Sie können kategoriale Variablen nicht ohne weiteres als Prädiktoren in der linearen Regression verwenden: Sie müssen sie in dichotome Variablen aufteilen, die als Dummy-Variablen bekannt sind.
Der ideale Weg, um diese zu erstellen, ist unser Dummy-Variablen-Tool. Wenn Sie dieses Tool nicht verwenden möchten, zeigt dieses Lernprogramm den richtigen Weg, dies manuell zu tun.
- Beispiel I – Beliebige numerische Variable
- Beispiel II – Numerische Variable mit benachbarten Ganzzahlen
- Beispiel III – Zeichenfolgenvariable mit Konvertierung
- Beispiel IV – Zeichenfolgenvariable ohne Konvertierung
Beispieldatendatei
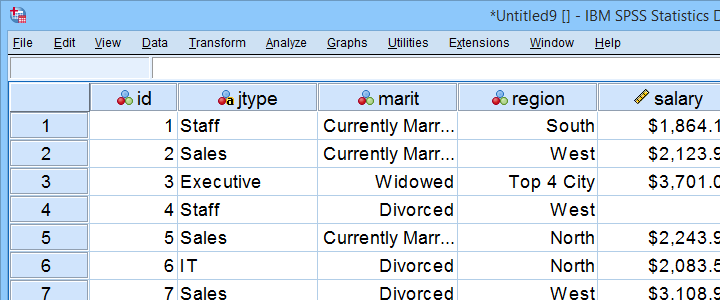
Dieses Tutorial verwendet staff.sav überall. Ein Teil dieser Datendatei wird unten angezeigt.
Beispiel I – Beliebige numerische Variable
Erstellen wir zunächst Dummy-Variablen für marit, kurz für Familienstand. Unser erster Schritt besteht darin, eine grundlegende Frequenztabelle mitfrequencies marit .Die folgende Tabelle zeigt die resultierende Tabelle.
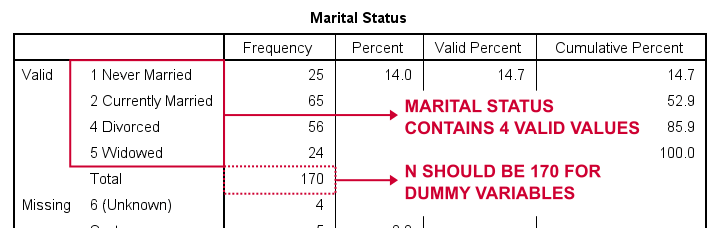
Wie kann man also den Familienstand in Dummy-Variablen aufteilen? Zunächst einmal lassen wir immer eine Kategorie weg, die Referenzkategorie. Sie können eine beliebige Kategorie als Referenzkategorie auswählen.
Für dieses Beispiel wählen wir also 5 (Verwitwet). Dies bedeutet, dass wir 3 Dummy-Variablen erstellen, die die Kategorien 1, 2 und 4 darstellen (beachten Sie, dass 3 in dieser Variablen nicht vorkommt).
Die folgende Syntax zeigt, wie Sie unsere 3 Dummy-Variablen erstellen und beschriften. Lass es uns laufen.
Berechnen Sie marit_1 = (marit = 1).
Berechnen Sie marit_2 = (marit = 2).
Berechnen Sie marit_4 = (marit = 4).
* Wenden Sie variable Etiketten auf Dummy-Variablen.
variable labels
marit_1 ‚Familienstand = Nie verheiratet‘
marit_2 ‚Familienstand = Derzeit verheiratet‘
marit_4 ‚Familienstand = geschieden‘.
*Quick check erste Dummy-Variable
Frequenzen marit_1.
Ergebnisse
Beachten Sie zunächst, dass wir in unserem aktiven Datensatz 3 schön beschriftete Dummy-Variablen erstellt haben.
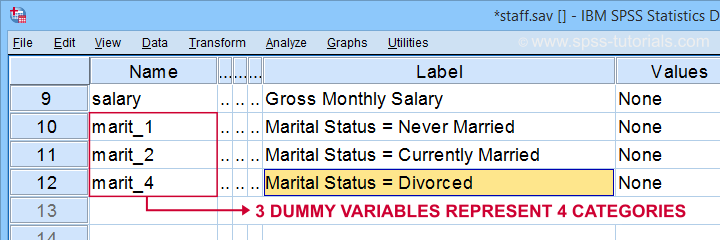
Die folgende Tabelle zeigt die Häufigkeitsverteilung für unsere erste Dummy-Variable.

Beachten Sie, dass unsere Dummy-Variable 3 verschiedene Werte enthält:
- Befragte, deren Familienstand nicht „nie verheiratet“ ist, erhalten 0;
- Befragte, deren Familienstand „nie verheiratet“ ist, erhalten 1;
- Befragte, deren Familienstand ein fehlender Wert (und daher unbekannt) ist, haben einen fehlenden Systemwert.
Wir können die Ergebnisse nun genauer überprüfen, indem wir die Kreuztabs marit von marit_1 bis marit_4 ausführen.Dadurch werden 3 Kontingenztabellen erstellt, von denen die erste unten gezeigt wird.
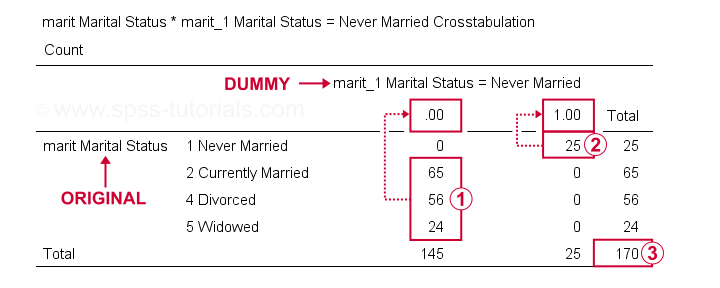
Auf unserer Dummy-Variable, Befragte mit anderen Familienstand als „nie verheiratet“ alle Punktzahl 0;
Befragte mit anderen Familienstand als „nie verheiratet“ alle Punktzahl 0; Befragte, die „nie verheiratet“ alle Punktzahl 1;
Befragte, die „nie verheiratet“ alle Punktzahl 1; Wir haben eine Stichprobengröße von N = 170 (diese Tabelle enthält nur Befragte ohne fehlende Werte für beide Variablen).Optional besteht eine abschließende – sehr gründliche – Prüfung darin, die ANOVA-Ergebnisse für die ursprüngliche Variable mit den Regressionsergebnissen unter Verwendung unserer Dummy-Variablen zu vergleichen. Die folgende Syntax macht genau das und verwendet das monatliche Gehalt als abhängige Variable.
Wir haben eine Stichprobengröße von N = 170 (diese Tabelle enthält nur Befragte ohne fehlende Werte für beide Variablen).Optional besteht eine abschließende – sehr gründliche – Prüfung darin, die ANOVA-Ergebnisse für die ursprüngliche Variable mit den Regressionsergebnissen unter Verwendung unserer Dummy-Variablen zu vergleichen. Die folgende Syntax macht genau das und verwendet das monatliche Gehalt als abhängige Variable.
regression
/abhängiges Gehalt
/Methode geben Sie marit_1 bis marit_4 ein.
*Minimale ANOVA unter Verwendung der ursprünglichen Variablen.
oneway Gehalt von marit.
Beachten Sie, dass beide Analysen zu identischen ANOVA-Tabellen führen. Wir werden ANOVA versus Dummy Variable Regression in einem zukünftigen Tutorial ausführlicher diskutieren.
Beispiel II – Numerische Variable mit benachbarten Ganzzahlen
Wir erstellen nun Dummy-Variablen für die Region. Auch hier beginnen wir mit der Überprüfung einer minimalen Frequenztabelle, die wir mit runningfrequencies region erstellen.Dies ergibt die folgende Tabelle.
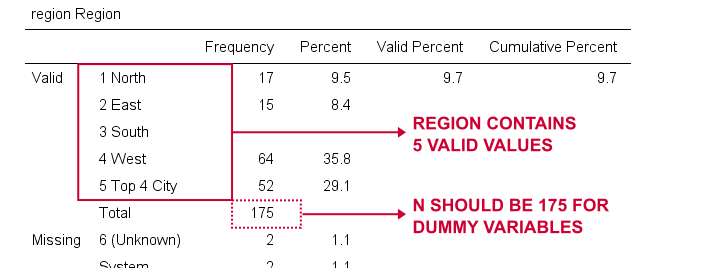
Wir wählen 1 („North“) als Referenzkategorie. Wir erstellen daher Dummy-Variablen für die Kategorien 2 bis 5. Da es sich um benachbarte Ganzzahlen handelt, können wir die Dinge beschleunigen, indem wir DO REPEAT wie unten gezeigt verwenden.
wiederholen Sie #vals = 2 bis 5 / #vars = region_2 bis region_5.
recode region (#vals = 1)(lo bis hi = 0) in #vars.
Ende wiederholen drucken.
* Wenden Sie variable Etiketten auf neue Variablen.
variable Beschriftungen
region_2 ‚Region = Osten‘
region_3 ‚Region = Süden‘
region_4 ‚Region = Westen‘
region_5 ‚Region = Top 4 Stadt‘.
* Schnelle Überprüfung.
Kreuztabellen Region von region_2 bis region_5.
Eine sorgfältige Prüfung der resultierenden Tabellen bestätigt, dass alle Ergebnisse korrekt sind.
Beispiel III – String-Variable mit Konvertierung
Leider funktionieren unsere ersten 2 Methoden nicht für String-Variablen wie jtype – kurz für „job type“). Die einfachste Lösung besteht darin, sie in eine numerische Variable zu konvertieren, wie in SPSS Convert String to Numeric Variable . Die folgende Syntax verwendet AUTORECODE, um die Arbeit zu erledigen.
autorecode jtype
/in njtype.
*Ergebnis prüfen.
Frequenzen njtyp.
*Setzen Sie fehlende Werte.
fehlende Werte njtype (1,2).
*Ergebnis erneut prüfen.
Frequenzen njtyp.
Result

Da njtype – kurz für „numeric job type“ – eine numerische Variable ist, können wir jetzt Methode I oder Methode II verwenden, um sie in Dummy-Variablen aufzuteilen.
Beispiel IV – String-Variable ohne Konvertierung
Das Konvertieren von String-Variablen in numerische Variablen ist die einfache Erstellung von Dummy-Variablen für sie. Ohne diese Konvertierung ist der Vorgang umständlich, da SPSS fehlende Werte für Zeichenfolgenvariablen nicht ordnungsgemäß behandelt. Die folgende Syntax erledigt die Arbeit jedoch korrekt.
Frequenzen jtype.
*Chance ‚(Unbekannt)‘ in ‚NA‘.
recode jtype (‚(Unbekannt)‘ = ‚NA‘).
* Set Benutzer fehlende Werte.
fehlende Werte jtype („,’NA‘).
*Reinspect Frequenzen.
Frequenzen jtype.
* Erstellen Sie Dummy-Variablen für String-Variable.
wenn(nicht fehlt(jtype)) jtype_1 = (jtype = ‚ES‘).
wenn(nicht fehlt(jtype)) jtype_2 = (jtype = ‚Management‘).
wenn(nicht fehlt(jtype)) jtype_3 = (jtype = ‚Sales‘).
wenn(nicht fehlt(jtype)) jtype_4 = (jtype = ‚Staff‘).
* Wenden Sie variable Etiketten auf Dummy-Variablen.
Variable Etiketten
jtype_1 ‚Job-Typ = IT‘
jtype_2 ‚Job-Typ = Management‘
jtype_3 ‚Job-Typ = Vertrieb‘
jtype_4 ‚Job-Typ = Personal‘.
*Überprüfen Sie die Ergebnisse.
Kreuztabellen jtype von jtype_1 bis jtype_4.
Abschließende Anmerkungen
Das Erstellen von Dummy-Variablen für numerische Variablen kann schnell und einfach erfolgen. Das Festlegen der richtigen Variablenbeschriftungen erfordert jedoch immer ein wenig Arbeit. String-Variablen erfordern einige zusätzliche Schritte, sind aber auch ziemlich machbar.
Trotzdem ist die einfachste Option unser SPSS Create Dummy Variables Tool, da es sich perfekt um alles kümmert.