
- Herunterfahren: Diese Einstellung definiert, dass die VM im Falle einer Isolation ordnungsgemäß mit VMware Tools heruntergefahren wird. Wenn diese Aufgabe nicht innerhalb von fünf Minuten erfolgreich abgeschlossen wird, wird sofort ein Ausschalten ausgeführt. Wenn VMware Tools nicht installiert ist, wird stattdessen ein Ausschalten ausgeführt.
- Cluster-Einstellung verwenden: Diese Einstellung leitet die Aufgabe an die clusterweite Einstellung weiter, die in dem zuvor in Abbildung 4 gezeigten Fenster definiert wurde.
Im Falle einer Isolation bedeutet dies nicht unbedingt, dass der Host ausgefallen ist. Da die VMs möglicherweise mit unterschiedlichen physischen Netzwerkkarten konfiguriert und mit unterschiedlichen Netzwerken verbunden sind, funktionieren sie möglicherweise weiterhin ordnungsgemäß. Wenn ein Host isoliert ist, bedeutet dies lediglich, dass seine Servicekonsole nicht mit den übrigen ESX / ESXi-Hosts im Cluster kommunizieren kann.
Wiederherstellungspriorität der virtuellen Maschine
Sollte Ihr HA-Cluster im Falle eines Ausfalls nicht alle VMs aufnehmen können, haben Sie die Möglichkeit, VMs zu priorisieren. Die Prioritäten bestimmen, welche VMs zuerst neu gestartet werden und welche VMs im Notfall nicht so wichtig sind. Diese Optionen werden auf demselben Bildschirm wie die im vorherigen Abschnitt behandelte Isolationsantwort konfiguriert. Sie können clusterweite Einstellungen konfigurieren, die auf alle VMs auf dem betroffenen Host angewendet werden, oder Sie können die Clustereinstellungen überschreiben, indem Sie eine Überschreibung auf VM-Ebene konfigurieren.
Sie können die Neustartpriorität einer VM wie folgt festlegen:
- Hoch: VMs mit hoher Priorität werden zuerst neu gestartet.
- Medium: Dies ist die Standardeinstellung.
- Low: VMs mit niedriger Priorität werden zuletzt neu gestartet.
- Clustereinstellung verwenden: VMs werden basierend auf der Einstellung neu gestartet, die auf der Clusterebene definiert ist, die in dem in der folgenden Abbildung gezeigten Fenster definiert ist.
- Deaktiviert: Die VM lässt sich nicht einschalten.
Die Priorität sollte basierend auf der Wichtigkeit der VMs festgelegt werden. Mit anderen Worten, Sie möchten möglicherweise Domänencontroller neu starten und Druckserver nicht neu starten. Die virtuellen Maschinen mit höherer Priorität werden zuerst neu gestartet. VMs, die es tolerieren, im Notfall ausgeschaltet zu bleiben, sollten so konfiguriert werden, dass sie ausgeschaltet bleiben, um Ressourcen zu schonen.
MSCS Clustering
Der Hauptzweck eines Clusters besteht darin, sicherzustellen, dass kritische Systeme jederzeit und um jeden Preis online bleiben. Ähnlich wie physische Maschinen, die geclustert werden können, können auch virtuelle Maschinen mit ESX in drei verschiedenen Szenarien geclustert werden:
- Cluster-in-a-box: In diesem Szenario befinden sich alle VMs, die Teil des Clusters sind, auf demselben ESX/ESXi-Host. Wie Sie vielleicht schon vermutet haben, entsteht dadurch sofort ein Single Point of Failure: der ESX / ESXi-Host. In Bezug auf gemeinsam genutzten Speicher können Sie in diesem Szenario virtuelle Festplatten als gemeinsam genutzten Speicher verwenden oder Raw Device Mapping (RDM) im virtuellen Kompatibilitätsmodus verwenden.
- Cluster-across-boxes: In diesem Szenario befinden sich die Clusterknoten (VMs, die Mitglieder des Clusters sind) auf mehreren ESX /ESXi-Hosts, wobei jeder der Knoten, aus denen der Cluster besteht, auf denselben Speicher zugreifen kann Wenn eine VM ausfällt, kann die andere weiterhin funktionieren und auf dieselben Daten zugreifen. Dieses Szenario schafft eine ideale Clusterumgebung, indem ein Single Point of Failure eliminiert wird. Shared Storage ist dabei eine Voraussetzung und muss sich auf Fibre Channel SAN befinden. Sie müssen ein RDM auch im physischen oder virtuellen Kompatibilitätsmodus verwenden, da virtuelle Laufwerke keine unterstützte Konfiguration für gemeinsam genutzten Speicher sind. Wobei jeder der Knoten, aus denen der Cluster besteht, auf denselben Speicher zugreifen kann, sodass bei einem Ausfall einer VM die andere weiterhin funktionieren und auf dieselben Daten zugreifen kann.
- Physikalisch-virtueller Cluster: In diesem Szenario ist ein Mitglied des Clusters eine virtuelle Maschine, während das andere Mitglied eine physische Maschine ist. Freigegebener Speicher ist in diesem Szenario eine Voraussetzung und muss als RDM im physischen Kompatibilitätsmodus konfiguriert werden.
Wenn Sie eine Clustering-Lösung entwerfen, müssen Sie das Problem des gemeinsam genutzten Speichers angehen, der mehreren Hosts oder VMs den Zugriff auf dieselben Daten ermöglicht. vSphere bietet verschiedene Methoden, mit denen Sie gemeinsam genutzten Speicher wie folgt bereitstellen können:
- Virtuelle Festplatten: Sie können eine virtuelle Festplatte nur dann als freigegebenen Speicherbereich verwenden, wenn Sie Clustering in einer Box durchführen, d. h. nur, wenn sich beide VMs auf demselben ESX /ESXi-Host befinden.
- RDM im physischen Kompatibilitätsmodus: In diesem Modus können Sie eine physische LUN direkt an eine VM oder einen physischen Computer anhängen. Dieser Modus verhindert die Verwendung von Funktionen wie Snapshots und wird idealerweise verwendet, wenn ein Mitglied des Clusters eine physische Maschine und das andere eine VM ist.
- RDM im virtuellen Kompatibilitätsmodus: In diesem Modus können Sie eine physische LUN direkt an eine VM oder einen physischen Computer anhängen. Dieser Modus bietet Ihnen alle Vorteile virtueller Festplatten, die auf VMFS ausgeführt werden, einschließlich Snapshots und erweiterter Dateisperrung. Der Zugriff auf die Festplatte erfolgt über den Hypervisor und ist ideal für die Konfiguration eines clusterübergreifenden Szenarios, in dem Sie beiden VMs Zugriff auf gemeinsam genutzten Speicher gewähren müssen.
Zum Zeitpunkt dieses Schreibens ist Microsoft Clustering Services (MSCS) der einzige von VMware unterstützte Clusterdienst. Sie können das VMware-Whitepaper „Setup für Failover-Clustering und Microsoft Cluster Service“ lesen.“
VMware Fault Tolerance
VMware Fault Tolerance (FT) ist eine weitere Form des VM-Clusters, die von VMware für Systeme entwickelt wurde, die eine extreme Verfügbarkeit erfordern. Eines der überzeugendsten Merkmale von FT ist die einfache Einrichtung. FT ist einfach ein Kontrollkästchen, das aktiviert werden kann. Im Vergleich zu herkömmlichem Clustering, das bestimmte Konfigurationen und in einigen Fällen Verkabelung erfordert, ist FT einfach, aber leistungsstark.
Wie funktioniert es?
Beim Schutz von VMs mit FT wird eine sekundäre VM im Gleichschritt mit der geschützten VM, der ersten VM, erstellt. FT funktioniert, indem gleichzeitig auf die erste VM und die zweite VM geschrieben wird. Jede Aufgabe wird zweimal geschrieben. Wenn Sie auf das Startmenü der ersten VM klicken, wird auch auf das Startmenü der zweiten VM geklickt. Die Stärke von FT ist seine Fähigkeit, beide VMs synchron zu halten.
Wenn die geschützte VM aus irgendeinem Grund ausfällt, nimmt die sekundäre VM sofort ihren Platz ein, greift nach ihrer Identität und ihrer IP-Adresse und bedient die Benutzer weiterhin ohne Unterbrechung. Die neu hochgestufte geschützte VM erstellt dann eine sekundäre für sich selbst auf einem anderen Host und der Zyklus wird neu gestartet.
Zur Verdeutlichung sehen wir uns ein Beispiel an. Wenn Sie einen Exchange-Server schützen möchten, können Sie FT aktivieren. Wenn aus irgendeinem Grund der ESX / ESXi-Host, der die geschützte VM trägt, ausfällt, tritt die sekundäre VM ein und übernimmt ihre Aufgaben ohne Unterbrechung des Dienstes.
Die folgende Tabelle beschreibt die verschiedenen Hochverfügbarkeits- und Clustertechnologien, auf die Sie mit vSphere zugreifen können, und zeigt die jeweiligen Einschränkungen auf.

Anforderungen an die Fehlertoleranz
Die Fehlertoleranz unterscheidet sich nicht von anderen Unternehmensfunktionen dadurch, dass bestimmte Voraussetzungen erfüllt sein müssen, bevor die Technologie ordnungsgemäß und effizient funktionieren kann. Diese Anforderungen sind in der folgenden Liste aufgeführt und in die verschiedenen Kategorien unterteilt, die bestimmte Mindestanforderungen erfordern:
- Host-Anforderungen:
- FT-kompatible CPU. Weitere Informationen finden Sie in diesem VMware KB-Artikel.
- Hardware-Virtualisierung muss im BIOS aktiviert sein.
- Die CPU-Taktraten des Hosts müssen innerhalb von 400 MHz voneinander liegen.
- VM-Anforderungen:
- VMs müssen sich auf einem unterstützten freigegebenen Speicher (FC, iSCSI und NFS) befinden.
- VMs müssen ein unterstütztes Betriebssystem ausführen.
- VMs müssen entweder in einem VMDK oder einem virtuellen RDM gespeichert sein.
- VMs können kein thinly provisioned VMDK haben und müssen ein virtuelles Eagerzeroedthick-Laufwerk verwenden.
- VMs können nicht mehr als eine vCPU konfiguriert haben.
- Cluster-Anforderungen:
- Alle ESX/ESXi-Hosts müssen dieselbe Version und denselben Patchlevel haben.
- Alle ESX/ESXi-Hosts müssen Zugriff auf die VM-Datenspeicher und -Netzwerke haben.
- VMware HA muss auf dem Cluster aktiviert sein.
- Auf jedem Host muss eine vMotion- und FT-Protokollierungs-NIC konfiguriert sein.
- Host certificate checking muss ebenfalls aktiviert sein.
Es wird dringend empfohlen, dass Sie zusätzlich zur Überprüfung der Prozessorkompatibilität mit FT die Hersteller- und Modellkompatibilität Ihres Servers mit FT anhand der VMware Hardware Compatibility List (HCL) überprüfen.Während FT eine großartige Clustering-Lösung ist, ist es wichtig zu beachten, dass es auch bestimmte Einschränkungen hat. Beispielsweise können FT-VMs nicht snapshottet und keine Speicher-VMOTIONIERT werden. Tatsächlich werden diese VMs automatisch als DRS-Deaktiviert gekennzeichnet und nehmen an keinem dynamischen Ressourcenlastausgleich teil.
So aktivieren Sie FT
Das Aktivieren von FT ist nicht schwierig, erfordert jedoch die Konfiguration einiger verschiedener Einstellungen. Die folgenden Einstellungen müssen ordnungsgemäß konfiguriert sein, damit FT funktioniert:
- Hostzertifikatsprüfung aktivieren: Um diese Einstellung zu aktivieren, melden Sie sich bei Ihrem vCenter Server an, klicken Sie im Menü Datei auf Administration und dann auf vCenter Server-Einstellungen. Klicken Sie im linken Bereich auf SSL-Einstellungen, und aktivieren Sie das Kontrollkästchen vCenter erfordert verifizierte Host-SSL-Zertifikate.
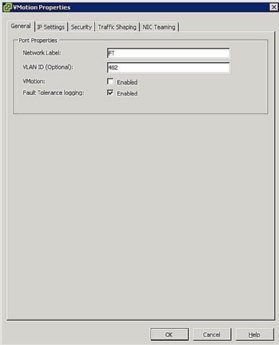
Abbildung 5. Einstellungen der FT-Portgruppe - Host-Netzwerk konfigurieren: Die Netzwerkkonfiguration für FT ist einfach und folgt den gleichen Schritten und Verfahren wie vMotion, außer dass anstelle des Kontrollkästchens vMotion das Kontrollkästchen Fehlertoleranzprotokollierung aktiviert wird, wie in Abbildung 5 gezeigt.
- FT ein- und ausschalten: Nachdem Sie die vorhergehenden Anforderungen erfüllt haben, können Sie FT nun für VMs ein- und ausschalten. Dieser Vorgang ist ebenfalls unkompliziert: Suchen Sie die VM, die Sie schützen möchten, klicken Sie mit der rechten Maustaste darauf und wählen Sie Fehlertoleranz>Fehlertoleranz aktivieren.
FT ist zwar eine Clustering-Technologie der ersten Generation, funktioniert aber beeindruckend gut und vereinfacht überkomplizierte traditionelle Methoden zum Erstellen, Konfigurieren und Verwalten von Clustern. FT ist eine beeindruckende Technologie aus Sicht der Verfügbarkeit und eines nahtlosen Failovers.