Zuletzt aktualisiert am 17. Februar 2021
Eine Vorhersage aus Sicht des maschinellen Lernens ist ein einzelner Punkt, der die Unsicherheit dieser Vorhersage verbirgt.
Vorhersageintervalle bieten eine Möglichkeit, die Unsicherheit in einer Vorhersage zu quantifizieren und zu kommunizieren. Sie unterscheiden sich von Konfidenzintervallen, die stattdessen versuchen, die Unsicherheit in einem Populationsparameter wie einem Mittelwert oder einer Standardabweichung zu quantifizieren. Prognoseintervalle beschreiben die Unsicherheit für ein einzelnes spezifisches Ergebnis.
In diesem Tutorial lernen Sie das Vorhersageintervall und seine Berechnung für ein einfaches lineares Regressionsmodell kennen.
Nach Abschluss dieses Tutorials wissen Sie:
- Dass ein Vorhersageintervall die Unsicherheit einer Einzelpunktvorhersage quantifiziert.
- Dass Vorhersageintervalle für einfache Modelle analytisch geschätzt werden können, für nichtlineare Modelle des maschinellen Lernens jedoch schwieriger sind.
- Berechnung des Vorhersageintervalls für ein einfaches lineares Regressionsmodell.
Starten Sie Ihr Projekt mit meinem neuen Buch Statistics for Machine Learning, einschließlich Schritt-für-Schritt-Anleitungen und den Python-Quellcodedateien für alle Beispiele.
Los geht’s.
- Aktualisiert Jun/2019: Korrigiertes Signifikanzniveau als Bruchteil der Standardabweichungen.
- Aktualisiert Apr/ 2020: Tippfehler im Diagramm des Vorhersageintervalls behoben.

Vorhersageintervalle für maschinelles Lernen
Foto von Jim Bendon, einige Rechte vorbehalten.
Tutorial-Übersicht
Dieses Tutorial ist in 5 Teile unterteilt; sie sind:
- Was ist falsch an einer Punktschätzung?
- Was ist ein Vorhersageintervall?
- Wie berechnet man ein Vorhersageintervall
- Vorhersageintervall für lineare Regression
- Funktioniertes Beispiel
Benötigen Sie Hilfe bei Statistiken für maschinelles Lernen?
Nehmen Sie jetzt an meinem kostenlosen 7-tägigen E-Mail-Crashkurs teil (mit Beispielcode).
Klicken Sie hier, um sich anzumelden und eine kostenlose PDF-Ebook-Version des Kurses zu erhalten.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.predict(X)
|
Wobei yhat das geschätzte Ergebnis oder die Vorhersage ist, die das trainierte Modell für die angegebenen Eingabedaten X.
Dies ist eine Punktvorhersage.
Per Definition ist es eine Schätzung oder eine Annäherung und enthält eine gewisse Unsicherheit.
Die Unsicherheit ergibt sich aus den Fehlern im Modell selbst und dem Rauschen in den Eingabedaten. Das Modell ist eine Annäherung an die Beziehung zwischen den Eingangsvariablen und den Ausgangsvariablen.
Angesichts des Prozesses, der zur Auswahl und Abstimmung des Modells verwendet wird, wird es die beste Annäherung sein, die angesichts der verfügbaren Informationen gemacht wird, aber es wird immer noch Fehler machen. Daten aus der Domäne verdecken natürlich die zugrunde liegende und unbekannte Beziehung zwischen den Eingabe- und Ausgabevariablen. Dies macht es zu einer Herausforderung, das Modell anzupassen, und macht es auch zu einer Herausforderung für ein Anpassungsmodell, Vorhersagen zu treffen.
Angesichts dieser beiden Hauptfehlerquellen reicht ihre Punktvorhersage aus einem Vorhersagemodell nicht aus, um die wahre Unsicherheit der Vorhersage zu beschreiben.
Was ist ein Vorhersageintervall?
Ein Vorhersageintervall ist eine Quantifizierung der Unsicherheit einer Vorhersage.
Es bietet eine probabilistische Ober- und Untergrenze für die Schätzung einer Ergebnisvariablen.
Ein Vorhersageintervall für eine einzelne zukünftige Beobachtung ist ein Intervall, das mit einem bestimmten Vertrauensgrad eine zukünftige zufällig ausgewählte Beobachtung aus einer Verteilung enthält.
— Seite 27, Statistische Intervalle: Ein Leitfaden für Praktiker und Forscher, 2017.
Vorhersageintervalle werden am häufigsten verwendet, wenn Vorhersagen oder Prognosen mit einem Regressionsmodell getroffen werden, bei denen eine Größe vorhergesagt wird.
Ein Beispiel für die Darstellung eines Vorhersageintervalls ist wie folgt:
Bei einer Vorhersage von ‚y‘ bei ‚x‘ besteht eine Wahrscheinlichkeit von 95%, dass der Bereich ‚a‘ bis ‚b‘ das wahre Ergebnis abdeckt.
Das Vorhersageintervall umgibt die Vorhersage des Modells und deckt hoffentlich den Bereich des wahren Ergebnisses ab.
Das folgende Diagramm hilft, die Beziehung zwischen der Vorhersage, dem Vorhersageintervall und dem tatsächlichen Ergebnis visuell zu verstehen.
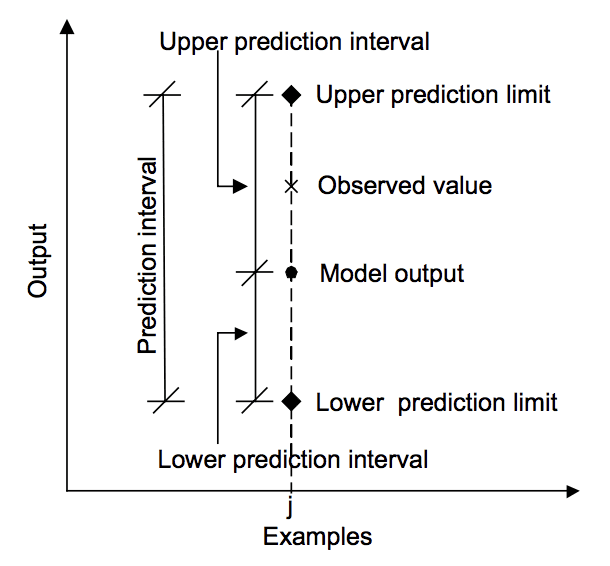
Beziehung zwischen Vorhersage, Istwert und Vorhersageintervall.
Entnommen aus „Machine learning approaches for estimation of prediction interval for the model output“, 2006.
Ein Vorhersageintervall unterscheidet sich von einem Konfidenzintervall.
Ein Konfidenzintervall quantifiziert die Unsicherheit einer geschätzten Populationsvariablen, z. B. des Mittelwerts oder der Standardabweichung. Während ein Vorhersageintervall die Unsicherheit einer einzelnen Beobachtung quantifiziert, die aus der Grundgesamtheit geschätzt wird.
In der Vorhersagemodellierung kann ein Konfidenzintervall verwendet werden, um die Unsicherheit der geschätzten Fähigkeit eines Modells zu quantifizieren, während ein Vorhersageintervall verwendet werden kann, um die Unsicherheit einer einzelnen Prognose zu quantifizieren.
Ein Vorhersageintervall ist oft größer als das Konfidenzintervall, da es das Konfidenzintervall und die Varianz in der vorhergesagten Ausgangsvariablen berücksichtigen muss.
Vorhersageintervalle sind immer breiter als Konfidenzintervalle, da sie die mit e , dem irreduziblen Fehler, verbundene Unsicherheit berücksichtigen.
— Seite 103, Eine Einführung in das statistische Lernen: mit Anwendungen in R, 2013.
Berechnung eines Vorhersageintervalls
Ein Vorhersageintervall wird als eine Kombination aus der geschätzten Varianz des Modells und der Varianz der Ergebnisvariablen berechnet.
Vorhersageintervalle sind leicht zu beschreiben, aber in der Praxis schwer zu berechnen.
In einfachen Fällen wie der linearen Regression können wir das Vorhersageintervall direkt abschätzen.
Bei nichtlinearen Regressionsalgorithmen wie künstlichen neuronalen Netzen ist dies viel schwieriger und erfordert die Auswahl und Implementierung spezialisierter Techniken. Allgemeine Techniken wie die Bootstrap-Resampling-Methode können verwendet werden, sind jedoch rechenintensiv zu berechnen.
Das Paper „A Comprehensive Review of Neural Network-based Prediction Intervals and New Advances“ bietet eine relativ neue Studie über Vorhersageintervalle für nichtlineare Modelle im Kontext neuronaler Netze. Die folgende Liste fasst einige Methoden zusammen, die zur Vorhersage der Unsicherheit für nichtlineare Modelle des maschinellen Lernens verwendet werden können:
- Die Delta-Methode aus dem Bereich der nichtlinearen Regression.
- Die Bayes’sche Methode aus Bayes’scher Modellierung und Statistik.
- Die Mittelwert-Varianz-Schätzmethode unter Verwendung geschätzter Statistiken.
- Die Bootstrap-Methode, die Datenresampling verwendet und ein Ensemble von Modellen entwickelt.
Wir können die Berechnung eines Vorhersageintervalls mit einem ausgearbeiteten Beispiel im nächsten Abschnitt konkretisieren.
Vorhersageintervall für lineare Regression
Eine lineare Regression ist ein Modell, das die lineare Kombination von Eingaben zur Berechnung der Ausgangsvariablen beschreibt.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
Wir kennen die wahren Werte der Koeffizienten b0 und b1 nicht. Wir kennen auch nicht die wahren Populationsparameter wie Mittelwert und Standardabweichung für x oder y. Alle diese Elemente müssen geschätzt werden, was Unsicherheit in die Verwendung des Modells einführt, um Vorhersagen zu treffen.
Wir können einige Annahmen treffen, wie die Verteilungen von x und y und die Vorhersagefehler des Modells, Residuen genannt, sind Gaußsch.
Das Vorhersageintervall um yhat kann wie folgt berechnet werden:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
Wir wissen nicht, in der Praxis. Wir können eine unvoreingenommene Schätzung der vorhergesagten Standardabweichung wie folgt berechnen (entnommen aus maschinellen Lernansätzen zur Schätzung des Vorhersageintervalls für die Modellausgabe):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
Funktionierendes Beispiel
Lassen Sie uns den Fall linearer Regressionsvorhersageintervalle anhand eines funktionierenden Beispiels konkretisieren.
Definieren wir zunächst einen einfachen Datensatz mit zwei Variablen, bei dem die Ausgangsvariable (y) von der Eingangsvariablen (x) mit einem gewissen Gaußschen Rauschen abhängt.
Das folgende Beispiel definiert den Datensatz, den wir für dieses Beispiel verwenden werden.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# verwandte Variablen generieren
aus numpy import mean
aus std
from numpy.random import randn
from numpy.random import seed
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# summarize
print(‚x: mean=%.3f stdv=%.3f‘ % (mean(x), std(x)))
print(‚y: mean=%.3f stdv=%.3f‘ % (mean(y), std(y)))
# plot
pyplot.scatter(x, y)
pyplot.show()
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
Anschließend wird ein Plot des Datensatzes erstellt.
Wir können die klare lineare Beziehung zwischen den Variablen mit der Ausbreitung der Punkte sehen, die das Rauschen oder den zufälligen Fehler in der Beziehung hervorheben.
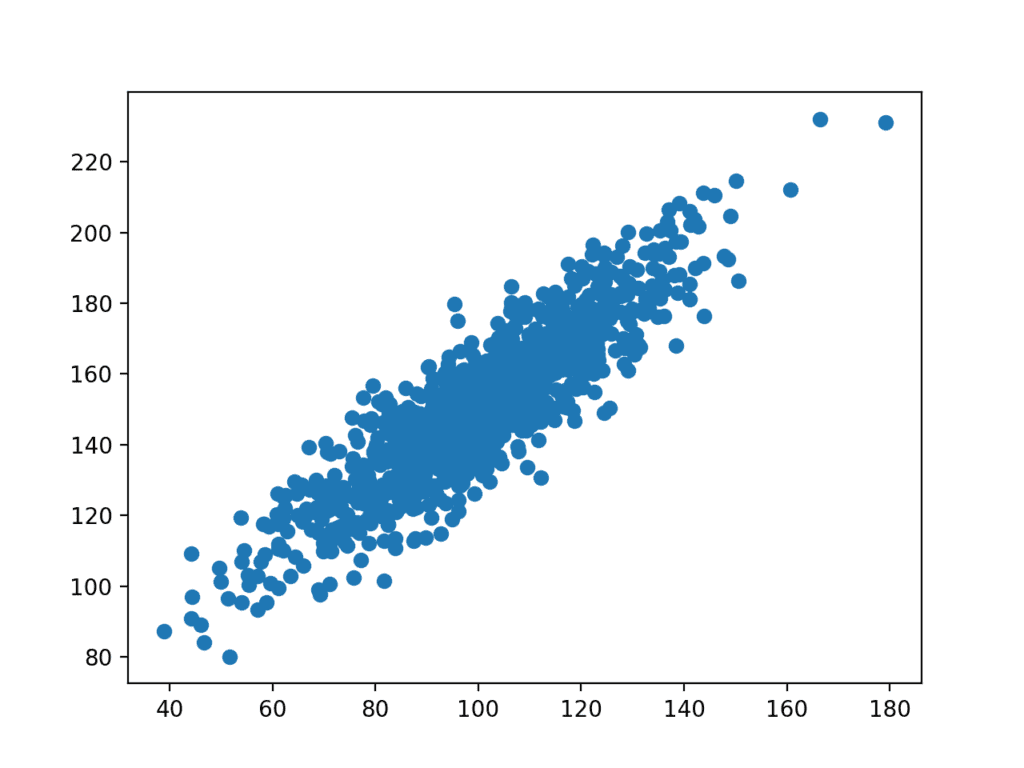
Streudiagramm verwandter Variablen
Als nächstes können wir eine einfache lineare Regression entwickeln, die angesichts der Eingangsvariablen x die y-Variable vorhersagt. Wir können die SciPy-Funktion linregress() verwenden, um das Modell anzupassen und die Koeffizienten b0 und b1 für das Modell zurückzugeben.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# einfaches nichtlineares Regressionsmodell
von numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(‚b0=%.3f, b1=%.3f‘ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r‘)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
b0=1,011, b1=49,117
|
Die Koeffizienten werden dann mit den Eingaben aus dem Datensatz verwendet, um eine Vorhersage zu treffen. Die resultierenden Eingaben und vorhergesagten y-Werte werden als Linie über dem Streudiagramm für das Dataset dargestellt.
Wir können deutlich sehen, dass das Modell die zugrunde liegende Beziehung im Datensatz gelernt hat.
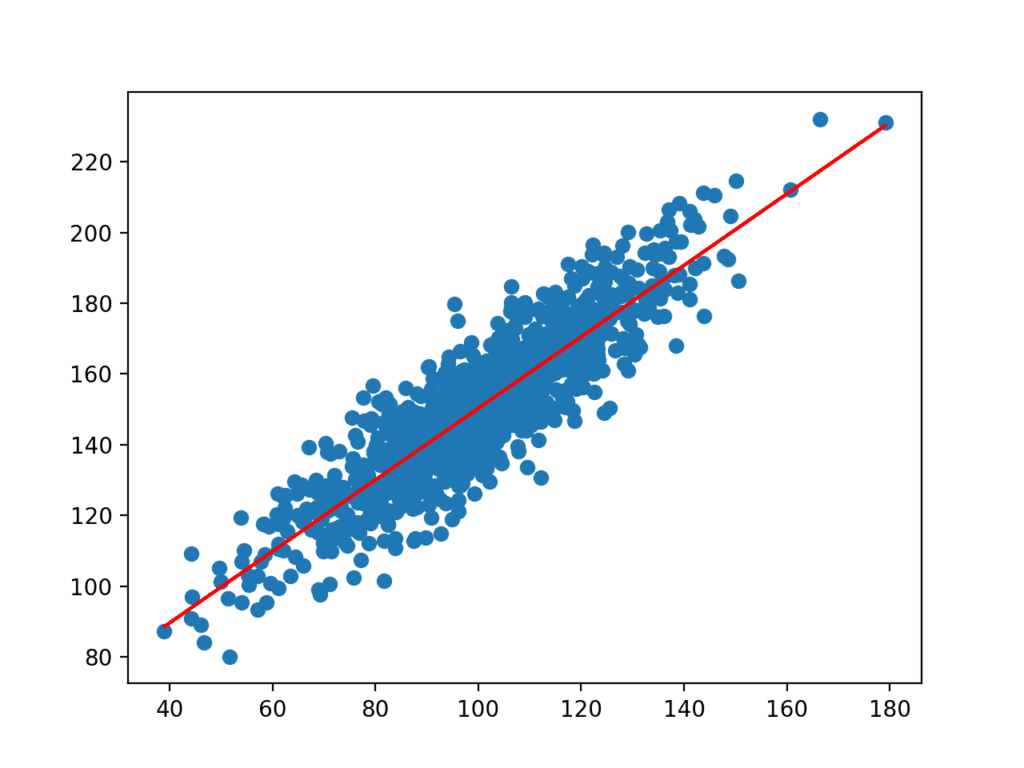
Streudiagramm des Datensatzes mit Linie für einfaches lineares Regressionsmodell
Wir sind jetzt bereit, mit unserem einfachen linearen Regressionsmodell eine Vorhersage zu treffen und ein Vorhersageintervall hinzuzufügen.
Wir werden das Modell wie zuvor anpassen. Dieses Mal nehmen wir eine Probe aus dem Datensatz, um das Vorhersageintervall zu demonstrieren. Wir werden die Eingabe verwenden, um eine Vorhersage zu treffen, das Vorhersageintervall für die Vorhersage zu berechnen und die Vorhersage und das Intervall mit dem bekannten Erwartungswert zu vergleichen.
Definieren wir zunächst die Eingabe-, Vorhersage- und Erwartungswerte.
|
1
2
3
|
x_in = x
y_out = y
yhat_out = yhat
|
Als nächstes können wir die Standardkrümmung in der Vorhersagerichtung schätzen.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.stats import linregress
from matplotlib import pyplot
# seed Zufallszahlengenerator
seed(1)
# Bereiten Sie die Daten vor
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# Passen Sie das nichtlineare Regressionsmodell an
b1, b0, r_value, p_value, std_err = linregress(x, y)
# Vorhersagen markieren
yhat = b0 + b1 * x
# neue Eingabe, Erwartungswert und Vorhersage definieren
x_in = x
y_out = y
yhat_out = yhat
# Schätzung stdev von yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
# Vorhersageintervall berechnen
Intervall = 1.96 * stdev
print(‚Vorhersageintervall: %.3f‘ % Intervall)
lower, upper = yhat_out – Intervall, yhat_out + Intervall
print(‚95%% Wahrscheinlichkeit, dass der wahre Wert zwischen % liegt.3f und %.3f‘ % (lower, upper))
print(‚Wahrer Wert: %.3f‘ % y_out)
# Datensatz und Vorhersage mit Intervall plotten
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’red‘)
pyplot.errorbar(x_in, yhat_out, yerr=Intervall, Farbe=’schwarz‘, fmt=’o‘)
pyplot.show()
|
Das Ausführen des Beispiels schätzt die yhat-Standardabweichung und berechnet dann das Vorhersageintervall.
Nach der Berechnung wird dem Benutzer das Vorhersageintervall für die angegebene Eingabevariable angezeigt. Weil wir dieses Beispiel erfunden haben, kennen wir das wahre Ergebnis, das wir auch zeigen. Wir können sehen, dass in diesem Fall das 95% -Vorhersageintervall den wahren erwarteten Wert abdeckt.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
Es wird auch ein Diagramm erstellt, das den Rohdatensatz als Streudiagramm, die Vorhersagen für den Datensatz als rote Linie und die Vorhersage und das Vorhersageintervall als schwarzen Punkt bzw.
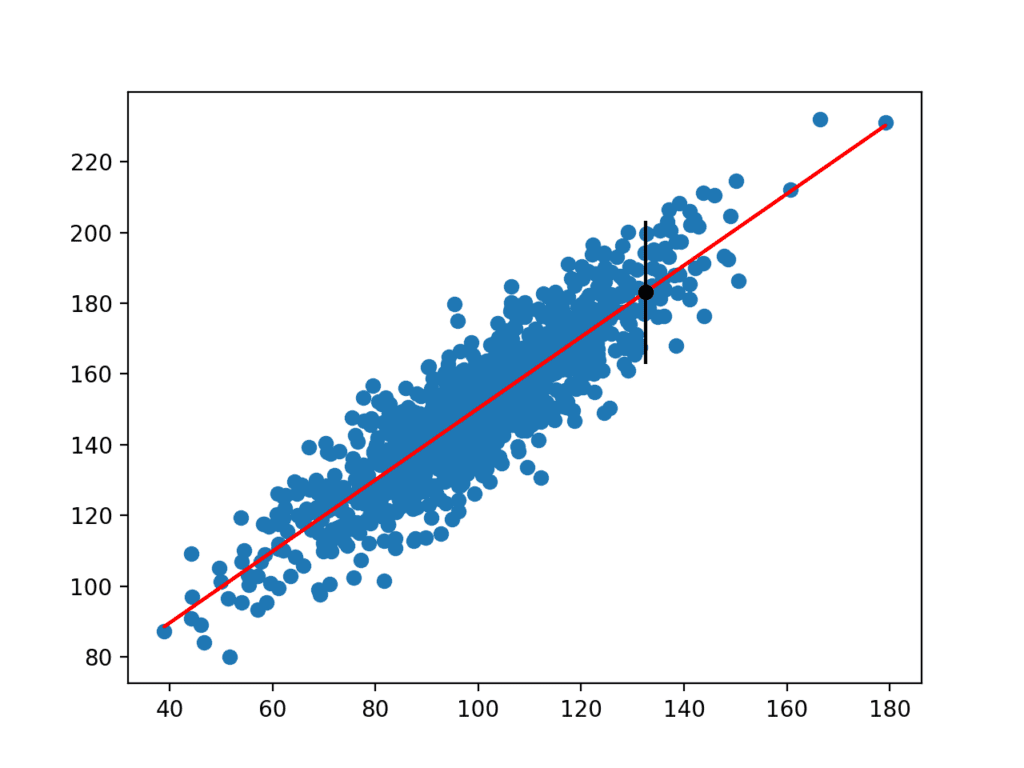
Streudiagramm des Datensatzes mit linearem Modell und Vorhersageintervall
Erweiterungen
In diesem Abschnitt werden einige Ideen zur Erweiterung des Lernprogramms aufgeführt, die Sie möglicherweise erkunden möchten.
- Fassen Sie den Unterschied zwischen Toleranz-, Konfidenz- und Vorhersageintervallen zusammen.
- Entwickeln Sie ein lineares Regressionsmodell für einen Standarddatensatz für maschinelles Lernen und berechnen Sie Vorhersageintervalle für einen kleinen Testsatz.
- Beschreiben Sie im Detail, wie eine nichtlineare Vorhersageintervallmethode funktioniert.
Wenn Sie eine dieser Erweiterungen erkunden, würde ich gerne wissen.
Weiterführende Literatur
Dieser Abschnitt enthält weitere Ressourcen zu diesem Thema, wenn Sie tiefer gehen möchten.
Beiträge
- So melden Sie die Klassifikatorleistung mit Konfidenzintervallen
- So berechnen Sie Bootstrap-Konfidenzintervalle für Ergebnisse des maschinellen Lernens in Python
- Zeitreihenprognoseunsicherheit mithilfe von Konfidenzintervallen mit Python verstehen
- Schätzen Sie die Anzahl der Experimentwiederholungen für stochastische Algorithmen des maschinellen Lernens
Bücher
- Die neuen Statistiken verstehen: Effektgrößen, Konfidenzintervalle und Metaanalyse, 2017.
- Statistische Intervalle: Ein Leitfaden für Praktiker und Forscher, 2017.
- Eine Einführung in das statistische Lernen: mit Anwendungen in R, 2013.
- Einführung in die neue Statistik: Schätzung, Open Science und darüber hinaus, 2016.
- Prognose: Prinzipien und Praxis, 2013.
Papers
- Ein Vergleich einiger Fehlerschätzungen für neuronale Netzwerkmodelle, 1995.
- Ansätze des maschinellen Lernens zur Schätzung des Vorhersageintervalls für die Modellausgabe, 2006.
- A Comprehensive Review of Neural Network-based Prediction Intervals and New Advances, 2010.
API
- scipy.Stats.linregress() API
- matplotlib.pyplot.scatter() API
- matplotlib.pyplot.errorbar() API
Artikel
- Vorhersageintervall auf Wikipedia
- Bootstrap-Vorhersageintervall auf Crossview
Zusammenfassung
In diesem Tutorial haben Sie das Vorhersageintervall und seine Berechnung für ein einfaches lineares Regressionsmodell ermittelt.
Konkret haben Sie gelernt:
- Dass ein Vorhersageintervall die Unsicherheit einer Einzelpunktvorhersage quantifiziert.
- Dass Vorhersageintervalle für einfache Modelle analytisch geschätzt werden können, für nichtlineare Modelle des maschinellen Lernens jedoch schwieriger sind.
- Berechnung des Vorhersageintervalls für ein einfaches lineares Regressionsmodell.
Haben Sie Fragen?
Stellen Sie Ihre Fragen in den Kommentaren unten und ich werde mein Bestes tun, um zu antworten.
Holen Sie sich einen Griff auf Statistiken für maschinelles Lernen!

Entwickeln Sie ein funktionierendes Verständnis der Statistik
…durch das Schreiben von Codezeilen in Python
Entdecken Sie, wie in meinem neuen Ebook:
Statistische Methoden für maschinelles Lernen
Es bietet Tutorials zum Selbststudium zu Themen wie:
Hypothesentests, Korrelation, nichtparametrische Statistiken, Resampling und vieles mehr…
Entdecken Sie, wie man Daten in Wissen umwandelt
Überspringen Sie die Akademiker. Nur Ergebnisse.
Sehen Sie, was drin ist